前端抢饭碗系列之Docker容器编排
本文是Docker的第三篇文章,我们将之前Docker中遗漏的一些问题进行深入的探讨,比如设置容器的环境变量、镜像的导入导出等一些常用的功能;然后我们会搭建一个私有的Registry仓库,上传和拉取我们自己的镜像;以及最重要的部分,容器的编排,这次我们不再是单打独斗地操作一个容器了,我要一次打十个容器!开玩笑开玩笑,笔者又不是叶问。最后笔者会分享一些常用的、有趣又实用的镜像,比如私有网盘、爬虫、图床、私有笔记、私有媒体库以及下载工具等等,可以提升我们的日常工作效率,记得看完哦;本文依旧干货满满,新来的小伙伴记得点赞关注哦。
容器的环境变量
我们在启动docker容器的时候,经常需要向容器传递一些参数,以便容器进行一些特殊的配置,比如给mysql传入MYSQL_ROOT_PASSWORD的root用户密码,或者我们想在自己的容器中传入一些数据库的配置等等。
第一种方式也最简单的,也是最常见的,在run容器时使用--env,也就是我们在各个文档中经常见到的简写-e:
1 | |
我们在js代码中可以通过环境变量process.env来获取
1 | |
在python代码中调用os.getenv获取:
1 | |
第二种方式,也是我们在Docker进阶部署中介绍的,通过Dockerfile文件的ENV指令:
1 | |
第三种方式,run容器时,通过--env-file指令加载env文件,首先我们把配置信息放在文件env.list中:
1 | |
启动容器时传入文件,这样我们就不用传入一大堆的-e命令了:
1 | |
经过测试,三种方式的优先级如下:
-e指令
大于>–env-file大于>ENV指令
我们查看容器的环境变量也很简单,通过inspect命令,也可以加上grep过滤想要的字段:
1 | |
也可以解析一下返回内容:
1 | |
镜像与容器的导入导出
有时候我们部署docker容器会遇到问题,比如服务器在内网,不能连接外网的情况(一些具有较高保密性的企业),或者网络下载慢,不通畅;我们就可以编译、导出镜像后在内网服务器导入,就可以实现内网部署。
镜像save和load
镜像的导入我们通常使用docker save和``docker load`命令,save命令将镜像打包成tar文件:
1 | |
导出镜像尽量使用
镜像名:标签的形式,使用镜像id容易出现导入后镜像名出现<none>的情况。
我们还可以将多个镜像打包到一个文件进行导出:
1 | |
使用load命令就可以将导出的镜像包加载进来:
1 | |
save和load的应用场景,就是我们上面说的内网部署的情况;同时如果我们的应用还是使用docker compose编排的多个镜像组合,就可以使用save将用到的多个镜像打包,然后拷贝到客户服务器上使用load载入。
容器export和import
首先我们查看本机的所有容器,使用export命令将容器ID导出成文件:
1 | |
导出到文件后,我们在本地目录可以看到该tar包文件,我们再使用import命令将镜像文件导入进来:
1 | |
导入后的容器文件会成为一个镜像,我们可以为它指定新的名称,如果存在同名镜像,原有的名称会被剥夺,赋给新的镜像。
