源码剖析Bullshit文章生成器
前段时间,有一个叫“狗屁不通文章生成器”的项目一下子吸引了大家的兴趣,还引起各大科技媒体;36Kr、新浪专栏IT之家都不约而同的刊文报道。然而,综看整个项目,除去README、LICENSE和gitignore,一共就6个文件,却达到了惊人的11.6k的Star和2.2k的Fork,平均下来每个文件有将近2k的Star。你可能会发出疑问了,这究竟是人性的扭曲还是道德的沦丧?今天就让我们来看一下它究竟有何黑科技能自动生成文章。
事情的起因来源于知乎上的一篇提问,有人提问“学生会退会申请六千字怎么写?”于是乎,各路大神纷纷前来献计献策,有复制粘贴六千字“不干了”的,有复制粘贴六千字《道德经》的,更有提议使用美人计撩学长的;然而其中的一个回答横空出世,答主随手就写了一个开源项目狗屁不通文章生成器;通过该项目,快速生成了一篇相关文章,不仅解决了题主的问题,还得到了广大网友的认同。
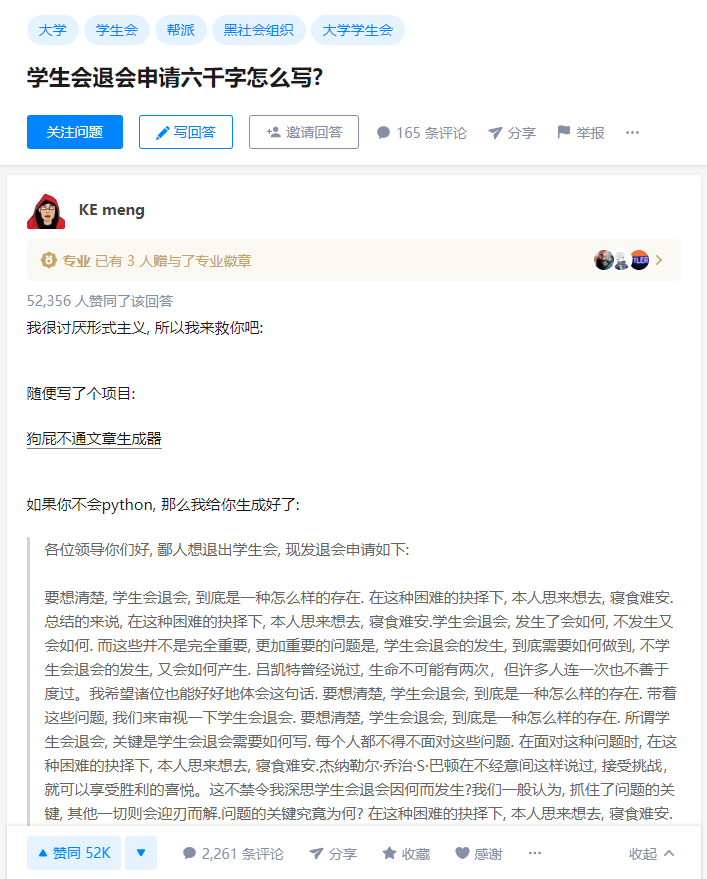
文章太长了,这边就不放完整版的了,有兴趣的童鞋可以去知乎观摩一下原文《学生会退会申请六千字怎么写?》,我试了下,果然是滑到底都需要半分钟之久。

该项目一开始为python3版本,后来有网友整理了网页版的,现在我们常用的是由suulnnka修改的在线版本,对页面的样式进行了优化,将生成的主题放入query参数中,使用更加的方便,这里我们随机来生成一篇文章看一下效果:

可以看出整篇文章虽然废话连篇、狗屁不通,但是段段扣题,旁征博引,引用各种名人名言,什么爱迪生曾经提到,什么康德曾经说过,每一段说的貌似都有理有据,令人无法反驳。
那么作者到底是如何来生成这么一长串的长篇大论的呢?最开始我还猜测是不是通过某种神经网络算法来将每一段话拼接起来,但是作者很明确的在README中写道:
鄙人才疏学浅并不会任何自然语言处理相关算法. 而且目前比较偏爱简单有效的方式达到目的方式. 除非撞到了天花板, 否则暂时不会引入任何神经网络等算法. 不过欢迎任何人另开分支实现更复杂, 效果更好的算法. 不过除非效果拔群, 否则鄙人暂时不会融合.
