10万数据点可视化:Echarts性能优化实战
从卡顿到流畅,我的Echarts性能优化三部曲。
最近在工作中遇到了一个颇具挑战的需求,需要在Web页面上通过Echarts图表渲染超过10万条点位数据。对于前端开发来说,大数据量的可视化渲染一直是个棘手的问题,尤其是当数据量达到10万级别时,不仅浏览器请求响应速度变慢,浏览器的渲染性能瓶颈会变得非常明显;因此,本文我们就看下如果在工作中遇到这种场景,应该如何处理。
首先介绍一下实际的场景,我们团队最近接到一个物联网设备数据分析需求:业务方需要查看特定设备一段时间范围内的运行状态趋势。这看起来似乎是个简单的折线图需求,但当我们深入了解数据规模时,发现了巨大的挑战。
首先是业务方要求不限制时间范围,例如可以跨数年的范围,从2021年到2025年;这对我们前后端来说,意味着查询和渲染数据量会非常庞大,因为设备采集一般都是按照固定的时间频率采集的;比如如果设备每隔15分钟就会采集发送一次数据,一天的数据量就是24小时 × (60分钟/15分钟) = 96个数据点/天,如果查询4年的数据就是4年* 365天* 96个数据点 = 14余万条数据。
业务人员给我们的需求很明确:”我们需要在这张图上看到四年的完整趋势,能够快速发现异常波动,并且可以随意缩放查看任意时间段的细节”。他们补充道:”之前试过按天聚合的数据,但那样会丢失很多重要信息。比如设备在某个具体时间点的瞬时异常,在日度数据中就看不出来了。”
我们最初的尝试非常直接,一次性加载所有的数据,然后通过Echarts渲染。
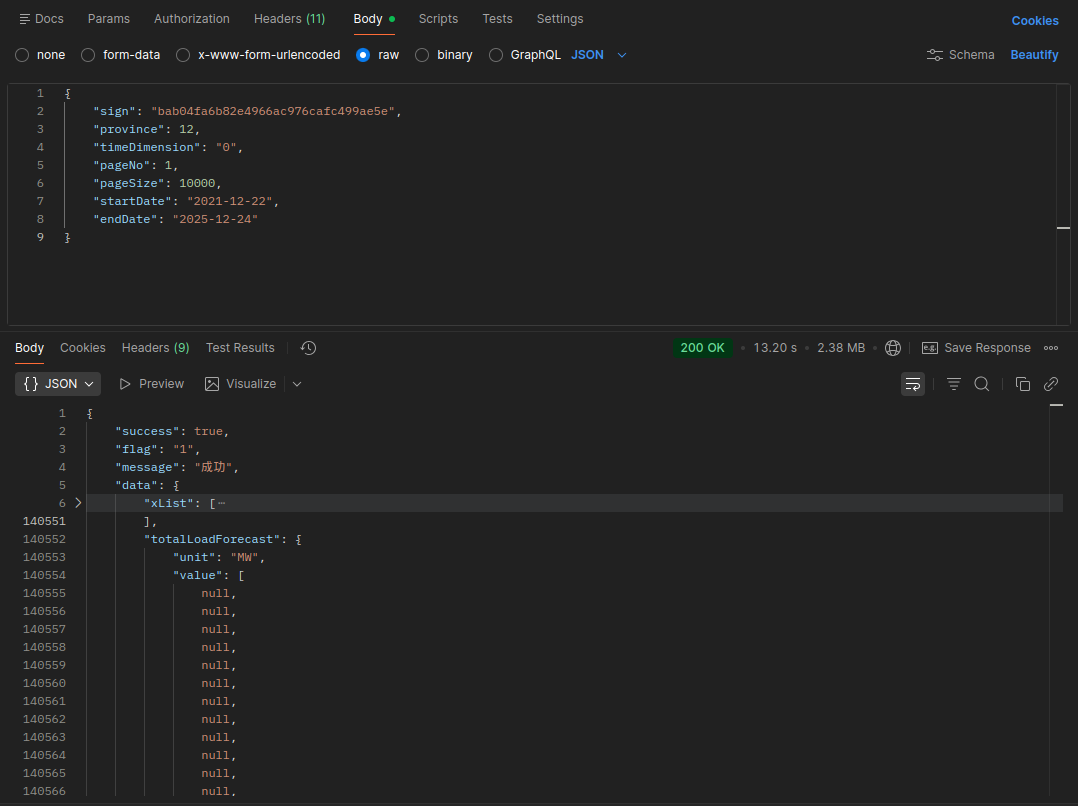
但是请求接口的时间就达到了14秒,数据响应时浏览器内存占用激增,非常容易崩溃卡死,完全没有用户体验可言。
数据分割:化整为零的策略
于是,根据业务需求,我们首先尝试数据分割,将数据按天维度进行分割,然后分别请求数据;下面是分割的核心函数:
1 | |
在处理时,我们会先校验参数格式并计算总天数,若总天数未超过最大分割天数,则将直接返回该日期区间,不再进行分割处理。
1 | |
然后通过Math.ceil将数字向上舍入到最接近的整数,得到numIntervals,也就是我们区间的数量。此外在separateDate返回的数据每个分片中,包含了segmentStartDay和segmentEndDay,对应了时间区间的开始和结束的天数,方便后续的数据合并处理。