export和import的应用场景主是要用来制作基础镜像,比如我们从一个ubuntu镜像启动一个容器,然后安装一些软件和进行一些设置后,使用docker export保存为一个基础镜像。然后把这个镜像分发给其他人使用,比如作为基础的开发环境。
总结一下docker save和docker export的区别:
- docker save保存的是镜像(image),docker export保存的是容器(container);
- docker load用来载入镜像包,docker import用来载入容器包,但两者都会恢复为镜像;
- docker load不能对载入的镜像重命名,而docker import可以为镜像指定新名称。
私有仓库
在Docker中,我们执行pull XXX某个镜像的时候,实际上它是从registry.hub.docker.com官方的镜像仓库去拉取的;在实际工作中,我们不会把企业的项目push到公有仓库中管理;所以为了更好的管理,Docker不仅提供了公有仓库,也允许我们搭建私有仓库。
Docker Registry是一个无状态,高度可扩展的服务器端应用程序,它存储并允许您分发Docker映像;我们通过run命令启动:
1 | |
Registry服务默认将上传的镜像保存在容器的/var/lib/registry,我们可以将服务器本地的文件夹挂载到该目录,即可实现保存镜像;通过以下curl我们可以查看服务器是否启动,以及服务器上的镜像。
1 | |
正常情况下,服务器推送镜像到仓库默认使用的是https,但是我们在企业内部使用,这里就不加https;需要在客户端配置可信的仓库地址为http,否则push时会报如下错误:
1 | |
在windows的Docker客户端,我们可以直接修改Desktop的配置,在Setting中选择Docker Engine,添加insecure-registries字段,完成后点击Apply & Restart重启即可:
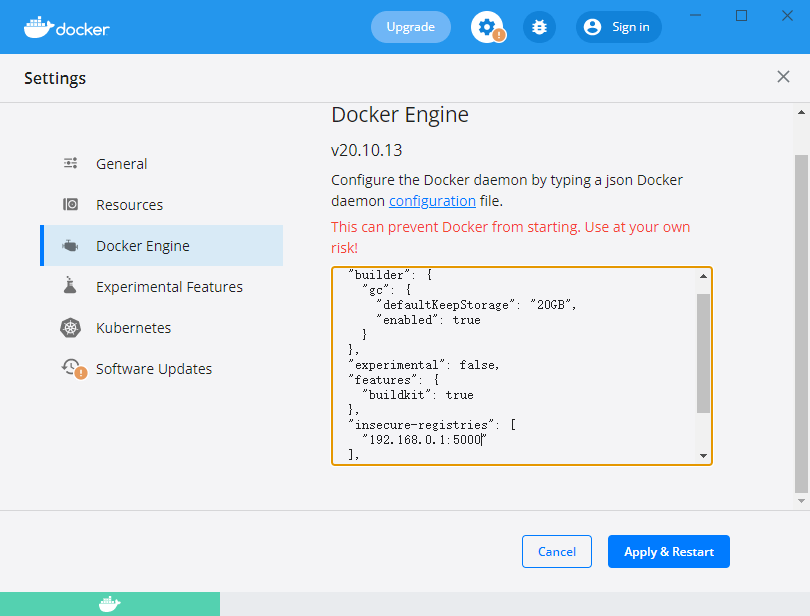
在linux客户端,我们修改/etc/docker/daemon.json文件,我们同样也是加入insecure-registries,然后执行命令sudo service docker restart重启docker:
1 | |
修改该文件必须符合JSON文件规范,否则会启动失败
Registry服务启动后,我们来看下如何推送镜像到仓库中;我们从Docker Hub下载一个ubuntu:18.04镜像,然后将它推送到私有仓库;首先给这个镜像重新打上服务器的标签:
1 | |
使用push命令推送镜像:
1 | |
我们可以在另外一台机器上拉取这个镜像,也可以将本地的192.168.0.1:5000/my-ubuntu:latest和ubuntu:18.04镜像删除后,再次拉取:
1 | |
再次curl查看服务器,我们就能看到该镜像已经在服务器生效了
1 | |
开启认证
我们上面仓库搭建后,所有客户端都可以push、pull,这是我们不希望看到的,我们想要认证的用户才能够访问;将原有容器删除,创建一个保存账号密码的文件:
1 | |
将上面的username和password替换成自己的账号密码,运行容器时我们绑定auth文件夹:
1 | |
服务器开启认证后客户端再pull、push会提示no basic auth credentials,我们需要先进行登录操作:
1 | |
Compose
Docker Compose是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。在前两篇Docker中,我们都是介绍了单个容器的构建和使用方式;在日常开发中我们经常会遇到需要多个容器相互配合使用的情况,比如除了web项目本身,还要数据库支持,nginx负载均衡等等;如果所有容器都通过命令行的方式构建、启动、删除等操作会十分繁琐;就好像你每天下班回到家里,都需要进行开灯、关闭窗帘、打开电视、煮饭等等一系列简单且重复的操作。
Compose的出现就解决了这个问题,它通过定义一个模板文件docker-compose.yml来管理一组相关联的容器,所有容器的配置、环境等都记录到文件中,通过一个命令就可以控制所有的容器;Compose就像智能家居的管家,我们只需要将开灯、关闭窗帘、打开电视、煮饭等操作在App中进行定义,我们下班回到家里只要对着它发出指令:回家啦!,它就会自动帮你把所有的事情做了。

安装卸载
Docker Compose支持Windows、macOS和Linux平台,在Windows和macOS平台我们直接下载安装包安装后自带Compose,直接可以使用,我们通过version查看安装情况:
1 | |
Linux的安装也很简单,直接从官网下载编译好的二进制文件并赋予执行权限即可:
1 | |
nodejs和redis使用
常见的项目就是web网站,包括web应用和数据库(mysql、mongodb或redis),我们尝试一个能够简单记录页面访问次数的web应用。新建一个express项目,编写app.js文件:
1 | |
这里我们连接redis的时候使用了容器名称,而不是ip,下面我们会使用容器名称和静态两种连接方式。再编写我们的Dockerfile,构建镜像:
1 | |
编写docker-compose.yml文件,这是Compose的模板文件,我们用到2个服务:
1 | |
在项目中允许docker-compose up -d就在后台启动了Compose项目,访问8000端口,每次刷新页面,计数就会加1。
命令说明
ps
ps命令,列出所有的容器,以及运行状态和所有端口:
1 | |
如果要查看某个服务的信息,ps命令带上某个服务的名称:
1 | |
logs
logs命令查看服务容器的输出。
1 | |
start
启动已经存在的服务容器。
1 | |
stop
停止已经处于运行状态的容器,但不删除它。通过start可以再次启动这些容器。
1 | |
images
列出Compose文件中包含的镜像。
1 | |
scale
弹性设置服务运行的容器个数,通过service=num;需要去掉在yaml文件指定的端口号,否则会导致端口占用问题
1 | |
build
构建(重新构建)项目中的服务容器。
1 | |
或者单独构建某个服务的容器。
1 | |
down
此命令将会停止up命令所启动的容器,并移除网络。
1 | |
up
