Linux下Stable Diffusion安装使用教程
在日常工作中,Stable Diffusion可以为设计师提供脑洞大开的创意素材以及处理图像修复、提高图像分辨率、修改图像风格等任务,辅助实现创意落地。本文从安装教程入手,记录下在Linux环境下,如何安装Stable Diffusion,以及模型插件的安装。
介绍
Stable Diffusion是一种通过模拟扩散过程,将噪声图像逐渐转化为目标图像的文生图模型,具有较强的稳定性和可控性,可以将文本信息自动转换成高质量、高分辨率且视觉效果良好、多样化的图像。
安装
首先需要安装python3的环境,SD(Stable Diffusion的简称,下面都用SD进行指代)推荐的版本是python3.10,这里看下笔者的电脑环境:
1 | |
然后我们执行git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git,将项目克隆到本地:
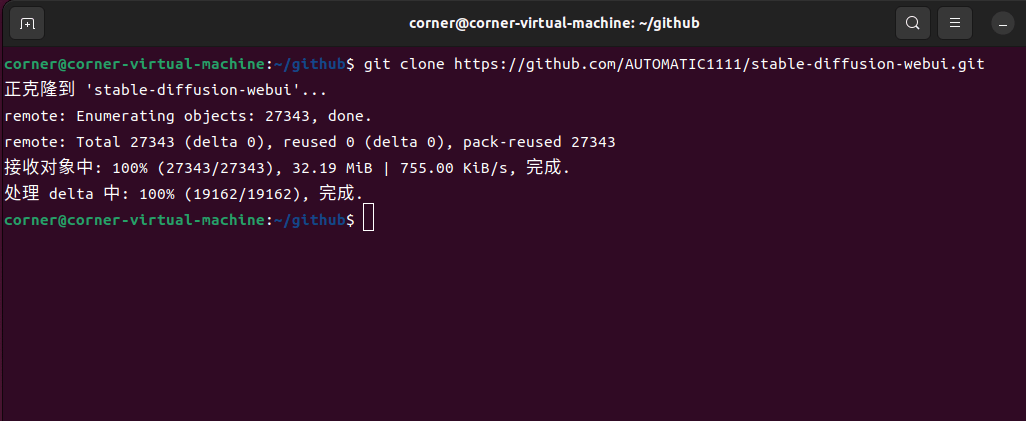
项目克隆下来后,我们需要切换到SD项目里面去安装依赖:
1 | |
在安装过程中我们会看到有下面这种报错的情况,一般都是某个依赖安装不上,我们可以查看具体的报错信息,然后尝试手动安装:
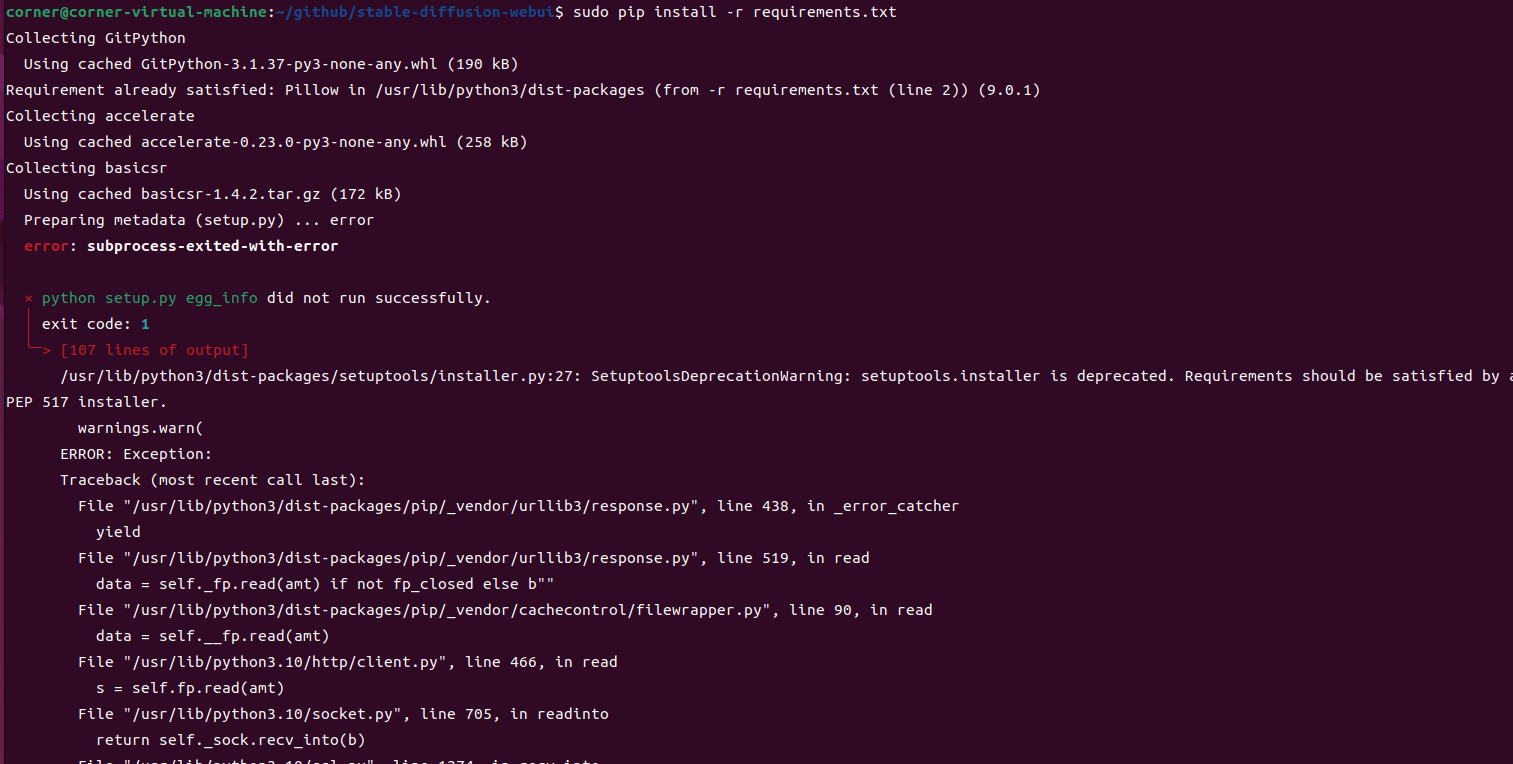
比如pytorch,下载安装比较慢,会导致报错,我们可以尝试下面的命令进行手动安装:
1 | |
pytorch分为CPU版本和GPU版本,其中GPU版本的安装需要先安装CUDA,可以参考CUDA和cuDNN安装教程。所有依赖安装完成后,如果我们直接执行启动命令:
1 | |
有可能会如下报错:
1 | |
我们需要使用python创建一个虚拟环境:
1 | |
看到以下提示,就说明启动成功了,我们在浏览器打开http://localhost:7860:
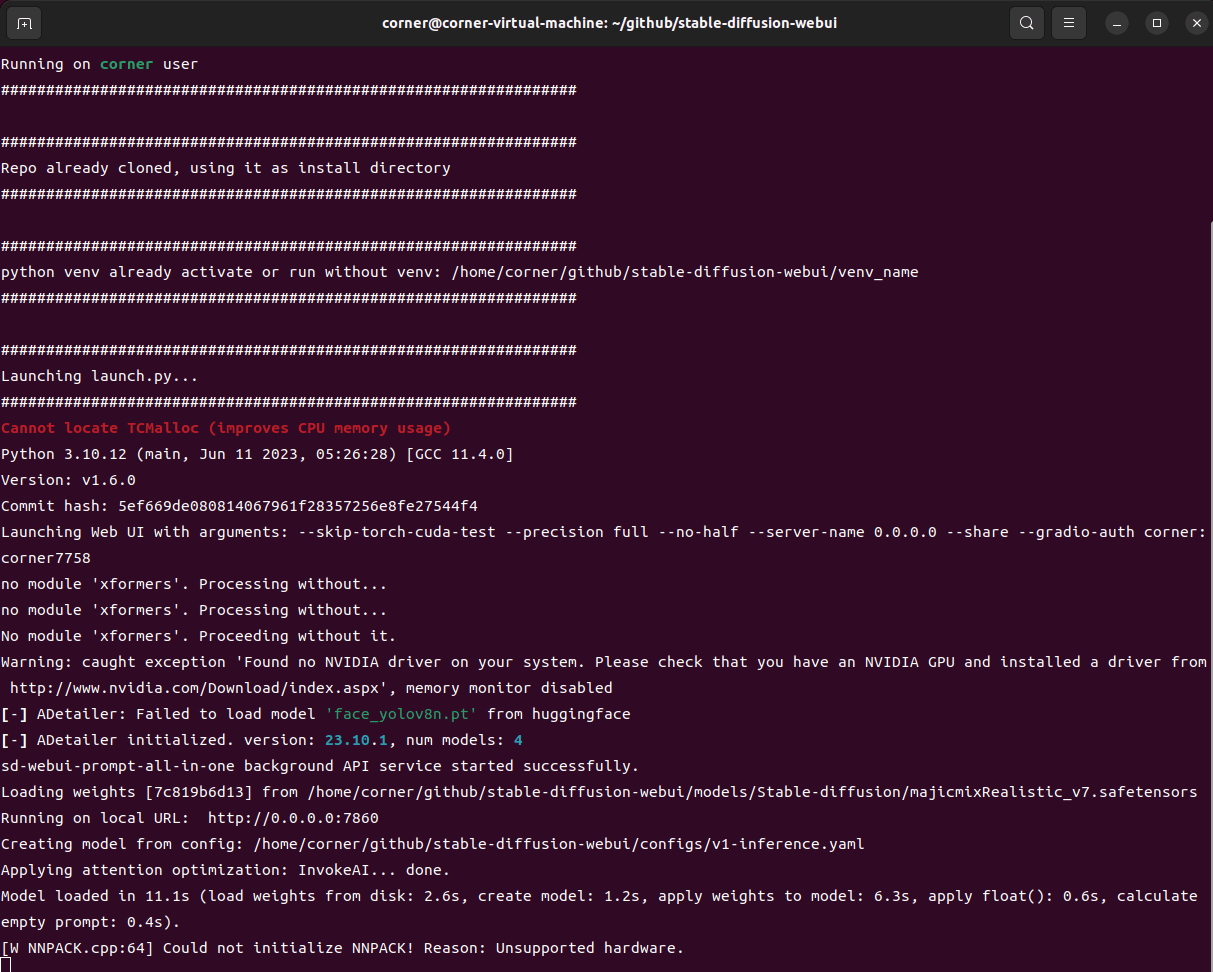
如果我们启动时想要加一些参数,比如,启动时不想要cuda的校验,打开webui.sh,添加以下命令行参数:
1 | |
这样启动后我们服务器只能通过localhost访问,如果我们想要服务器可以通过远程访问,添加参数:
1 | |
我们还可以为SD设置访问密码的限制:
1 | |
Anaconda安装启动
