前端抢饭碗系列之初识Docker容器化部署
随着容器化技术盛行,Docker在前端领域也有着越来越广泛的应用;传统的前端部署方式需要我们将项目打包生成一系列的静态文件,然后上传到服务器,配置nginx文件;如果我们使用容器化部署,将部署操作都命令化,集中成一个脚本就可以完成原来复杂的部署过程。本文从Docker基础开始,来认识Docker的各种命令操作。
docker简介
Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。
![]()
Docker的英文翻译是码头工人,码头工人一般搬运的都是集装箱(Container),集装箱最大的成功在于其产品的标准化以及由此建立的一整套运输体系。在一艘几十万吨的巨轮上,装满了各种各样满载的集装箱,彼此之间不会相互影响;因此其本身就有标准化、集约化的特性。
从Docker的logo我们也能看出,Docker的思想来自于集装箱;各个应用程序相当于不同的集装箱,每个应用程序有着不同的应用环境,比如python开发的应用需要服务器部署一套python的开发环境,nodejs开发的应用需要服务器部署nodejs的环境,不同环境之间有可能还会彼此冲突,Docker可以帮助我们隔离不同的环境。
有些同学于是就想到了,这不是虚拟机干的活么。是的,虚拟机可以很好的帮我们隔离各个环境,我们可以在windows上运行macos、ubuntu等虚拟机,也可以在macos上安装windows的虚拟机;不过传统的虚拟机技术是虚拟一整套硬件后,在其上运行完整的操作系统,在该系统上再运行所需应用进程,这样导致一台电脑只能运行数量较少的虚拟机。
但是Docker使用的容器技术比虚拟机更加的轻便和快捷。容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便,下图比较了两者的区别:

对比总结:
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为 MB | 一般为 GB |
| 系统资源 | 0~5% |
5~15% |
| 性能 | 接近原生 | 弱于原生 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
Docker优势
docker有以下优势:
- 更高效的利用系统资源
- 更快速的启动时间
- 一致的运行环境
- 持续交付和部署
- 更轻松的迁移
- 更轻松的维护和扩展
docker通常用于如下场景:
- web应用的自动化打包和发布;
- 自动化测试和持续集成、发布;
- 在服务型环境中部署和调整数据库或其他的后台应用;
- 从头编译或者扩展现有的OpenShift或Cloud Foundry平台来搭建自己的PaaS环境。
基本概念
在Docker中有三个基本概念:
- 镜像(Image)
- 容器(Container)
- 仓库(Repository)