此命令将自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作;可以直接通过该命令来启动一个项目。
1 | |
默认情况下,启动的容器都在前台运行,使用-d参数,将会在后台启动并运行所有的容器,一般在生产环境使用。
1 | |
Compose模板文件
Compose通过配置文件docker-compose.yml来管理多个Docker容器,模板文件主要分为3个部分:
- service(服务):在它下面可以定义应用需要的一些服务,每个服务都有自己的名字、使用的镜像、挂载的数据卷、所属的网络、依赖哪些其他服务等等。
- volumes(数据卷):定义数据卷,然后挂载到不同的服务使用。
- networks (应用网络):定义应用名字,使用的网络类型。
下面介绍一些主要指令的使用。
version
yarm文件一般开头就是version字段,version指定了版本信息,关乎docker的兼容性,Compose文件格式有3个版本,分别为1,2.x和3.x。两者的版本要求如下表:
| compose文件格式版本 | docker版本 |
|---|---|
| 3.4 | 17.09.0+ |
| 3.3 | 17.06.0+ |
| 3.2 | 17.04.0+ |
| 3.1 | 1.13.1+ |
| 3.0 | 1.13.0+ |
| 2.3 | 17.06.0+ |
| 2.2 | 1.13.0+ |
| 2.1 | 1.12.0+ |
| 2.0 | 1.10.0+ |
| 1.0 | 1.9.1.+ |
image
从指定的镜像中启动容器,可以是存储仓库、标签以及镜像ID。
build
指定Dockerfile所在文件夹的路径,可以是绝对路径,也可以是相对docker-compose.yml文件的路径
1 | |
如果dockerfile文件名不是默认名,需要指定:
1 | |
使用arg指令指定构建镜像时的变量,这里的var1和var2将被发送到构建环境。
注意:任何environment与args变量同名的env变量(使用块指定)将覆盖该变量。
command
覆盖容器启动后默认执行的命令。
1 | |
links
将指定容器连接到当前连接,可以设置别名,避免ip方式导致的容器重启动态改变的无法连接情况。
1 | |
我们在web容器中使用rd就能访问redis,而不用ip。
external_links
链接到docker-compose.yml外部的容器,甚至并非Compose管理的外部容器。
1 | |
depends_on
解决容器的依赖、启动先后的问题。以下例子中会先启动redis和db再启动web。
1 | |
注意:web服务不会等待redis db「完全启动」之后才启动。
networks
默认情况下,Compose会为我们的应用设置一个网络,服务的每个容器都加入默认网络,并且可以被该网络上的其他容器访问。
Compose创建的网络名称基于我们所在项目的目录名称,比如我们项目在myapp目录下,那Compose会创建一个myapp_default网络。
有些场景下,默认的网络配置不能满足我们的需求,我们可以通过networks指令配置网络,通过default对默认的网络进行配置:
1 | |
我们还可以自定义网络:
1 | |