这里separateDate函数是我们整个优化方案的核心基础,它将长时间跨度的数据请求分解为多个可管理的子请求;startDate和endDate接收日历📅组件传入的用户选择的开始和结束日期;num参数默认设置为180天,这个值基于我们后端响应效率和速度的最优分段时长,如果单个时间跨度太长,则达不到分段的效果,而如果太短,则分段数量过多,请求次数太频繁。
正是基于separateDate函数分割出的这些独立、合规的日期区间,我们后续的所有优化操作才得以展开;接下来,每一个子区间的数据会进行独立的处理和加载,从而将原本庞大而笨重的单次请求,转化为一次次高效、可管理的并行任务流。
WebWorker:开辟“第二战线”
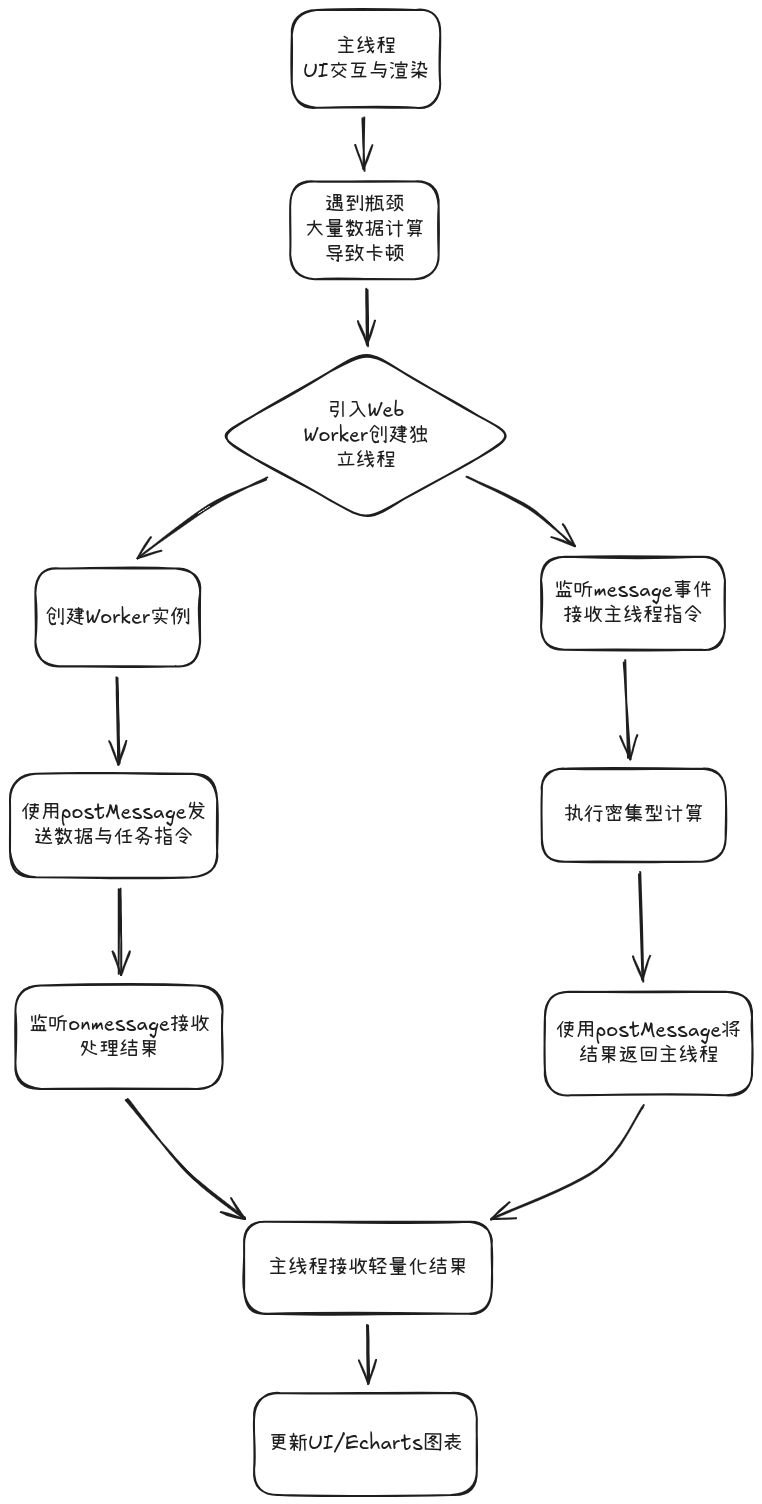
在上一节,我们实现了数据的分割,成功将14万+的数据请求分解为多个小请求;但是即使数据分片了,每一分片数据量仍然可能很大(最多180天×96个点/天=17280个点);如果直接在主线程中处理这些数据,仍然会导致UI卡顿。这时候,Web Worker就派上用场了。
Web Worker是HTML5提供的API,允许在浏览器后台运行JavaScript脚本,与主线程并行执行。这意味着我们可以在Worker线程中执行繁重的数据处理任务,而不会阻塞用户界面;如果说主线程是“前台服务员”,既要响应客人(用户)的点击,又要去后厨炒菜(计算),那么Web Worker就是雇来的“专职后厨”;它有以下几个特点:
- 独立线程:运行在独立的线程中,与主线程并行
- 无DOM访问权限:不能直接操作DOM或访问window对象
- 通过消息通信:与主线程通过postMessage和onmessage通信
- 生命周期独立:关闭标签页或Worker脚本执行完毕才会终止
首先,我们需要创建一个专门处理数据的Worker文件data-processor.worker.js:
1 | |
这里我们定义了一个专用Worker线程,负责执行所有阻塞型的计算任务,负责对数据进行一些耗时的处理,例如原始数据清洗、复杂指标计算等等,并返回处理后的数据;主线程则专注于UI交互与流畅渲染,仅在需要时(分割数据返回)向Worker派发任务并异步接收其返回的、可直接用于图表(如ECharts)的轻量化结果。
1 | |