理解了Docker的基本概念,我们就理解了Docker的整个生命周期。
首先我们来弄懂镜像的概念,Docker镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。
如果有装系统经验的童鞋,可以把Docker镜像理解为一个操作系统的镜像(ISO文件),它是一个固定的文件,从一个镜像中,我们可以装到很多电脑上,变成一个个的操作系统(相当于容器),每个系统都是相同的,不过可以选择定制化安装。
和系统镜像不同的是,Docker镜像并不是像ISO文件那样整体打包成一个文件的,而是设计成了分层存储的架构,它并不是由一个文件组成,而是由多层文件联合组成。
构建镜像时,会一层层的构建,前面一层是后面一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。
其次是容器的概念,从编程的角度看,镜像和容器的关系更像是类和实例的关系;从一个镜像可以启动一个或者多个容器;镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。

前面讲过镜像使用的是分层存储,容器也是如此。每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为容器存储层。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
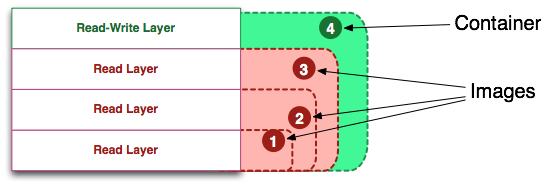
因此容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层。
最后是仓库(Repository)的概念,我们构建一个镜像后,可以在本地运行,但是如果我们想要给网络上的其他用户使用,就要一个集中存储和分发镜像的服务器,仓库就是这样一个工具,有点类似Github。
镜像仓库Repository是同一类镜像的集合,包含了不同tag(标签)的Docker镜像,比如ubuntu是仓库的名称,它里面有不同的tag,比如16.04、18.04,我们从镜像仓库中来获取镜像时可以通过<仓库名>:<标签>的格式来指定具体版本的镜像,比如ubuntu18.04;如果忽略标签,用latest作为默认标签。
镜像
我们上面介绍过,镜像是Docker的三个基本组件之一;运行容器需要本地有相应的镜像,如果没有会从远程仓库下载;那么我们来看下如何操作镜像。
查找镜像
我们可以从Docker Hub来搜索镜像
1 | |
查找结果:
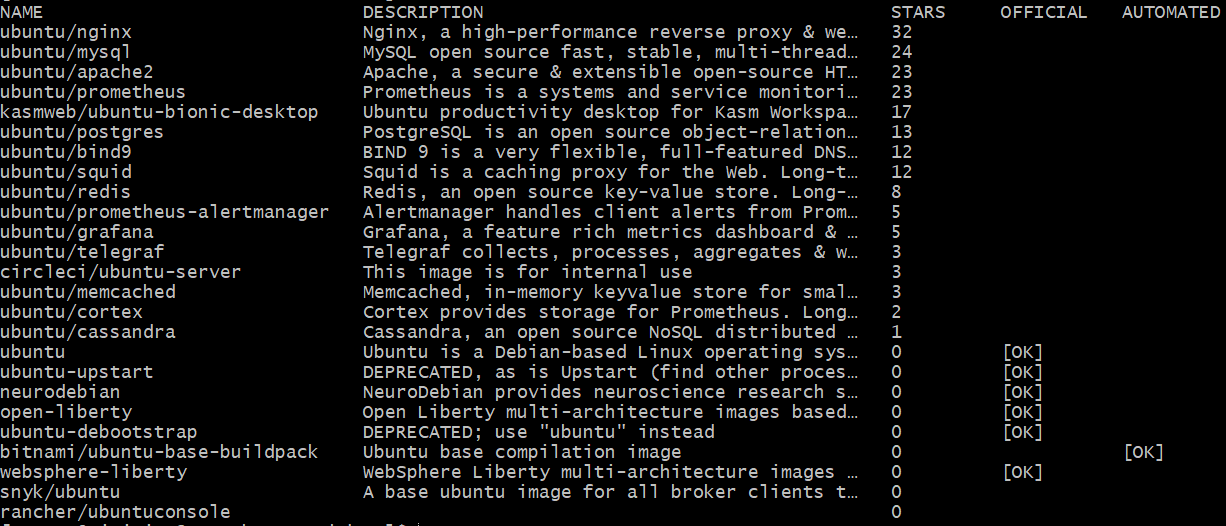
查找的列表中包含了以下几个字段:
- NAME: 镜像仓库源的名称
- DESCRIPTION: 镜像的描述
- STARS: 类似Github里面的 star。
- OFFICIAL: 是否docker官方发布
- AUTOMATED: 自动构建。
获取镜像