由于Linux系统自带的Python版本可能不是我们想要的(SD推荐的版本是3.10.6),因此我们还可以很方便的通过Anaconda创建一个虚拟环境,然后再启动SD,免去重新安装python的烦恼;首先我们从清华镜像下载安装Anaconda:
1 | |
安装完成后我们就可以使用conda命令创建一个虚拟环境了:
1 | |
通过虚拟环境,我们还是执行webui.sh,等待一系列的包安装后,就可以启动我们的SD了;我们还可以使用nohup命令,把webui.sh放到后台执行:
1 | |
插件扩展的安装
SD还有一些不错的插件和扩展可以配合使用。
Easynegative
反向提示词(Negative prompt),就是我们不想出现什么的描述,例如一些容易变形的身体部位的描述等。EasyNegative是目前使用率极高的一款反向提示词embedding模型,可以有效提升画面的精细度,避免模糊、灰色调、面部扭曲等情况,适合动漫风大模型。
它的用法也是最简单的,下载easynegative.safetensors文件,并且放到stable-diffusion-webui/embeddings/目录下,然后在反向输入词中,输入触发关键词easynegative,就可以使用了;除此之外,还有以下一些可以用的Embedding模型:
- Deep Negative_v1_75t:Deep Negative可以提升图像的构图和色彩,减少扭曲的面部、错误的人体结构、颠倒的空间结构等情况的出现,无论是动漫风还是写实风的大模型都适用。
- badhandv4:badhand 是一款专门针对手部进行优化的负面提示词embedding模型,能够在对原画风影响较小的前提下,减少手部残缺、手指数量不对、出现多余手臂的情况,适合动漫风大模型。
我们将Embedding模型放入文件夹后,重启SD,在webui中找到Embedding面板,点击相应的模型就可以使用了。
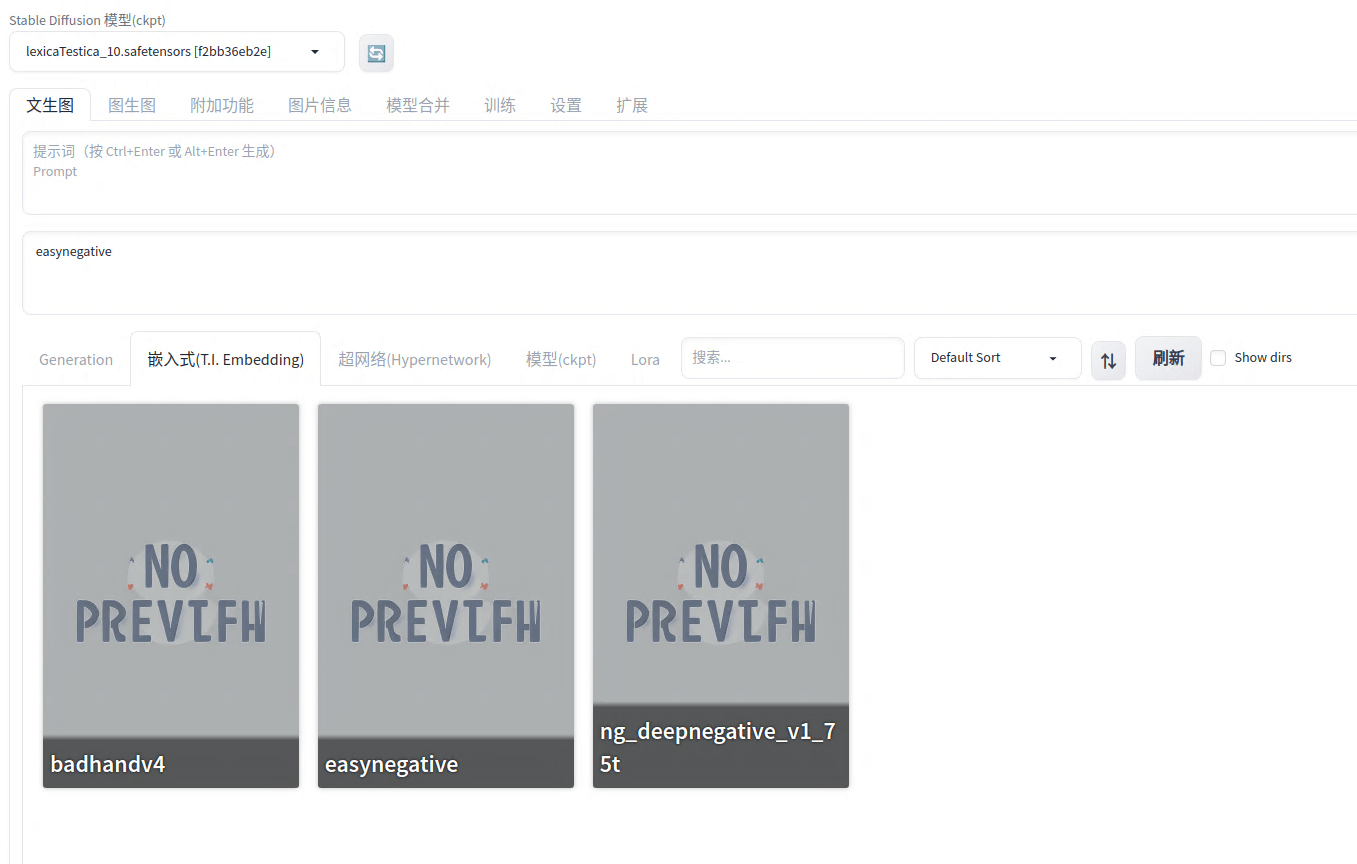
汉化插件
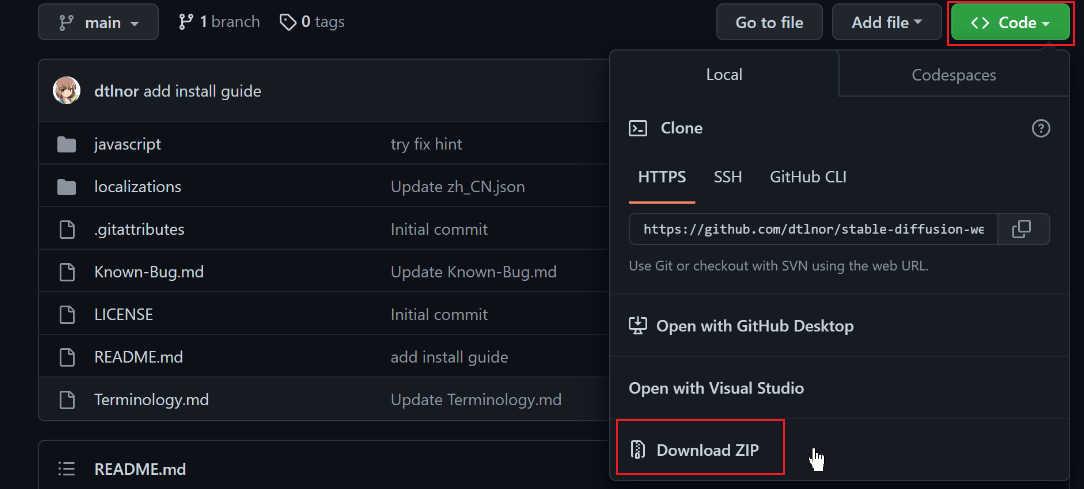
相信全是英文界面的webui肯定没有几个小伙伴有耐心一个个的看下去,因此汉化插件是必备的;官方有好几种安装方式,我们通过最简单的下载zip的方式;打开stable-diffusion-webui-localization-zh_CN,下载zip文件
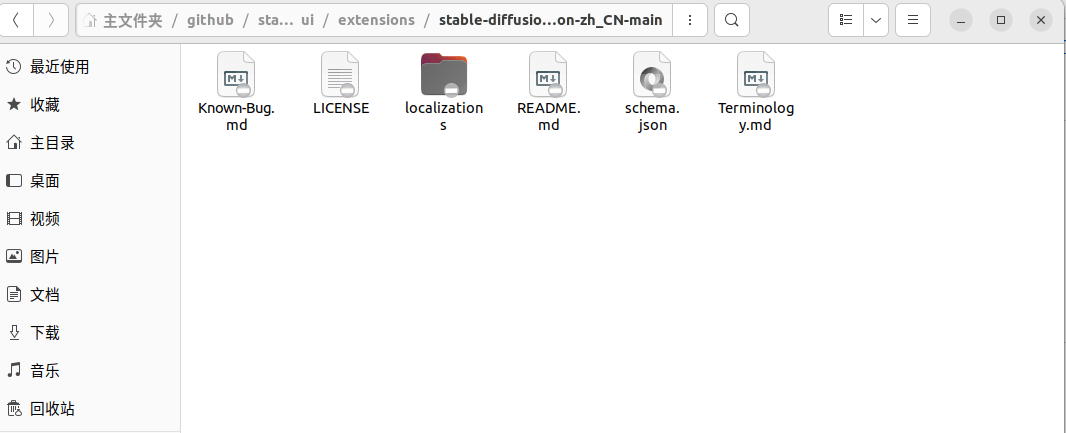