我们将前面分割好的数据区间,分发为并发的数据请求进行加载。待数据返回后,主线程会实例化一个Worker线程,并通过postMessage函数,将原始数据调度至Worker进行后续处理。
这里还涉及一个数据返回后拼接的问题,我们在循环调用loadEchartData请求数据时,由于是异步返回,分片数据返回的时候,数据会乱序返回,因此不能直接通过数组的push来添加数据。
我们在全局定义x轴和y轴两个数组,在页面初始化的时候,根据业务需求,提前预估计算出数组的长度,并使用默认数据进行填充:
1 | |
当响应数据返回后,我们只需要将数据添加到对应的位置即可:
1 | |
Echarts渲染优化:让大数据飞起来
至此,我们已经通过分割、处理与加载的优化,为海量数据的渲染搭建了一条高效的前置管线。。然而,当数据最终抵达浏览器并准备在ECharts中绘制时,性能的“最终挑战”才真正开始。如何让ECharts“消化”这数万个数据点并保持流畅交互?本节将深入ECharts的渲染层,拆解那些让图表“飞起来”的关键优化策略。
在大数据量的前提下,我们首先需要确保,echarts的渲染器是canvas而不是SVG,因为SVG图像在处理复杂图形时可能会导致性能问题,因此确保你的图表使用canvas进行渲染:
1 | |
降采样策略
什么是数据采样?数据采样是ECharts中处理大数据量的优化技术,当图表需要展示的数据点过多时(通常超过几千个点),浏览器渲染性能会显著下降。采样算法可以在保持图表大致趋势不变的前提下,减少实际渲染的数据点数。
例如,通过对一万个原始数据点进行分层抽样,我们将渲染节点的数量直接从10,000个缩减至1,000个。这一优化直接带来了渲染性能的激增,帧率得到显著提升。Echarts提供了多种数据采样算法,包括如下:
- sum:取过滤点的和
- average:取过滤点的平均值
- min: 取过滤点的最小值
- max: 取过滤点最大的值
- minmax:取过滤点绝对值的最大极值 (从 v5.5.0 开始支持)
- lttb:采用
Largest-Triangle-Three-Bucket算法,可以最大程度保证采样后线条的趋势,形状和极值。
使用时,通过配置series的sampling属性,指定数据采样算法:
1 | |
我们对柱状图进行lttb算法采样后,效果如下,我们能够明显看到柱子的密度有些稀疏:
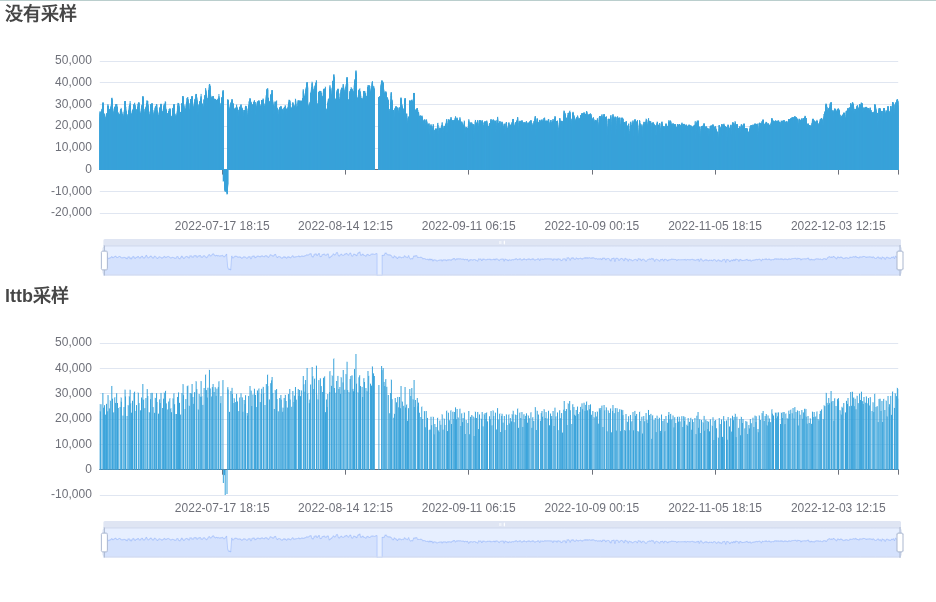
需要注意的是,数据经过采样后,数据点会减少,采样会丢失细节,因此不适合需要精确值的场景;同时由于数据点的减少,一些图表的交互功能,如tooltip,也会受到影响。
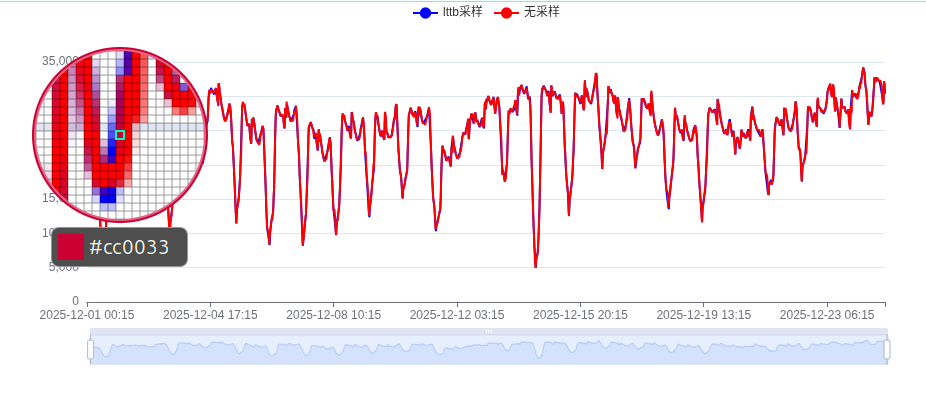
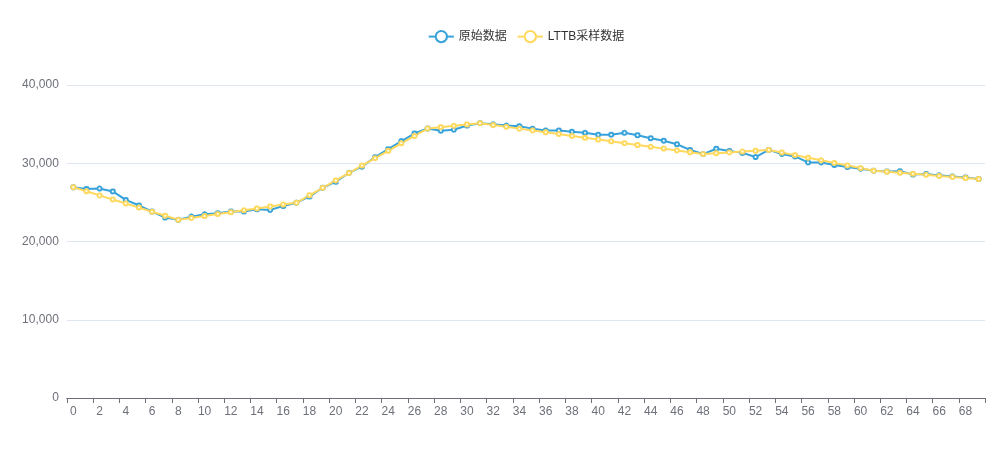
针对折线图,我们也应用了lttb算法进行下采样。从如下效果图中可以观察到,算法在大幅减少数据点的同时,仍保持了原始曲线的核心趋势与形状,整体还原效果非常好。其主要误差出现在变化剧烈的边界区域或极值点附近,导致局部拟合不够平滑。
相较之下,在之前柱状图的测试中,lttb算法因会改变离散柱的分布位置而导致信息失真,因此它更适用于折线图这类强连续性的序列数据可视化。
lttb算法原理
鉴于LTTB算法在降采样中表现出的出色效果,我们有必要深入探究其核心实现原理。作为ECharts等主流可视化库采用的关键算法,其核心步骤是将数据点分组为多个连续的“桶”,并在每个桶内仅筛选一个最具代表性的点。那么,这个代表点是如何被选定的?要回答这个问题,关键在于理解其“最大三角形面积”的筛选准则。
1 | |
我们第一个桶A的点选择初始位置的点,当我们开始选取下一个桶B时点时,再下一个桶C的点,我们暂定为这个桶的平均值;这样,我们前后桶的点都确定了,让我们回到桶B点的选择上来;这个时候,我们遍历桶B的所有点,计算ABC三个桶的点形成三角形的面积,并选择面积最大的点作为这个桶的点。
为什么面积大的点就能代表这个桶呢?我们想像一下,如果B点靠近了AC连线上,那么B点几乎就没有提供了新的信息了。
1 | |
但是如果B点远离AC连线,那么B点就提供了新的信息,那么B点就可以代表这个桶的点。
1 | |
当我们已知二维平面上上三个点的坐标,利用初中的知识就能推导三角形的面积为:
三角形面积 = 0.5 × |AB × AC| = 0.5 × |(x2-x1)(y3-y1) - (x3-x1)(y2-y1)|
下面是一个简单的推导过程:
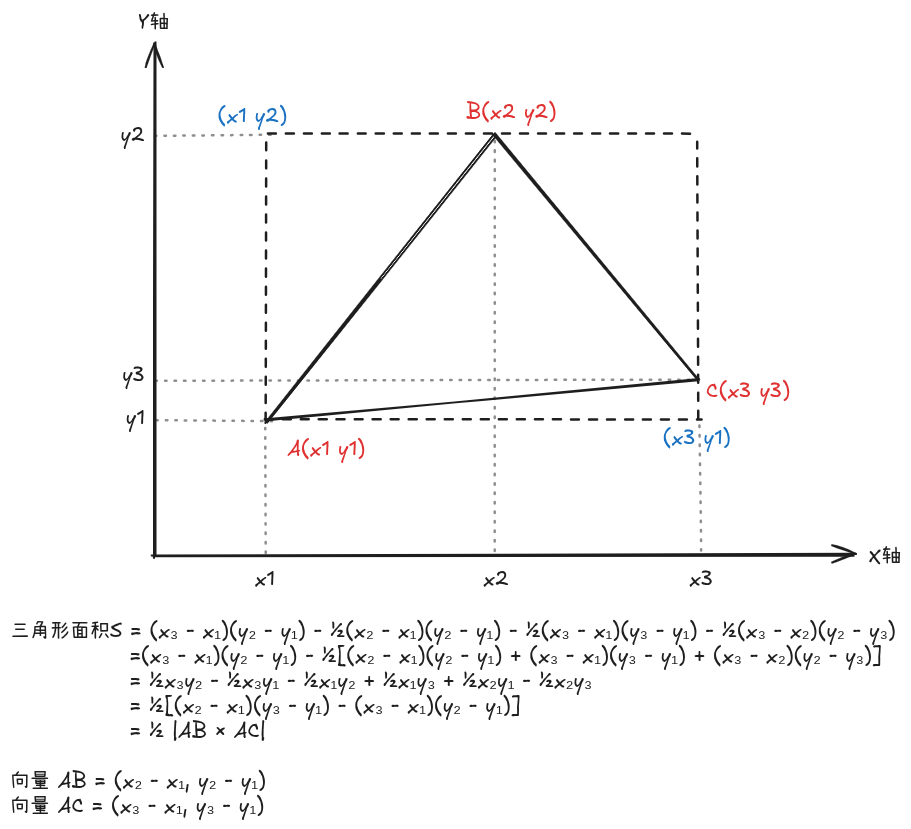
我们访问Echarts仓库中查看源码,发现lttb算法代码在src/data/DataStore.ts的lttbDownSample函数中实现;有了上面理论的支撑,我们下面就来好好的拆解拆解这个函数:
1 | |
首先上面的代码中,我们首先获取数据点的总数,并计算每个桶的大小;这里传入的valueDimension代表值的维度,如果直接传入数据列表,会导致内存占用过高,因此这里的做法是传入数据维度,通过维度来获取数据,从而提高性能。
1 | |
然后我们开始遍历数据点,我们发现i是从1开始的,因为我们默认第一个点就是第一个桶的选择点;接着,在当前桶遍历下,我们先要计算出下一个桶C的平均点(avgX, avgY)。
1 | |
然后,我们开始遍历下一个C桶中的每一个数据点,并计算出下一个桶的平均值。
1 | |
紧接着,我们为当前桶B点的遍历准备一下数据,frameStart和frameEnd是当前桶B的边界,pointAX和pointAY是上一个桶A的坐标。
我们发现这里的pointAX取得是上一个桶最后一个点的坐标i - 1,而不是每次都将上一个桶的选择点存起来使用,这其实是Echarts为了性能优化,牺牲了一点精度,减少变量跟踪。
1 | |
最后这个代码是整个算法的核心代码,也是最精妙的地方;基于之前桶的循环,我们在当前桶内,遍历桶中每个数据点,rawIndex和y表示当前点的坐标;而这里的area就是我们上面介绍的三角形的计算公式,经过之前对于桶A、桶B、桶C的点准备,相信这里的area计算相信大家都能够理解了;最后如果area超出了记录的最大面积maxArea,则将当前点加入到新的采样数据中进行数据留存。
纸上得来终觉浅,算法的精妙,非得亲手试一下不可。为此,笔者写了一个简单的页面来演示LTTB算法的实际效果,默认设置采样率rate为0.1,同时对折线图数据进行采样对比,就能看到和原始数据之间的细微差异:
dataZoom分块渲染
在处理海量数据时,启用dataZoom组件是实现性能跃升的核心策略之一。它将渲染模式从一次性承载全量数据,转变为动态的窗口化渲染。初始化时仅加载视口范围内的数据,随着用户滚动或缩放再动态加载其他部分。这种方式将渲染压力分散到多次轻量级操作中,从根本上避免了单次渲染卡顿,大幅提升了交互响应速度。
1 | |
然而,这里存在一个状态冲突问题,每次从接口获取新数据并重渲染图表时,dataZoom都会被强制重置到初始的[0, 20]区间。如果用户在之前已经通过拖拽缩放浏览了其他数据区域,这个行为就会破坏其探索状态,导致用户体验割裂。