我们这里定义了front和back两个网络,web应用同时在两个网络中均能访问redis和db,而redis和db实现了隔离。driver_opts将选项列表指定为键值对以传递给此网络的驱动程序。
我们有时候不需要创建新的网络,只需要加入已有网络,可以使用external选项,指定一个已经存在的网络名称:
1 | |
加入网络时,我们可以指定容器的静态ip地址,这样我们在进行数据库连接时,可以不用容器服务名称,而直接使用ip地址:
1 | |
network_mode
设置网络模式。使用和docker run的–network参数一样的值。
1 | |
environment
在容器中设置环境变量,等同于docker run -e VARIABLE=VALUE ...
1 | |
env_file
从文件中获取环境变量,等同于docker run --env-file ...。
1 | |
环境变量文件中每一行必须符合格式,支持#开头的注释行。
1 | |
如果有变量名称与environment指令冲突,以environment指令为准。
volumes
volumes可以设置数据卷所挂载路径,它有两种方式,一种方式是设置宿主机路径(HOST:CONTAINER),通过[SOURCE:]TARGET[:MODE]格式,最后的ro用于只读,rw用于读写(默认):
1 | |
另一种方式直接设置数据卷的名称,需要在文件中配置数据卷:
1 | |
ports
端口暴露给宿主机,如果仅仅指定容器端口,宿主机将会随机选择端口。
1 | |
expose
暴露端口,和ports的区别是,expose不映射到宿主机,只被连接的服务访问。
1 | |
dns
自定义DNS服务器。可以是一个值,也可以是一个列表。
1 | |
restart
指定容器退出后的重启策略为始终重启。该命令对保持服务始终运行十分有效,在生产环境中推荐配置为always或者 unless-stopped。
1 | |
docker镜像推荐
下面推荐一些笔者常用的镜像。
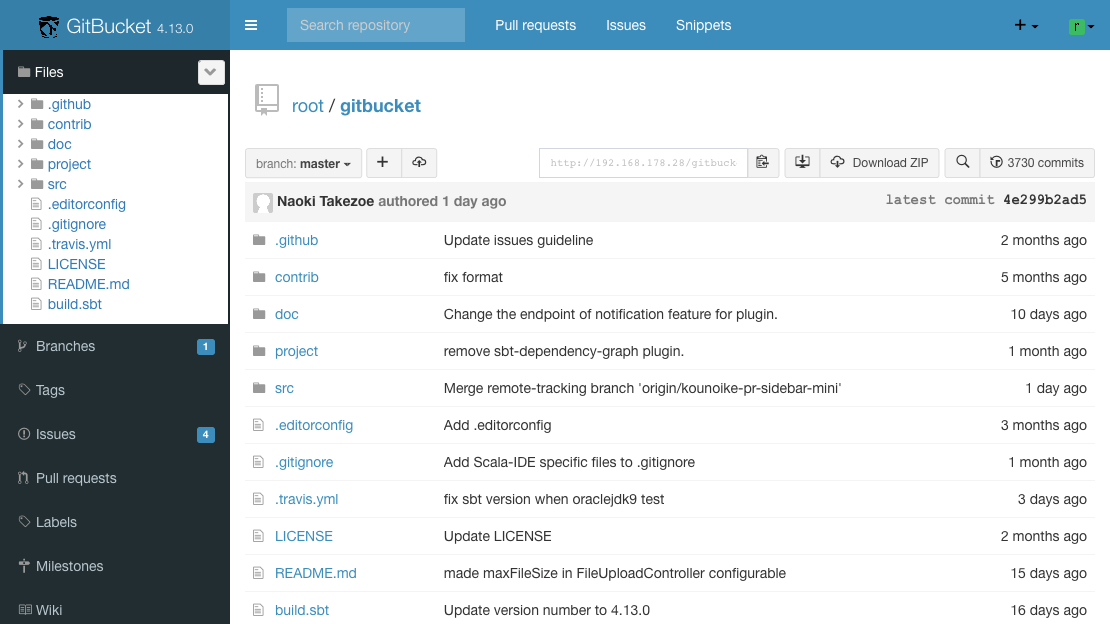
gitbucket
如果我们自己想要一个私有的git开发仓库,或者公司小团队使用,gitbucket是一个不错的选择;相比于gitlab动辄就占用内存3G,gitbucket几百mb的大小已经是很小巧迷你了,再配上直男般的蓝黑色,让人简直。。。。不过好在一般我们都是敲的git命令,所以不用在意他的界面。
1 | |
8080端口是它的界面的地址,29418端口是给git通过SSH去链接仓库的,建议开启。
filebrowser
如果你受够了某网盘几十KB的小水管速度,那么filebrowser是你搭建一个轻量级的私有云盘不错的选择。另一款网盘工具nextcloud也十分的不错,功能丰富且强大,带有app功能,不过需要结合数据库使用,配置略微繁琐,喜欢折腾的小伙伴可以自己尝试。
filebrowser使用了go语言编写,可以通过浏览器对服务器上的文件进行管理。可以是修改文件,或者是添加删除文件,甚至可以分享文件,是一个很棒的文件管理器,使用非常简单方便,功能很强大。
使用docker安装也很方便,我们可以只映射/srv目录下的文件:
1 | |