解压zip文件,并把文件夹放到stable-diffusion-webui/extensions/文件夹中,放好之后目录如下:
如果有魔法加持的话,可以直接在根目录执行克隆命令:
1 | |
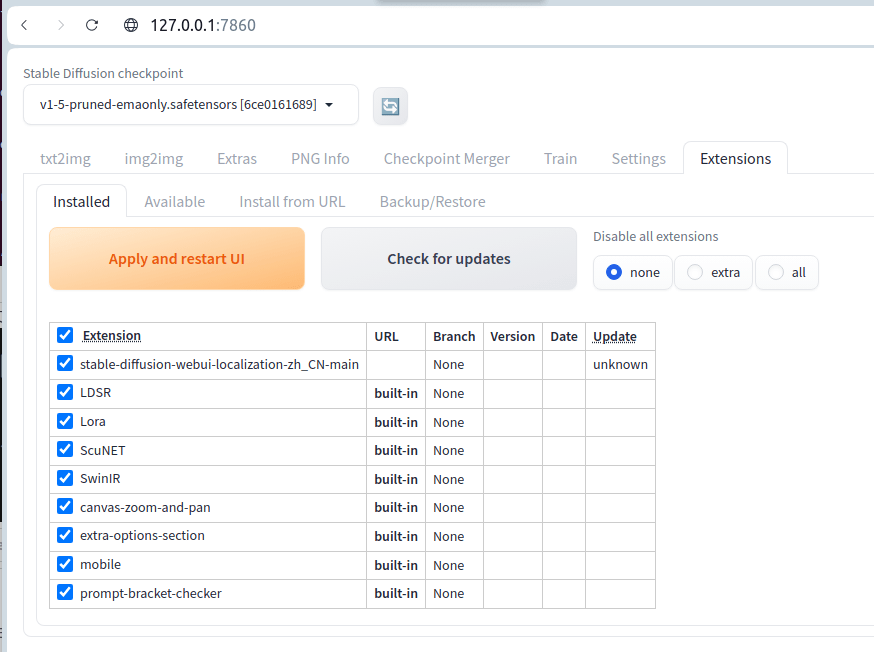
重启webui,点击Extensions => Installed,可以看到我们的插件已经安装;确保已经勾选插件,如果没有,勾选后点击Apply and restart UI按钮启用:
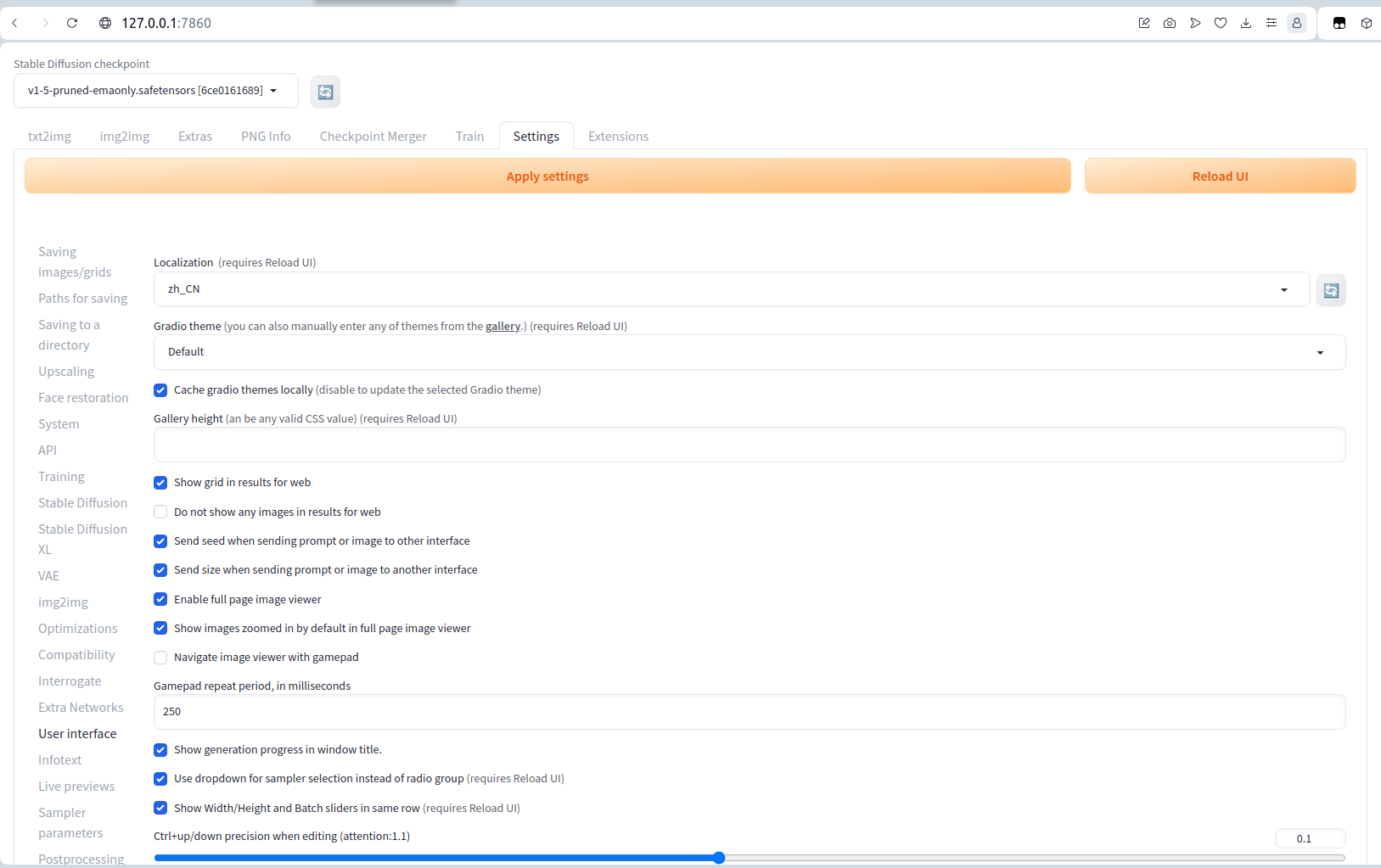
然后就需要切换界面的语言,找到Settings => User interface => Localization选项,在下拉菜单中选中zh_CN,然后点击上面的两个按钮`Apply settings和Reload UI``,等待一段时间后就可以看到我们的界面切换中文了。
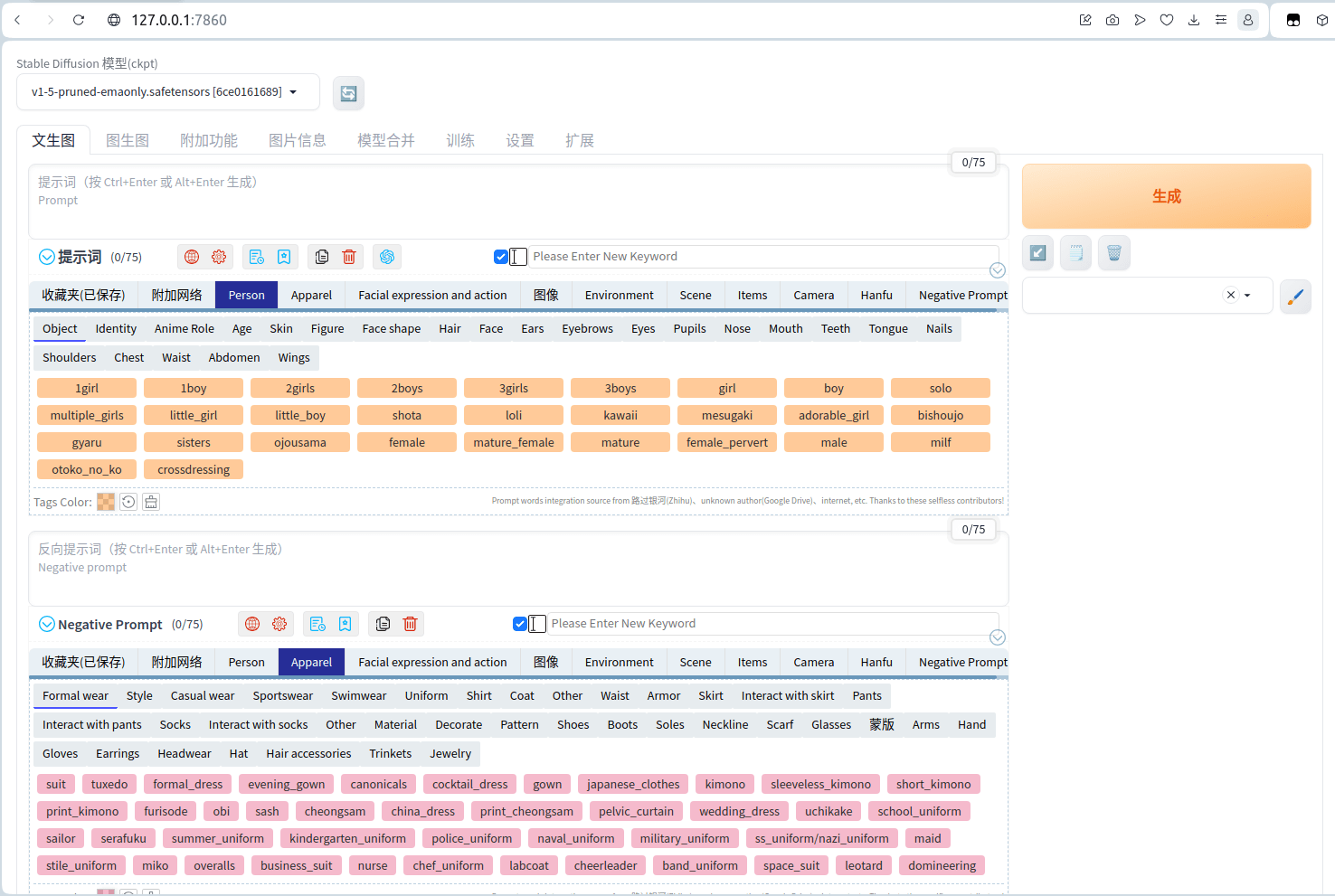
sd-webui-prompt-all-in-one
sd-webui-prompt-all-in-one也可以算是SD的必备实用插件之一了,它的作用在于提高提示词/反向提示词输入框的使用体验。它拥有更直观、强大的输入界面功能,它提供了自动翻译、历史记录和收藏等功能,它支持多种语言,满足不同用户的需求。