第一种常规的解决方案是,我们在核心的图表渲染函数renderChart中引入一个守卫参数isInitial。只有当 isInitial 为 true(例如初次渲染时),才设置dataZoom的区间。在常规的数据更新渲染中,则保留用户当前交互状态,仅刷新数据而不触动缩放组件。
另一种解决方案是,在setOption时,使用replaceMerge参数,告诉ECharts只替换指定的组件,其他组件(如 dataZoom)保持不变:
1 | |
这样即使多次setOption也不会重置dataZoom的区间。
大数据模式与渐进式渲染
经常查看Echarts官方文档的小伙伴,相信都看到过large和progressive等属性,但是什么情况下需要用到large和progressive呢?相信很多小伙伴都一头雾水,这一节,我们就来好好说道说道。
large属性是ECharts为海量数据渲染设计的专用性能优化开关,通常指数据量在数万到数百万级别; 当你的数据量预计达到此规模时,开启此选项将直接调用底层优化算法,从而获得显著的渲染性能提升,下面我们通过表格实际感受一下10w+级的实测对比数据:
| 指标 | 未开启 large | 开启 large |
|---|---|---|
| FPS | 3-10 | 51-60 |
| MS(渲染一帧所需的毫秒数) | 179-246 | 17-28 |
| 内存占用(MB) | 277-305 | 53-59 |
| 交互响应 | 卡顿明显 | 基本流畅 |
largeThreshold是与large属性配合使用的阈值参数,它定义了启用大规模优化模式的数据量下限。当且仅当数据项数超过此阈值时,优化绘制逻辑才会生效;反之,系统将使用标准渲染流程,避免不必要的开销;大多数情况下无需手动调整。
1 | |
需要注意的是,不是每种类型的图表都支持large和largeThreshold属性的,目前仅有bar和scatter图表支持。
需要指出的是,在large模式下,Echarts出于性能优化的考虑,无法为单个数据点设置独立样式,所有数据点将共享同一套样式配置;比如下面代码中,我们为最后一个数据项单独设置的itemStyle就不会生效:
1 | |