我们要获取镜像,可以通过docker pull命令,它的格式如下:
1 | |
还是以ubuntu为例:
1 | |
我们看到最后一行docker.io显示这是从官方仓库拉取的。
从下载过程我们可以看出我们上面说的分层存储的概念,即镜像是由多层存储构成;下载也是一层层的去下载,而不是单独一个文件;因此如果下载中有某个层已经被其他镜像下载过,则会显示Already exists。下载过程中给出了每一层的ID的前12位,下载结束后给出镜像完整的sha256摘要。
Docker的镜像仓库分为官方仓库和非官方,官方的镜像就是从Docker Hub拉取的;如果想要从第三方的镜像仓库获取,可以在仓库名称前加上仓库的服务地址:
1 | |
列出镜像
通过下面的命令,我们可以列出本地已经下载的镜像:
1 | |
运行命令出现以下列表:
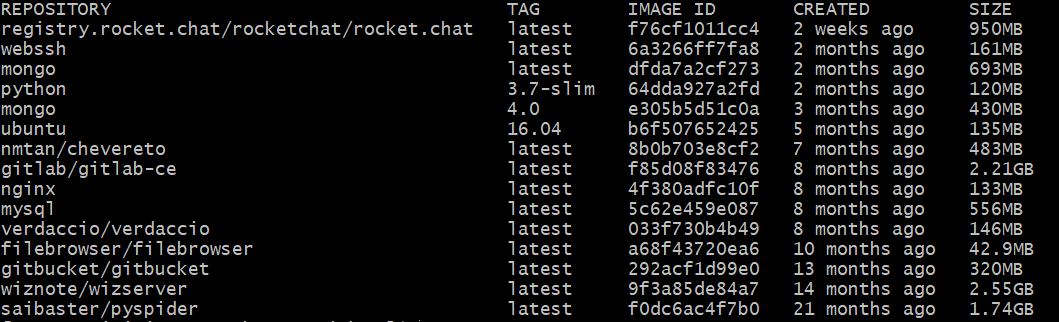
列表包含了仓库名、标签、镜像ID、创建时间和所占用空间;我们看到有两个mongo的镜像,不过两个镜像有不同的标签。
ls命令默认会列出所有的镜像,但是当本地镜像比较多的时候不方便查看,有时候我们希望列出部分的镜像,除了可以通过linux的grep命令,还可以在ls命令后面跟上参数:
1 | |
删除镜像
我们可以通过rm命令删除本地镜像:
1 | |
或者简写为rmi命令:
1 | |
这里的<镜像>,可以是镜像短ID、镜像长ID、镜像名或者镜像摘要;docker image ls列出来的已经是短ID了,我们还可以取前三个字符进行删除;比如我们想要删除上面的mongo:4.0:
1 | |
构建镜像
除了使用官方的镜像,我们可以构建自己的镜像;一般都在其他的镜像基础上进行构建,比如node、nginx等;构建镜像需要用到Dockerfile,它是一个文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
我们在一个空白目录新建一个Dockerfile:
1 | |
我们向Dockerfile写入以下内容:
1 | |
这里的Dockerfile很简单,就两个命令:FROM和RUN,我们后面会对Dockerfile的命令进行详细介绍;我们使用build命令构建镜像,它的格式为:
1 | |
因此,我们在Dockerfile所在的目录执行命令:
1 | |
运行命令,我们看到镜像也是按照Dockerfile里面的步骤,分层进行构建的:
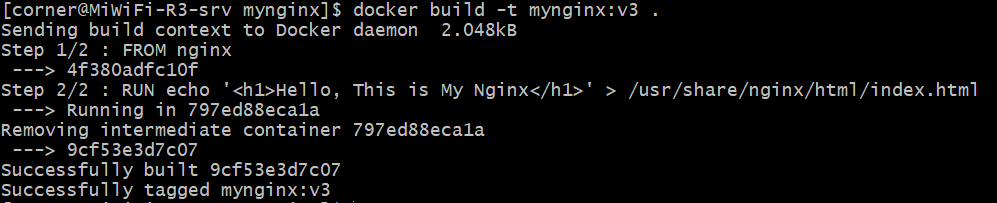
构建成功后,我们列出所有的镜像就能看到刚刚构建的mynginx了。在上面的命令中,我们发现最后有一个.,它表示了当前目录,如果不写这个目录会报错提示;如果对应上面的格式,它其实就是上下文路径,那这个上下文路径是做什么用的呢?要理解这个路径的作用,我们首先要来理解Docker的架构。