它的安装也非常简单,将插件克隆下来到extensions目录即可:
1 | |
重启服务器,我们在界面上看到有各种密密麻麻的提示词,插件就生效了。
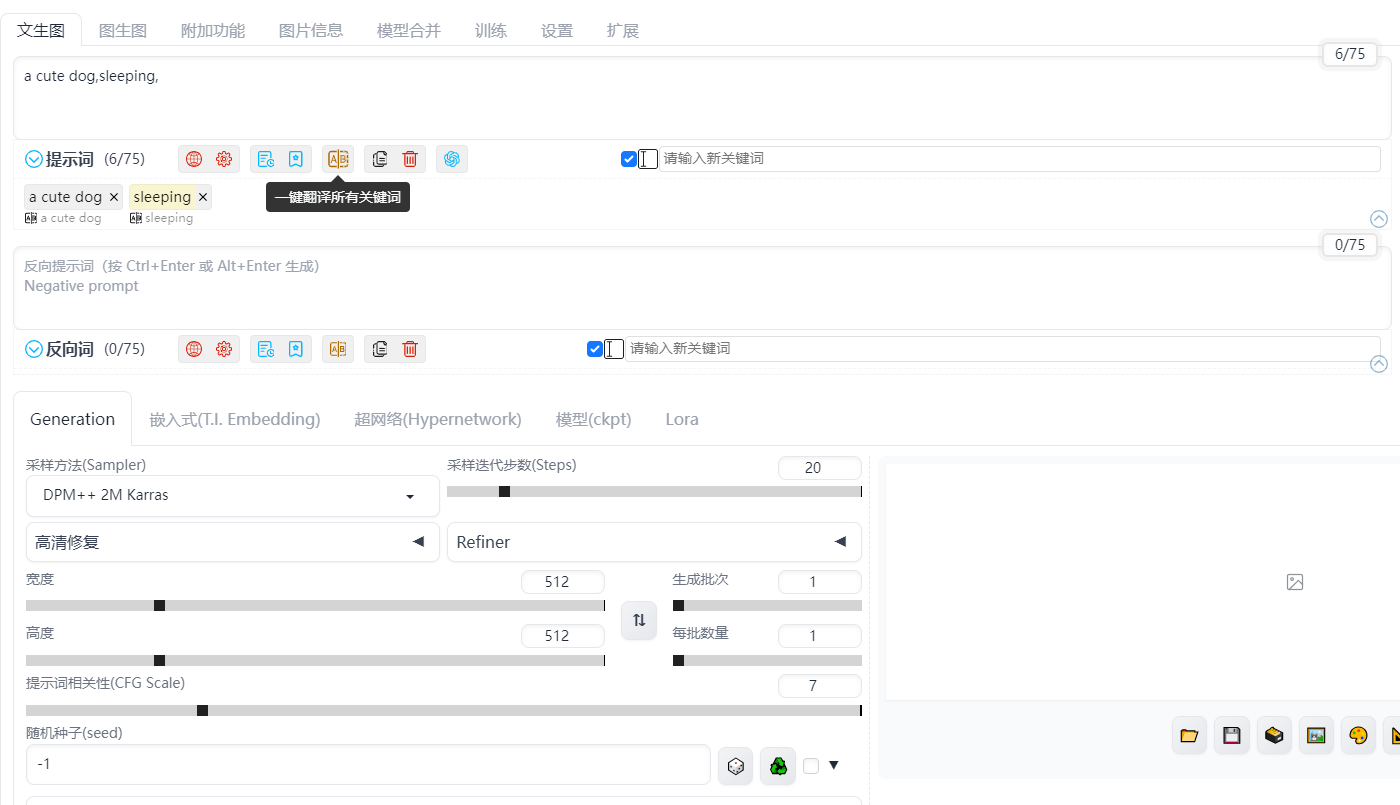
我们来看下插件的主要功能,首先就是实时翻译功能了,由于SD只支持英文,对我们来说,怎么让它知道我们想要画什么图案就不是那么友好了,因此翻译工具是必备的;在插件的输入框中(注意,是插件的输入框,不是SD原始的输入框)输入内容后,插件会自动帮我们翻译。
同时,我们也不需要一个一个的输入翻译,可以在一次性输入完成后,点击一键翻译的按钮,将输入框中的内容统一进行翻译。
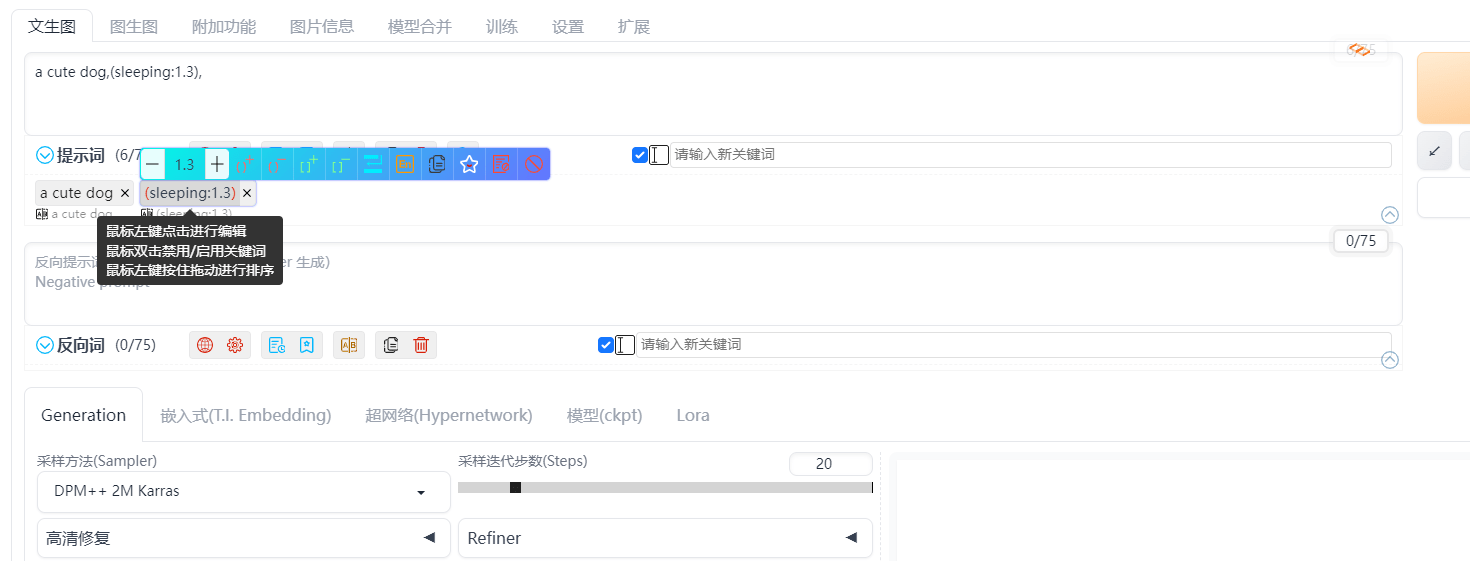
对于密密麻麻的提示词,我们可以在下面可视化的快速调整某一提示词的权重或者顺序,不会因为各种符号问题而烦恼了。
而且在使用一段时间后,肯定积累了一些高频常用的提示词,使用收藏工具,可以把这些词收藏起来,后面使用就很方便了。
Adetailer
adetailer是一款可以修复面部崩坏以及更换脸部标签的插件,操作比较简单,首先我们通过本地命令行来进行安装:
1 | |
安装完成后重启我们的SD进行,打开浏览器后发现文生图的左下方多了一个Adetailer选项,点击展开可以看到有一些参数调整,点击Enable ADetailer的选项就可以启用插件了:
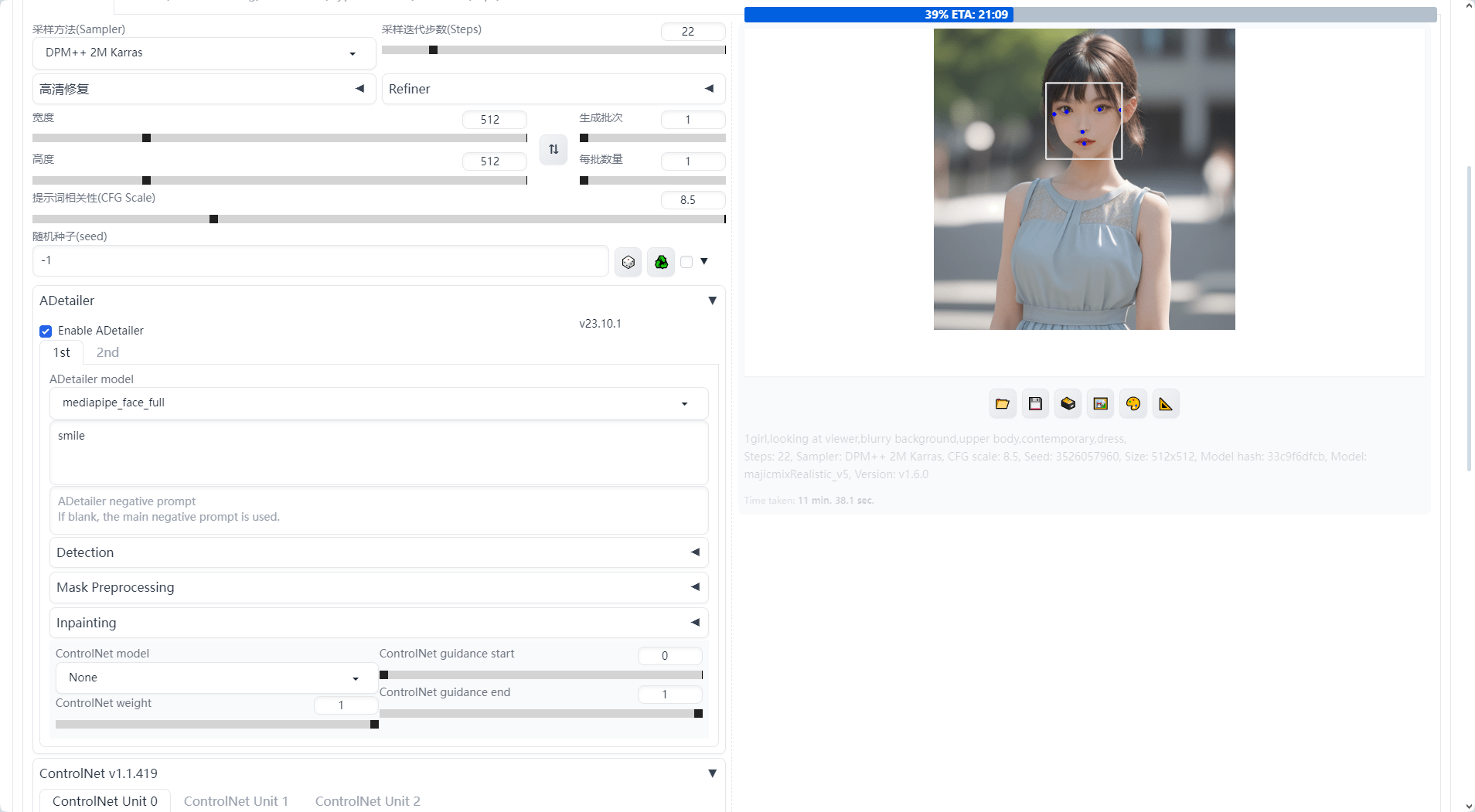
我们选择mediapipe_face_full模型,在下面提示词中,我们可以更改最后生成的面部表情,比如这里我们写smile,可以让生成的人物表情更加的微笑;最后的运行效果,面部对比之前也更加的自然。

ControlNet
我们知道在SD中,想要精确控制物品、人物是比较困难的事,不过通过ControlNet插件,我们可以完成,通过下面命令进行安装:
1 | |
重启后可以在主界面下方看到ControlNet的选项。
OpenPoseEditor
通过OpenPoseEditor插件,我们可以进一步的控制人物的动作
1 | |
一些问题
Cannot locate TCMalloc.
报错信息:
Cannot locate TCMalloc. Do you have tcmalloc or goole-perftool installed on your system? (imporves CPU memory usage)
执行如下命令:
1 | |
Can’t load tokenizer for ‘openai/clip-vit-large-patch14’
报错信息:
OSError: Can’t load tokenizer for ‘openai/clip-vit-large-patch14’. If you were trying to load it from ‘https://huggingface.co/models’, make sure you don’t have a local directory with the same name. Otherwise, make sure ‘openai/clip-vit-large-patch14’ is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
1 | |
参考
模型下载
提示词生成工具
提示词分享社区
本网所有内容文字和图片,版权均属谢小飞所有,任何媒体、网站或个人未经本网协议授权不得转载、链接、转贴或以其他方式复制发布/发表。如需转载请关注公众号【前端壹读】后回复【转载】。