progressive属性本质是开启“分片渲染”模式,用以解决超大规模图形元素(数千至千万级)造成的浏览器瞬时阻塞风险。启用后,ECharts会将庞大的数据集自动分割为多个小块(chunk),在多个动画帧中依次渲染,从而将一次性的沉重负载分散为平缓的增量任务。我们在散点图上实测此功能,可以清晰地观察到数万个数据点如同雨点般在画布上逐渐浮现:
1 | |

progressive属性控制渐进式渲染的 “粒度”,其值为每一帧渲染的图形数量,默认值为400,设为0,则相当于关闭此功能;而progressiveThreshold属性则设定了启用此功能的 “门槛”。仅当图形总数超过此阈值时,progressive的配置才会生效,开始分帧渲染。
开启large默认会开启progressive渐进渲染。
总结
到这里,我的Echarts性能优化三部曲总算告一段落了;当看到业务方在流畅渲染着四年设备数据的图表前露出满意笑容时,我就知道,这次优化的努力没有白费。
我们首先构建了数据分割机制。当用户选择跨年度的查询范围时,系统不再傻乎乎地一次性请求所有数据,而是像一位细心的图书管理员,将厚厚的历史档案按时间章节分册取出。这个简单的策略,将原本长达14秒的接口响应时间分解为多个毫秒级的快速请求,从根本上避免了浏览器的内存过载和界面冻结。
接着我们引入了Web Worker并行计算。这相当于给数据处理流程雇佣了一位专属的后台助理。所有耗时的数据清洗、格式转换和指标计算都被转移到独立线程中执行,主线程得以保持轻盈,继续流畅地响应用户的每一次点击和滑动。这种前后台分工协作的模式,让数据处理从“阻塞性任务”变成了“后台服务”。
最后,我们在Echarts渲染层施展了一系列组合优化。通过LTTB采样算法,我们在保留数据趋势灵魂的同时,巧妙地减少了渲染负担;借助dataZoom的视口动态加载,我们实现了“所见即所得”的按需渲染;而启用large和progressive模式,则是给图表引擎装上了涡轮增压,让万级数据点的绘制也能达到60帧的流畅体验。
现在回顾这段旅程,让我深刻认识到数据可视化的本质——它不仅仅是数据的图形化呈现,更是信息与洞察的艺术表达。好了,我的优化之旅暂告一段落,但技术的探索永无止境。那么,你的项目中是否也藏着需要被驯服的“数据巨兽”呢?带上这份实战心得,开始你的优化之旅吧!
本网所有内容文字和图片,版权均属谢小飞所有,任何媒体、网站或个人未经本网协议授权不得转载、链接、转贴或以其他方式复制发布/发表。如需转载请关注公众号【前端壹读】后回复【转载】。