再通过nginx转发8080端口,这样我们就能在外网访问了;nginx配置文件中还需要修改上传文件的大小限制,这里我们改到2GB,大部分的文件都能上传了:
1 | |
scrapyd
我们身边有很多的爬虫应用案例,比如百度、Google、必应等搜索引擎都有自己的爬虫,会定时来抓取你的网站;再比如过年回家需要抢火车票,我们经常能够看到很多的抢票软件等,也都是爬虫的应用;不过我们在网络上肆意使用爬虫的时候也要注意相关法律法规,毕竟俗话说得好:
爬虫写得好,牢饭吃得饱

Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,只需要实现少量的代码,就能够快速的抓取。
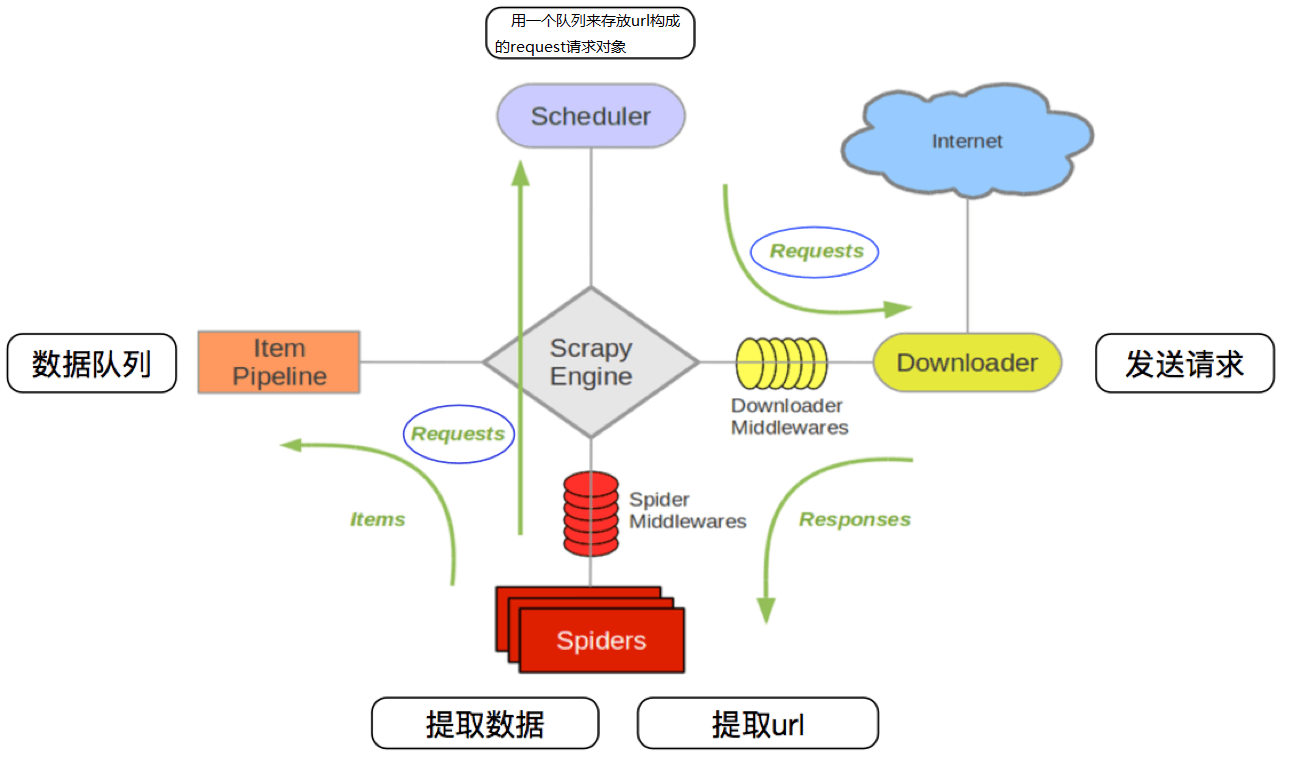
Scrapy爬虫部署需要使用scrapyd和scrapydweb,scrapyd是由scrapy开发者开发的、通过简单的JSON API来管理多个项目的应用;通过docker我们可以很轻松的启动一个scrapyd服务器:
1 | |
它的界面比较简单,我们需要通过繁琐的API接口来上传项目、启动或者停止项目:

因此Scrapy开发还提供了一个可视化管理爬虫的web应用,同时支持Scrapy日志分析和可视化。
1 | |
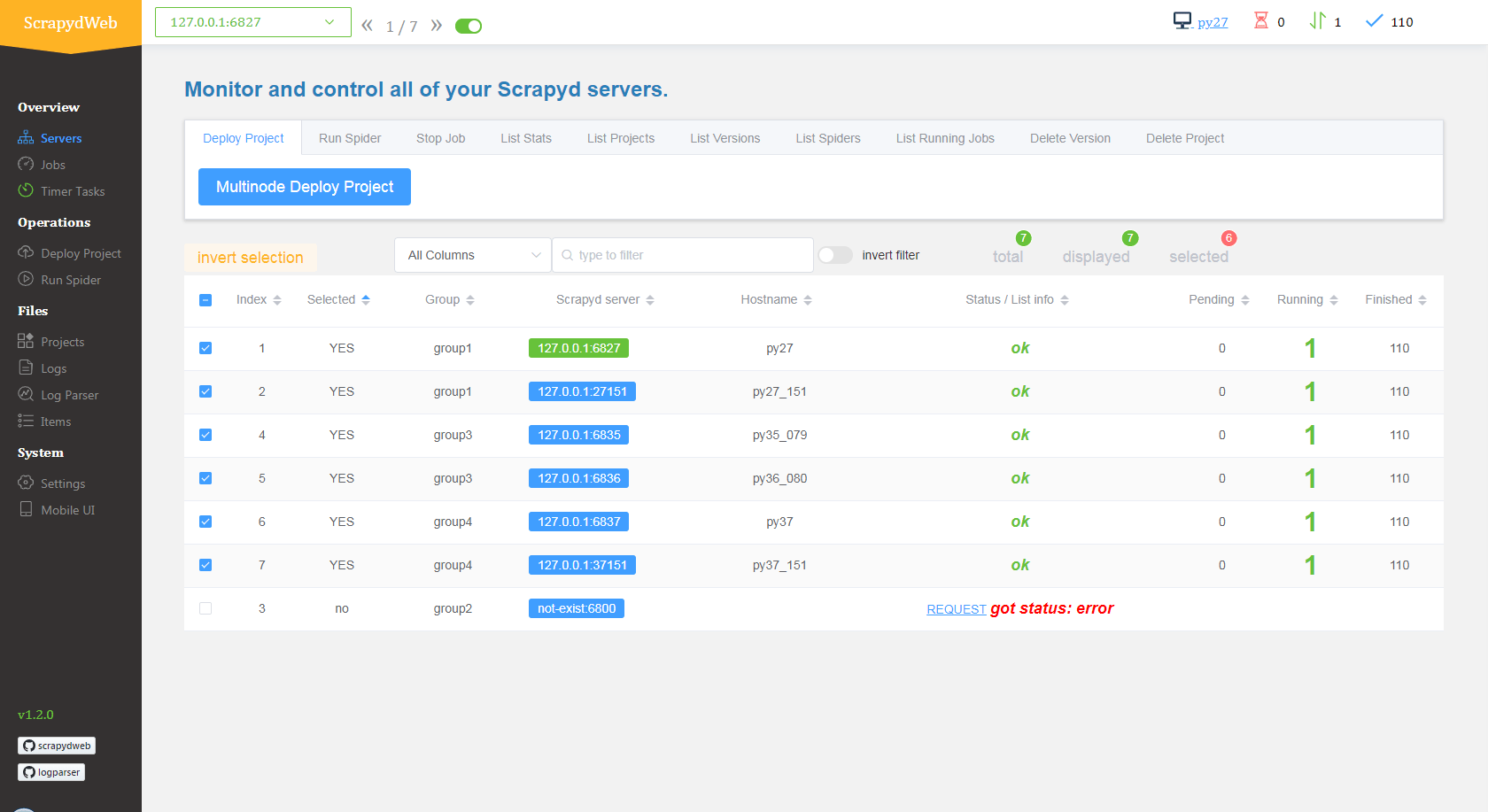
我们在web界面上就可以清楚的看到每个服务器运行爬虫的状态和数量,以及定时启动爬虫。
Scrapy是一个非常好用的爬虫框架,如果本文的阅读量突破一万,后面笔者可以聊一下它的使用。
chevereto
Chevereto是目前最好的图床之一了。功能也非常强大。其免费版和收费版的区别,在于收费版多了硬盘扩展,社交分享功能和技术支持,免费版的功能也够用了;Chevereto依赖的环境如下:
- PHP 5.5+
- MySQL 5.0+
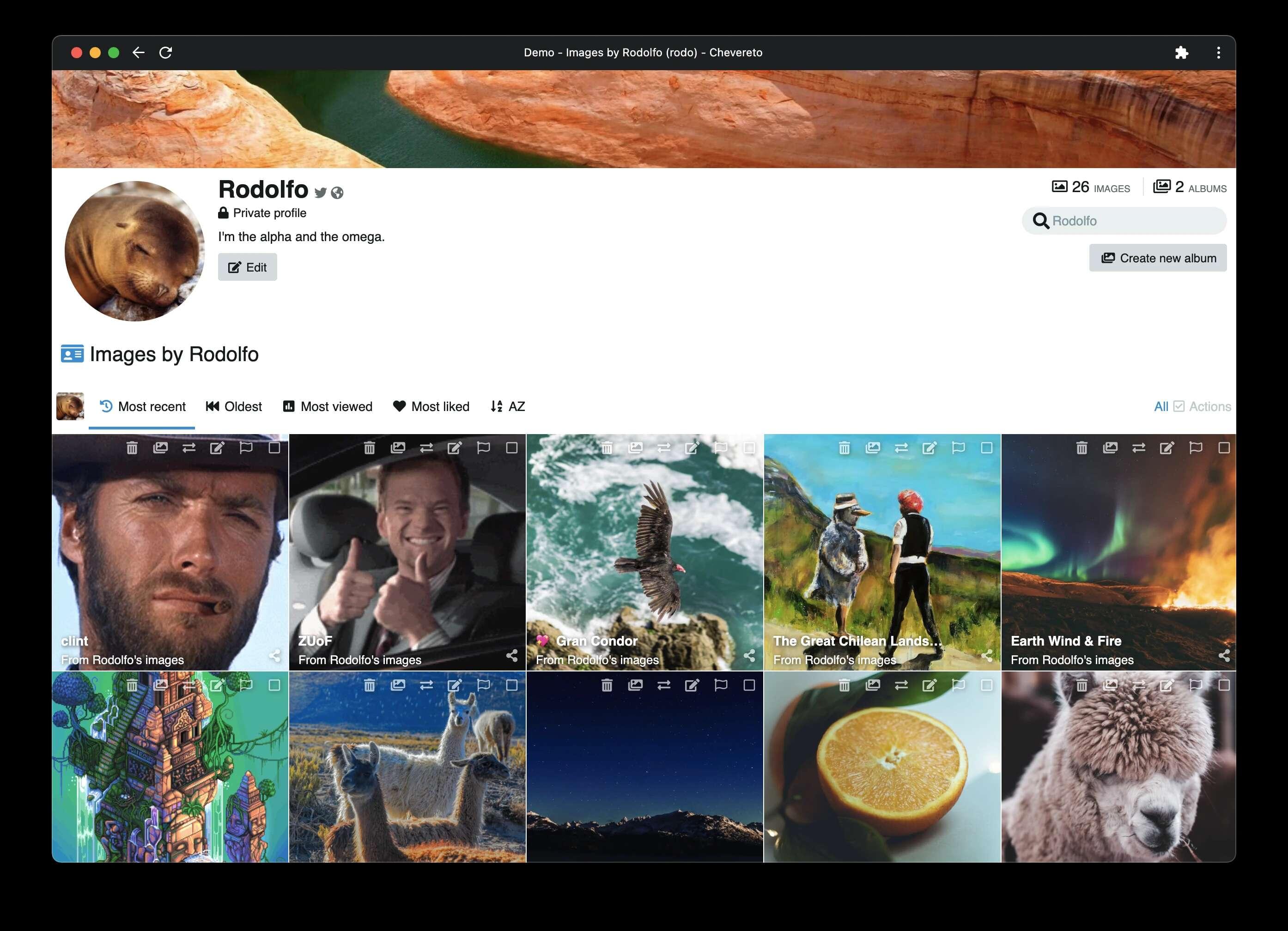
使用docker安装的话PHP的环境我们就可以省去安装步骤了,需要安装一个MySQL的环境,然后通过run命令设置MYSQL的环境变量:
1 | |
Chevereto运行起来后我们初始化设置管理员账号密码,然后在设置中修改界面为中文:
PHP默认限制上传大小为2MB,我们需要修改容器中的文件解除此限制;首先使用cp命令把容器中的.htaccess文件拷贝出来:
1 | |
然后编辑文件.htaccess,设置最大上传大小为大一点的数值,比如这里设为128MB,数值可以根据自己需要调整:
1 | |
我们把文件拷贝回容器的原处即可:
1 | |
最后一步我们在设置中修改上传限制,进入Chevereto,单击用户名弹出下拉菜单,选择【仪表盘】,然后点【设置】,弹出页面中选择【图片上传】,找到【最大上传文件大小】选项,修改不超过128的数值即可:
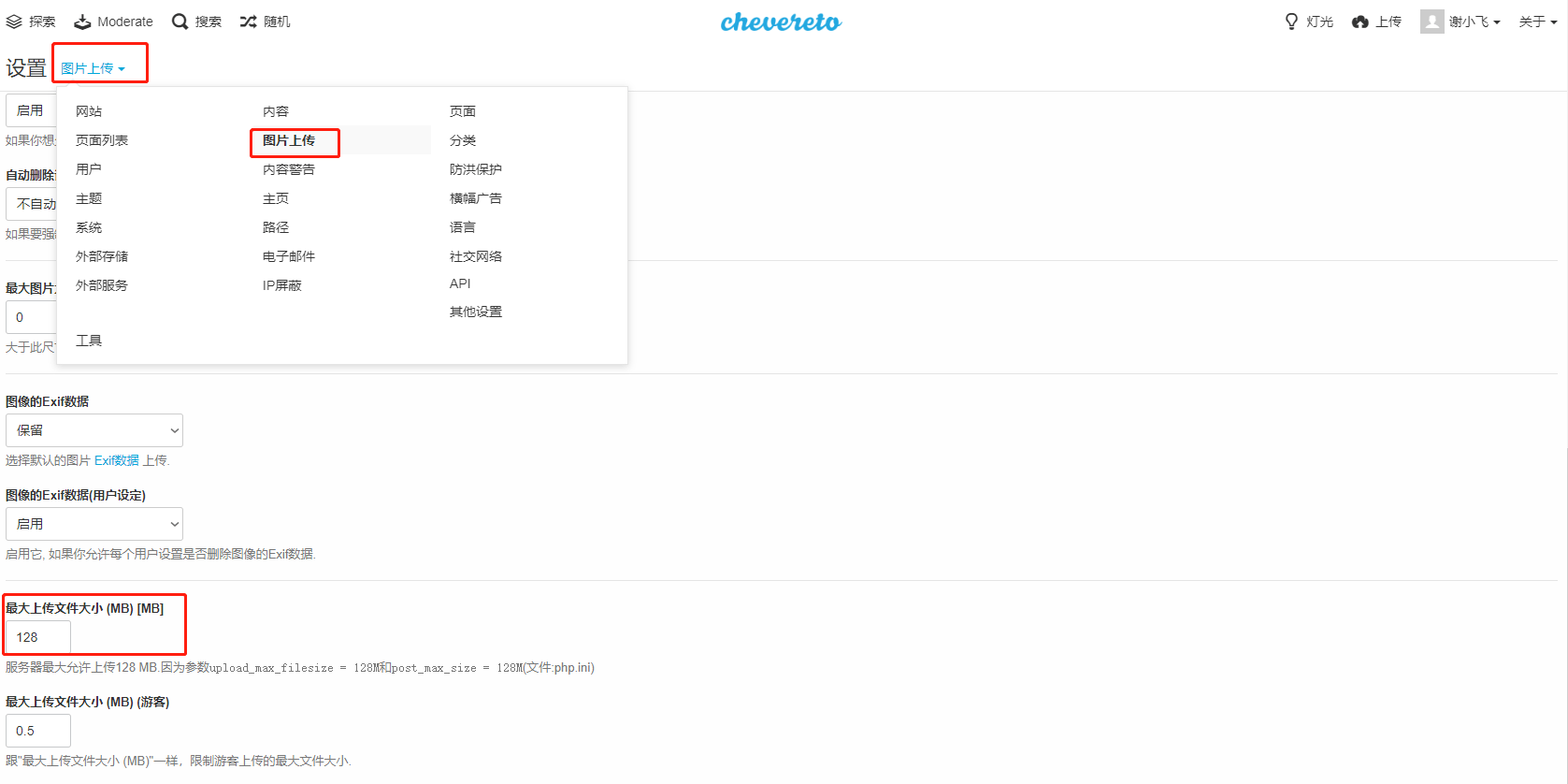
如果没有修改.htaccess文件,最后一个步骤的设置调整是不能超过2MB的。
这样我们的图床就搭建以及配置完毕了,其他个性化需要可以在设置中自行配置;我们去首页就能随意上传和查看图片了;通过nginx代理转发我们还可以暴露到外网,将你的美照分享给好友(前提是有公网IP或云服务器)。