Docker是一个典型的C/S架构的应用,它可以分为Docker客户端(平时敲的Docker命令)和Docker服务端(Docker守护进程)。Docker客户端通过REST API和服务端进行交互,docker客户端每发送一条指令,底层都会转化成REST API调用的形式发送给服务端,服务端处理客户端发送的请求并给出响应。
因此表面上看我们好像在本机上执行各种Docker的功能,实际上都是都是在Docker服务端完成的,包括Docker镜像的构建、容器创建、容器运行等工作都是Docker服务端来完成的,Docker客户端只是承担发送指令的角色。
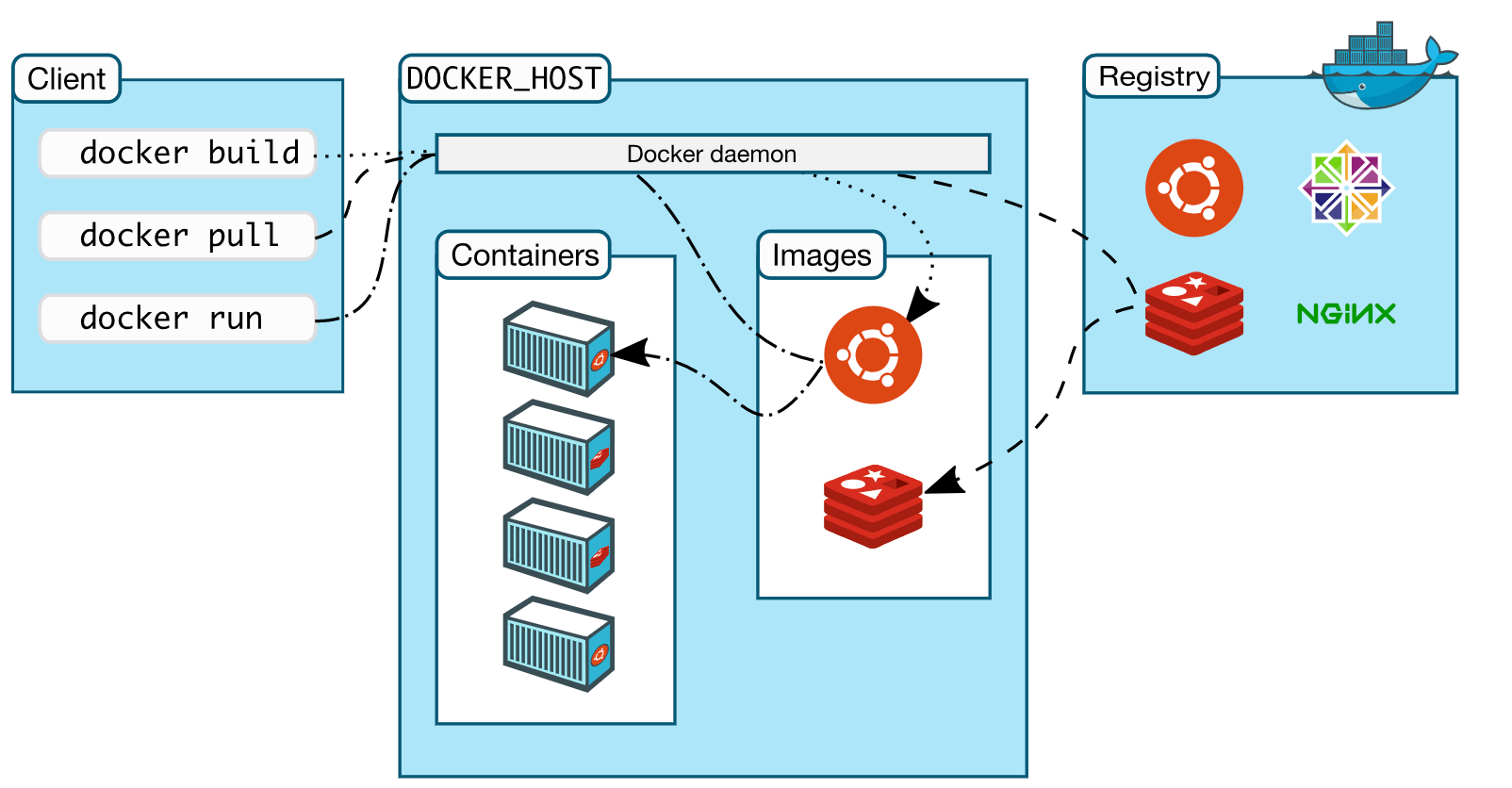
理解了Docker的架构就很容器理解Docker构建镜像的工作原理了,它的流程大致如下:
- 执行build命令
- Docker客户端会将构建命令后面指定的上下文路径下的所有文件打包成一个tar包,发送给Docker服务端;
- Docker服务端收到客户端发送的tar包,然后解压,根据Dockerfile里面的指令进行镜像的分层构建;
因此上下文路径本质上就是指定服务端上Dockerfile中指令工作的目录;比如我们在Dockerfile中经常需要拷贝代码到镜像中去,因此会这么写:
1 | |
这里要复制的package.json文件,并不一定在docker build命令执行的目录下,也不一定是在Dockerfile文件同级目录下,而是docker build命令指定的上下文路径目录下的package.json。
容器
介绍了镜像,我们到了Docker第三个核心概念了:容器。容器是镜像的运行时的实例,我们可以从一个镜像上启动一个或多个容器。
对容器的管理包括创建、启动、停止、进入、导入导出和删除等,我们分别来看下每个操作的具体命令以及效果。
创建启动容器
新建并启动一个容器用的命令是docker run,它后面有时候会带上有很长很长的选项,不过其基本的语法如下:
1 | |
它可以带上一些常见的选项:
- -d:容器在后台运行
- -t:为容器重新分配一个伪输入终端,通常与-i同时使用
- -i:以交互模式运行容器,通常与-t同时使用
- -P:随机端口映射
- -p:指定端口映射
- –name:为容器指定一个名称
- -e:设置环境变量
- –dns:指定容器使用的DNS服务器
- -m:设置容器使用内存最大值
- –net=”bridge”: 指定容器的网络连接类型,支持 bridge/host/none/container: 四种类型;
- –link:链接另一个容器
- -v:绑定卷
- –rm:退出容器后删除该容器
我们创建一个hello world容器:
1 | |
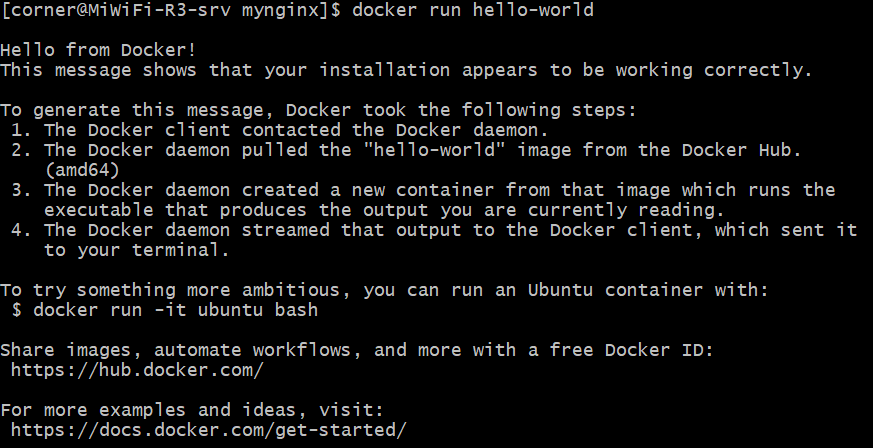
但是这样创建的容器只能看到一堆的打印说明,我们不能对容器进行任何操作,我们可以加上-it选项(-i和-t的简写),来让Docker分配一个终端给这个容器:
1 | |