很明显,作者只是通过某种简单有效的方式来实现这个功能的,那让我来深扒一下源码,看看这种到底是怎么样一种简单有效的方式。
首先放在项目开始的是定义的一些论述、名人名言、前后垫话以及用到的公用函数等:
1 | |
在广大网友的帮助下,整理了一百条的名人名言,整理的格式都是固定的:人名+曾经说过+一段话+这不禁令我深思,然后把曾经说过替换前面垫话,把这不禁令我深思替换成后面垫话。公用函数定义好了,最核心最精彩的部分就是生成文章的代码了:
1 | |
首先作者的思路是把一篇文章作为一个数组存起来,数组中的每个元素都是一个章节,这里的章节可以理解为一个自然段,是文章的基本组成部分;最后再把整个数组通过div拼接起来。其中,最重要的就是如何来生成一个章节。
刚开始我对for(let 空 in 主题)这个遍历感到十分困惑,主题很好理解是一个字符串,但是将字符串中每一个字符遍历出来有什么作用么?经过多次debug,猜测其实是为了多生成几次章节,凑字数而已;原本6000字,经过多次遍历,实际可能会远超6000字,达到好几万的字数(6000*主题字数);因此在suulnnka改版后的函数中,也将这段代码优化成了while( 文章长度 < 12000 ),控制整篇文章的字数略大于12000字。
随便取一个数函数用来生成一个0到100的随机数,首先让我们看一下随机数 < 20的情况,也就是15%的概率(20-5)用来在章节中添加一句名人名言;然后80%的概率(100-5-15)用来在章节中添加一句论述;最后我们回到最难理解的随机数 < 5的情况,也就是5%的概率来将这段章节给结束掉,通过把章节最后两个字符截取替换成句号,然后把章节push到文章中,最后把章节变量的内容给清空了。
通过对源码的分析,我们看出作者的方法确实很简单有效,通过预存的名人名言和大段论述来生成文章;也正是因为简单,所以整个生成出来的文章重复率偏高了;因此作者也意识到这个问题,在项目中明确表示下一步计划是防止文章过于内容重复。
广大网友还在此基础上开发了日语版的和嘴臭版的(LOL喷人神器?),更有网友调侃李小璐离婚宣言都是用这个项目生成的。
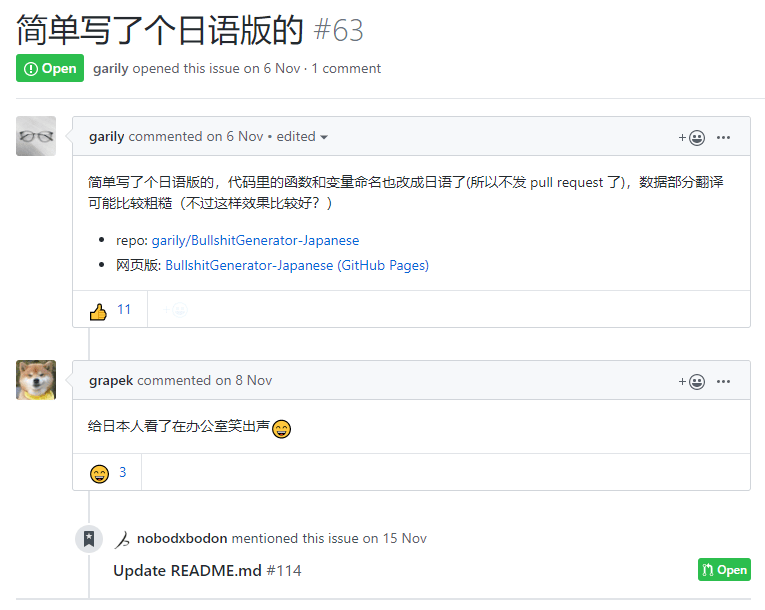
除此之外,我们还发现项目中的代码使用了大量的中文函数名和中文变量,这也是我第一次知道了编程中还能使用中文变量名,太硬核了。作者也在项目中表示,使用中文变量名只是因为懒得切英文输入法,于是,分支作者还特地帮忙把漏网的英文变量名,也给改成了中文。
本网所有内容文字和图片,版权均属谢小飞所有,任何媒体、网站或个人未经本网协议授权不得转载、链接、转贴或以其他方式复制发布/发表。如需转载请关注公众号【前端壹读】后回复【转载】。