portainer
Portainer是一个可视化的Docker操作界面,提供状态显示面板、应用模板快速部署、容器镜像网络数据卷的基本操作(包括上传下载镜像,创建容器等操作)、事件日志显示、容器控制台操作、Swarm集群和服务等集中管理和操作、登录用户管理和控制等功能。功能十分全面,基本能满足中小型单位对容器管理的全部需求。
通过一个run命令我们就可以启动portainer,/var/run/docker.sock是绑定宿主机的docker文件,在容器内部直接与docker守护进程通信进行接口调用:
1 | |
容器启动后,设置管理员账号密码,进入Portainer后台管理界面,点击Local环境就能够使用了:
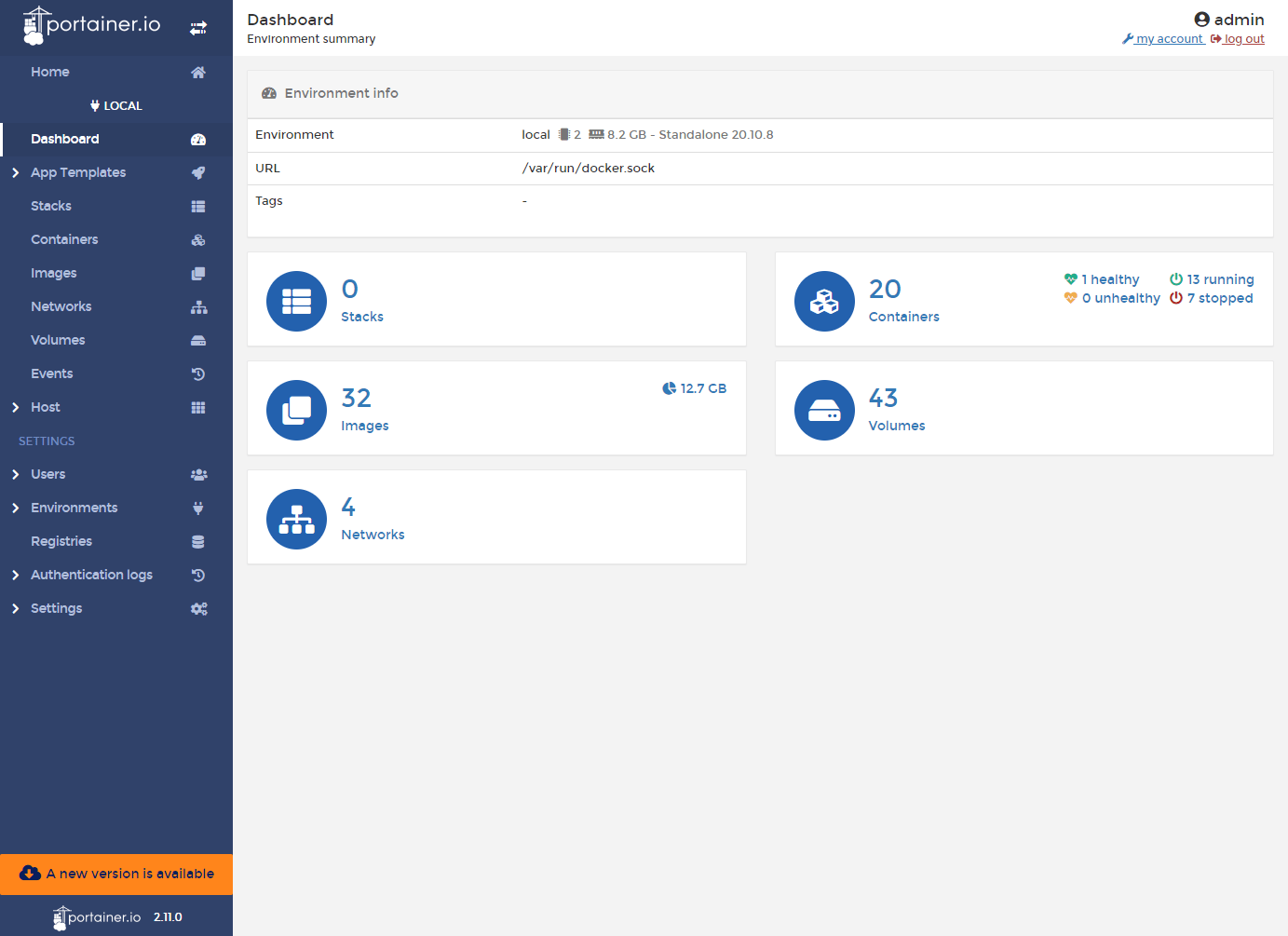
容器和镜像的管理也很方便,在管理界面直接增删镜像或容器即可;创建容器也直接可视化了,我们打开【Container】=>【Add container】,然后设置容器运行所需要的参数,我们这里以mysql为例:
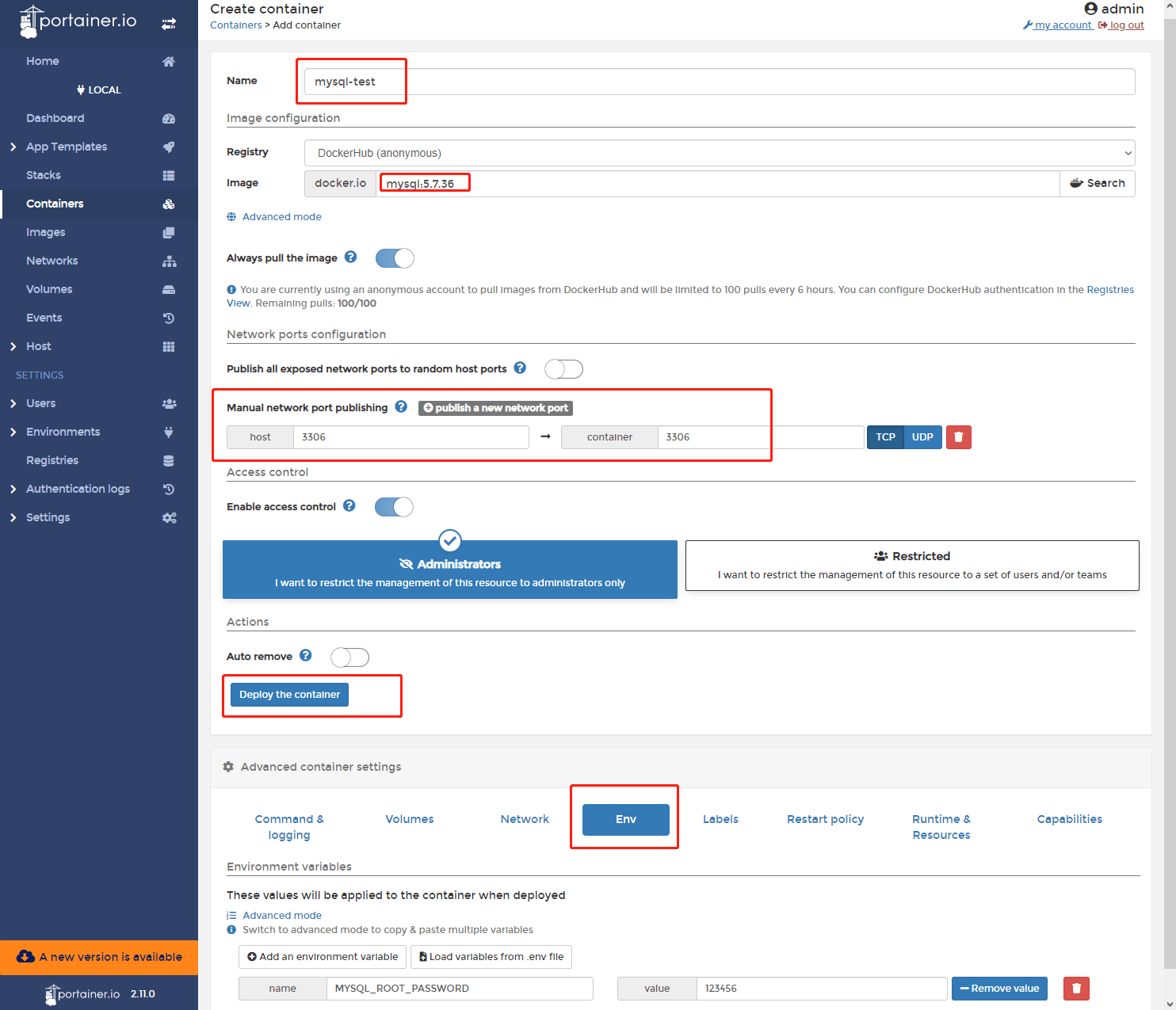
Restart policy建议选择Always,相当于设置--restart=always,保证了容器在服务器重启后总会自动重新启动。
webssh
Webssh是指通过浏览器以网页的形式通过SSH协议远程访问任何开启了SSH服务的设备;webssh工作的原理也很简单,大致如下:
1 | |
在后台启动一个webssh的后端服务器(python程序或其他语言开发的),前端浏览器通过websocket和服务器进行通信,将一些命令发送到webssh服务器,webssh服务器再将接收命令发送给需要通信且开启了ssh功能的服务器。
使用Webssh的好处是:在存在堡垒机(即跳板机)的环境下,如果堡垒机本身有开启web服务的话,那可以在堡垒机上部署webssh,这时不用通过SSH或者RDP访问堡垒机,直接打开浏览器就能以web形式通过堡垒机来SSH远程访问网络设备,这在一些内网防火墙不允许SSH,但是允许HTTP和HTTPS的环境中很实用。而且免去了安装putty、secureCRT等SSH client软件的必要。
通过docker运行webssh服务器也很简单:
1 | |
然后通过浏览器访问webssh服务器IP+8888端口号就可以进入它的界面了,它的界面也很简洁,甚至有着一丝丝的简陋,不过部署到堡垒机能用就行,还要啥自行车啊。通过填写堡垒机的hostname、端口等参数就能连接堡垒机ssh了:
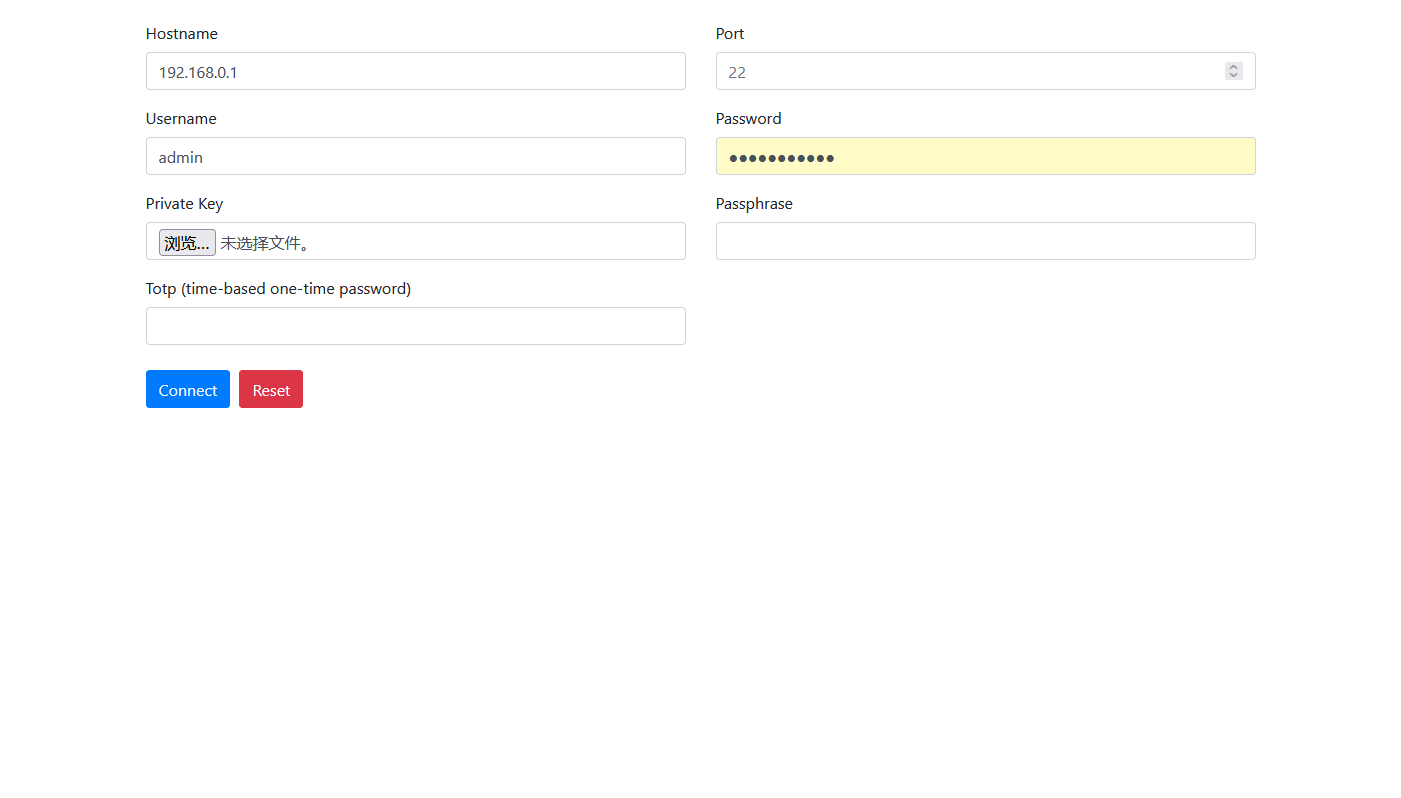
wizserver
为知笔记是一款老牌笔记应用了,支持markdown、网页笔记、网页剪藏和分享等多功能,最近推出了docker私有化部署的功能,同时支持5个用户,适合小团队使用。
我们新建一个wiznote目录,用于保存笔记的内容,然后run启动服务:
1 | |
稍等几分钟就能看到服务启动了,在本地打开localhost:8080打开主界面,默认管理员账号:admin@wiz.cn和密码123456。