我们可以在容器内部进行操作了,退出终端可以使用exit命令或者ctrl+d;我们退出容器后如果查看运行中的容器,发现并没有任何容器信息。
一般我们都是需要让容器在后台运行,因此我们加上-d:
1 | |
容器不再以命令行的方式呈现了,而是直接丢出一长串的数字字母组合,这是容器的唯一id;再用ps命令查看运行状态的容器,看到我们的容器已经在后台默默运行了:

当使用run命令创建容器时,Docker在后台进行了如下的操作:
- 检查本地是否存在指定的镜像,不存在就从 registry 下载
- 利用镜像创建并启动一个容器
- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
- 从地址池配置一个 ip 地址给容器
- 执行用户指定的应用程序
- 执行完毕后容器被终止
终止容器
我们可以使用stop命令来终止容器的运行;如果容器中的应用终结或者报错时,容器也会自动终止;我们可以使用ps命令查看到的容器短id来终止对应的容器:
1 | |
对于终止状态的容器,ps命令已经不能看到它了,我们可以加上-a选项(表示所有)来查看,它的STATUS已经变成了Exited:
1 | |
终止状态的容器我们可以使用docker start [容器id]来让它重新进入启动状态,运行中的容器我们也可以使用docker restart [容器id]让它重新启动。
进入容器
有时候我们会需要进入容器进行一些操作,比如进入nginx容器进行平滑重启,我们可以使用docker attach或者docker exec进入,不过推荐使用exec命令。
我们首先看下如果使用attach命令:
1 | |
当我们从终端exit后,整个容器会停止;而使用exec命令不会导致容器停止。
如果只使用-i参数,由于没有分配伪终端,界面没有我们熟悉的Linux命令提示符,但是执行命令仍然可以看到运行结果;当使用-i和-t参数时,才能看到我们常见的Linux命令提示符。
1 | |
需要注意的是,我们进入的容器需要是运行状态,如果不是运行状态,则会报错:
1 | |
查看容器日志
我们经常需要对容器运行过程进行一些监测,查看它的运行过程记录的日志情况,以及是否报错等等;使用logs命令获取容器的日志。
1 | |
它还支持以下几个参数:
- -f : 跟踪日志输出
- –since :显示某个开始时间的所有日志
- -t : 显示时间戳
- –tail :仅列出最新N条容器日志
logs命令会展示从容器启动以来的所有日志,如果容器运行时间久,会列出非常多的日志,我们可以加tail参数仅展示最新的日志记录:
1 | |
分析容器
对于已经创建的容器,我们可以使用inspect来查看容器的底层基础信息,包括容器的id、创建时间、运行状态、启动参数、目录挂载、网路配置等等;另外,该命令也能查看docker镜像的信息,它的格式如下:
1 | |
inspect支持以下选项:
- -f :指定返回值的模板文件。
- -s :显示总的文件大小。
- –type :为指定类型返回JSON。
运行后,会通过JSON格式显示容器的基本信息:
但是这么大段的文字,我们想要获取对我们有用的信息十分的麻烦;除了用grep进行过滤外(万物皆可grep),我们还可以通过-f参数:
1 | |
删除容器
如果一个容器我们不想再使用了,可以使用rm命令来删除:
1 | |
如果要删除一个运行中的容器,可以添加-f参数:
1 | |
数据管理
我们上面介绍到容器是保持无状态化的,就是随用随删,并不会保留数据记录;在使用docker的时候,经常会用到一些需要保留数据的容器,比如mysql、mongodb,往往需要对容器中的数据进行持久化;或者在多个容器之间进行数据共享,这就涉及到了容器的数据管理,主要有两种方式:
- 数据卷(Data Volumes)
- 挂载主机目录 (Bind mounts)
数据卷
数据卷是一个可供一个或多个容器使用的特殊目录,它绕过 UFS,可以提供很多有用的特性:
- 数据卷可以在容器之间共享和重用
- 对数据卷的修改会立马生效
- 对数据卷的更新,不会影响镜像
- 数据卷默认会一直存在,即使容器被删除
首先我们创建一个数据卷:
1 | |
通过ls可以列出我们本地所有的数据卷:
1 | |
inspect命令也可以查看我们数据卷的具体信息:
1 | |
在启动容器时,使用--mount将数据卷挂载在容器的目录里(可以有多个挂载点):
1 | |
我们借助上面的inspect命令查看容器的挂载信息:
1 | |
数据卷是被设计用来持久化数据的,它的生命周期独立于容器;因此即使我们将容器删除了,数据卷的数据依然还是存在的,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的数据卷,我们可以在删除容器的时候使用docker rm -v命令同时删除数据卷,或者手动来删除:
1 | |
无主的数据卷可能会占据很多空间,要清理请使用以下命令(谨慎使用!):
1 | |
挂载目录
我们发现上面数据卷挂载的目录都是在docker的安装路径下,不利于我们进行维护,我们可以直接挂载自定义的目录。
1 | |
挂载的本地目录的路径必须是
绝对路径,不能是相对路径。
本地路径如果不存在,会自动生成。
默认挂载的主机目录的默认权限是读写,可以通过增加readonly指定为只读。
1 | |
加readonly后,如果我们在容器内的/usr/share/nginx/html目录下修改文件或者新建文件就会报错。
需要注意的是,如果我们挂载本地目录,需要保证挂载的目录下面有程序运行所需要的文件,比如这里nginx容器需要在我们在本地目录/home/nginx下有index.html文件,如果没有的话会报403错误。
本章完结。
本网所有内容文字和图片,版权均属谢小飞所有,任何媒体、网站或个人未经本网协议授权不得转载、链接、转贴或以其他方式复制发布/发表。如需转载请关注公众号【前端壹读】后回复【转载】。