为知笔记支持多平台客户端和移动端客户端,我们在客户端界面点击【切换服务器】,选择【企业私有服务器】,输入服务器的ip地址及端口号就能登录私有服务器:
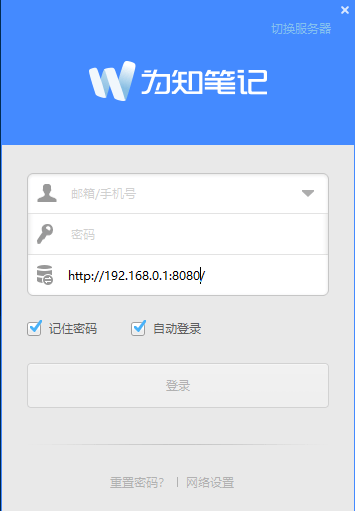
jellyfin
Jellyfin是一个自由的软件媒体系统,用于管理媒体和提供媒体服务,展示你自己的电影、电视剧、音乐等多媒体数据,并提供多平台访问播放服务。通过docker,我们可以很方便的启动它的服务;在本地创建media和config文件夹,media文件夹是媒体文件夹,我们可以根据需求继续创建media/movie、media/music等文件夹存放不同媒体资源:
1 | |
绑定不同端口说明如下:
| 端口 | 说明 |
|---|---|
| 8096 | WebUI 访问端口 |
| 7359/udp | (可选)允许本地网络的客户端发现 Jellyfin |
| 1900/udp | (可选)DLNA服务 |
容器创建后,我们打开localhost:8096就能打开安装向导页面,它的界面还是:
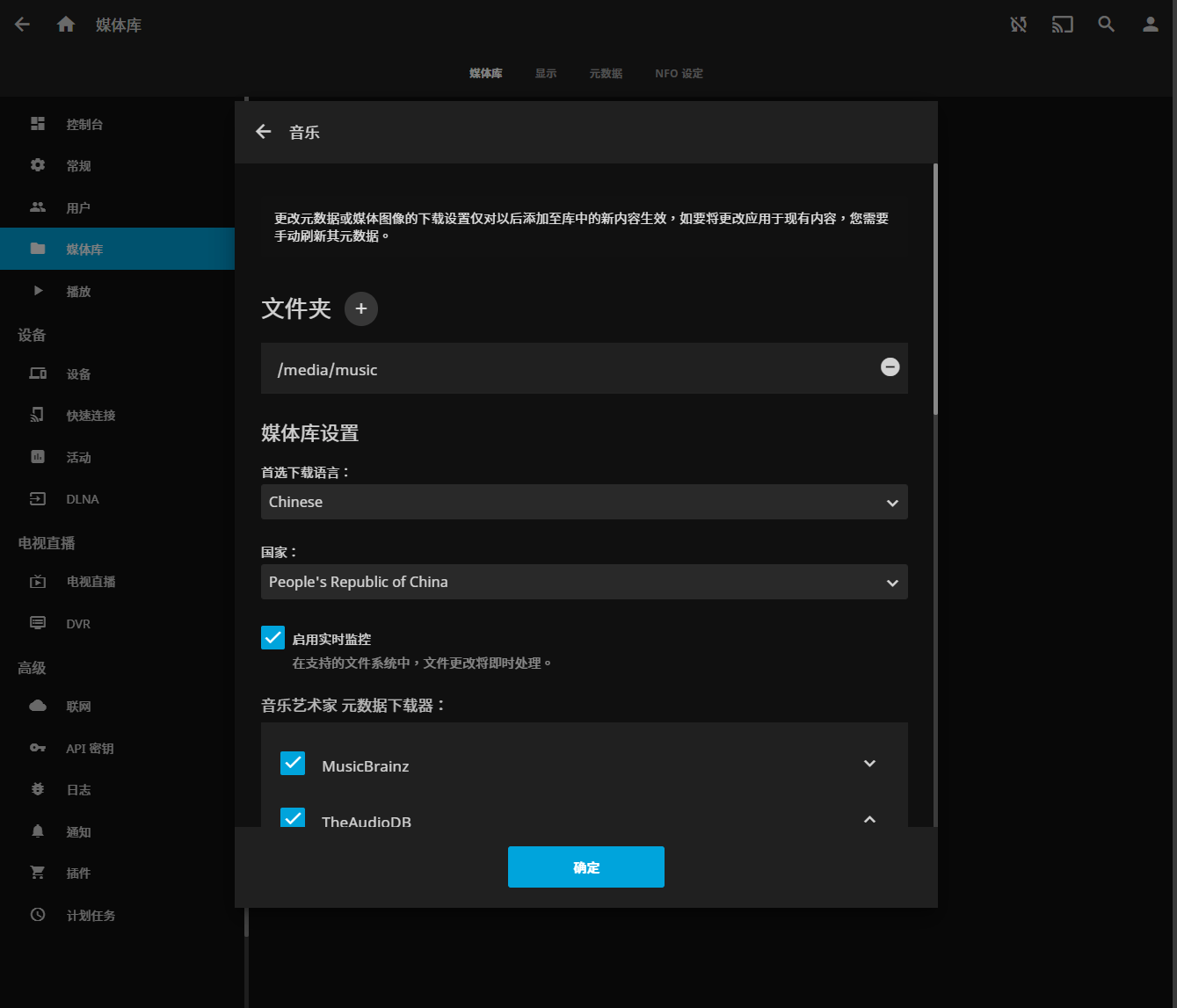
选择一系列的语言、国家(国家选择People's Republic of China)以及配置账号密码后我们就进入它的首页了;我们选择【添加媒体库】,选择你media文件夹下的子文件夹,就能看到其下面的媒体文件了:
aria2
Aria2是一款开源下载工具,可帮助简化不同设备和服务器之间的下载过程。它支持磁力链接、BT种子、http等类型的文件下载,与迅雷及QQ旋风相比,Aria2有着优秀的性能及较低的资源占用,架构本身非常轻巧,通常只需要4兆字节(HTTP下载)到9兆字节(用于BitTorrent交互)之间。
另外,aria2由于它的开源特性,因此也用在很多离线下载的场景,比如很多路由器都支持aria2离线下载功能,我们在路由器的插件市场中安装aria2后,在路由器挂载u盘,上班的时候想要下载的电影、视频等链接丢给它,回到家就可以直接观看了;顺带提一下,chrome浏览器配合油猴插件直接愉快的离线下载百度网盘的文件。
我们通过docker来安装aria2十分方便,新建一个aria2-downloads文件夹映射下载的目录,aria2-config文件夹映射配置的目录。这里的p3terx/aria2-pro镜像就是我们aria2下载的主程序,它是一个命令行的程序,因此搭配p3terx/ariang镜像作为它的可视化管理界面。用到了多个镜像,我们就可以通过docker compose来进行构建:
1 | |
项目启动后,我们打开AriaNg的管理界面,在设置中配置yarml文件中的RPC端口(默认6800)和RPC密钥。
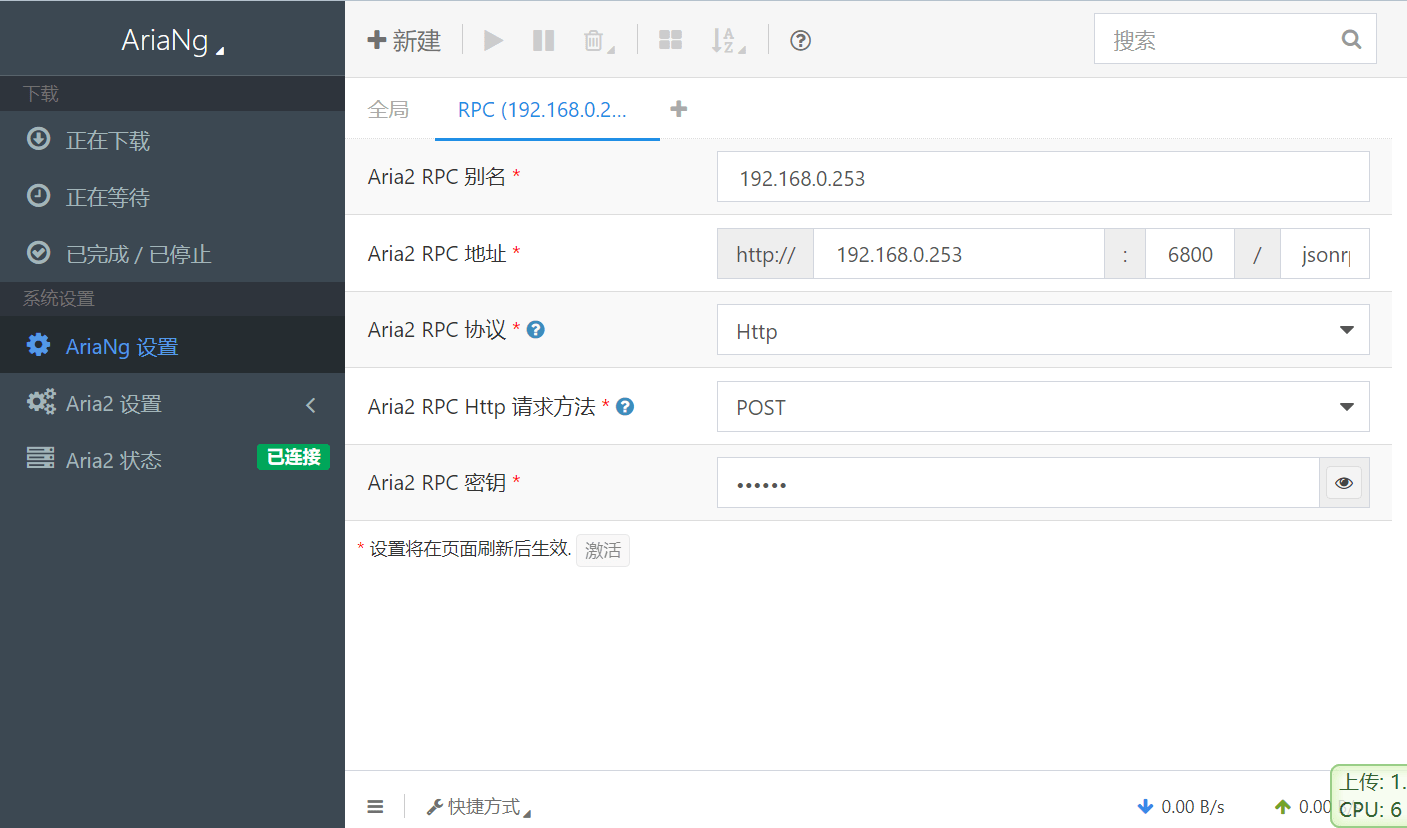
配置完成后,点击【新建】,输入你的下载链接就可以愉快地等待了。
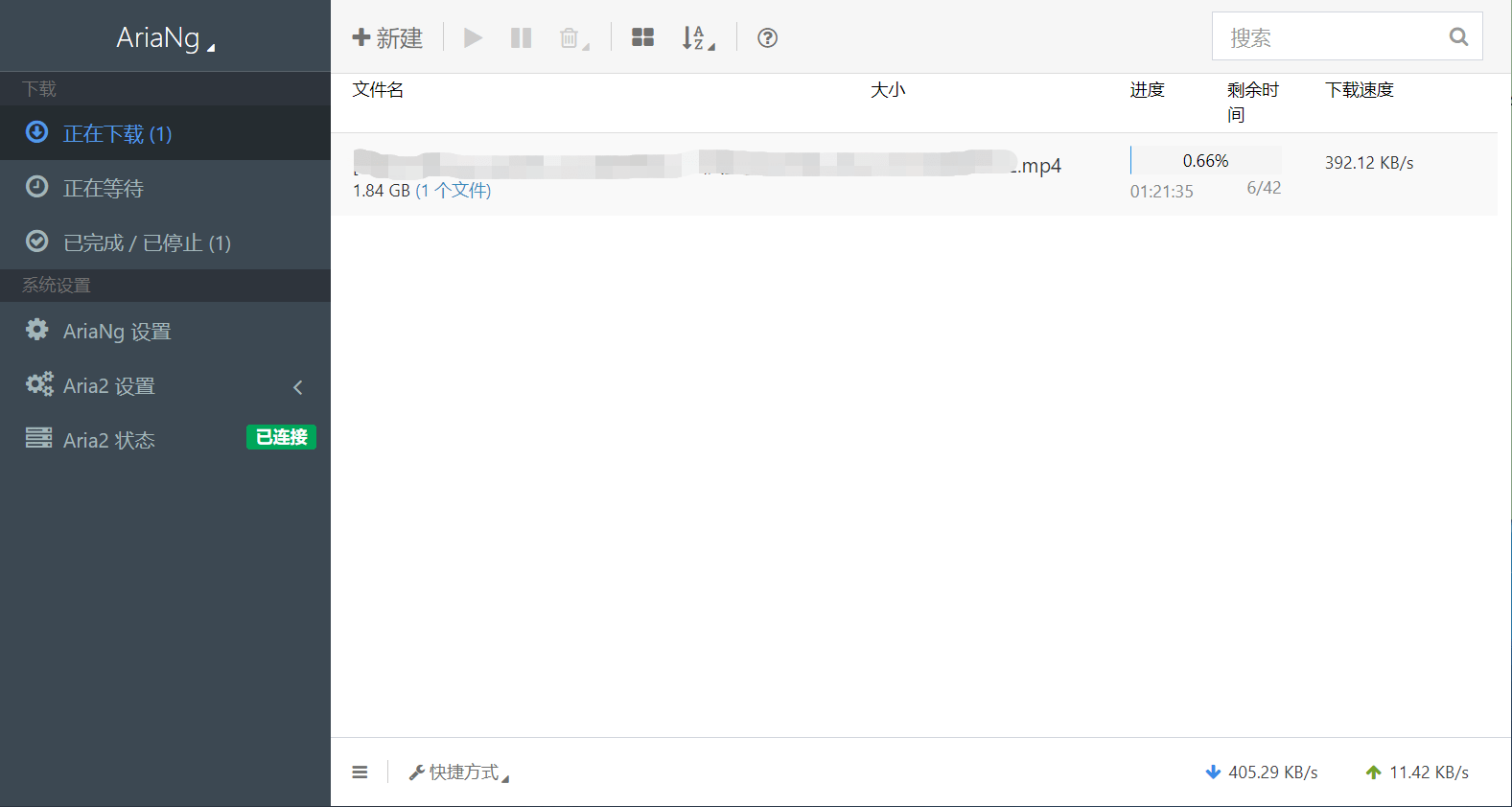
下载速度和你的实际带宽以及资源情况等都有关系,上图仅做展示。
本网所有内容文字和图片,版权均属谢小飞所有,任何媒体、网站或个人未经本网协议授权不得转载、链接、转贴或以其他方式复制发布/发表。如需转载请关注公众号【前端壹读】后回复【转载】。