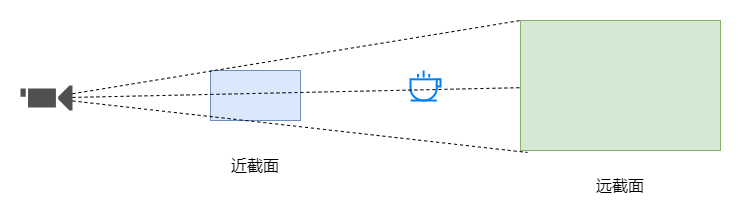
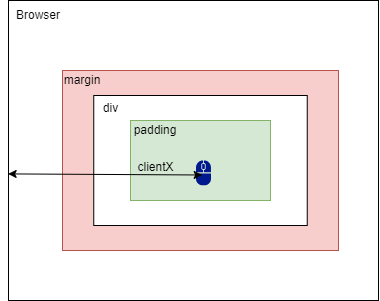
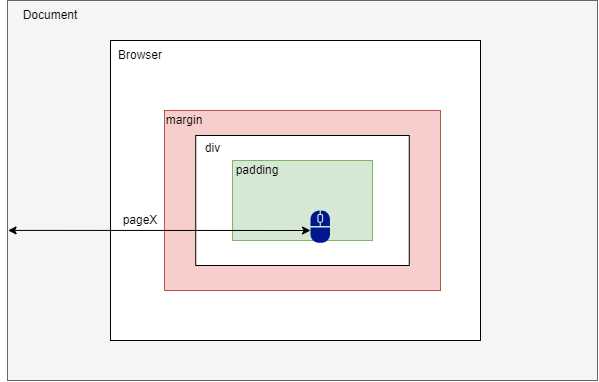
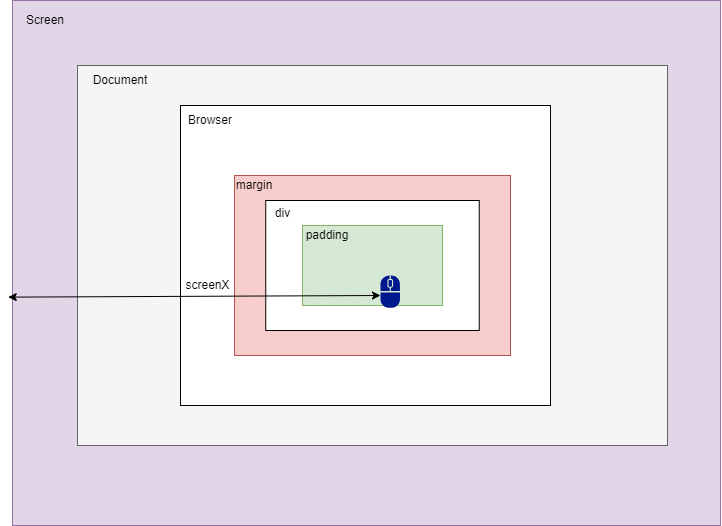
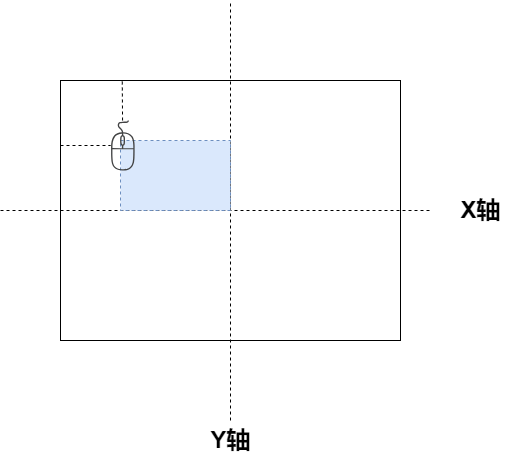
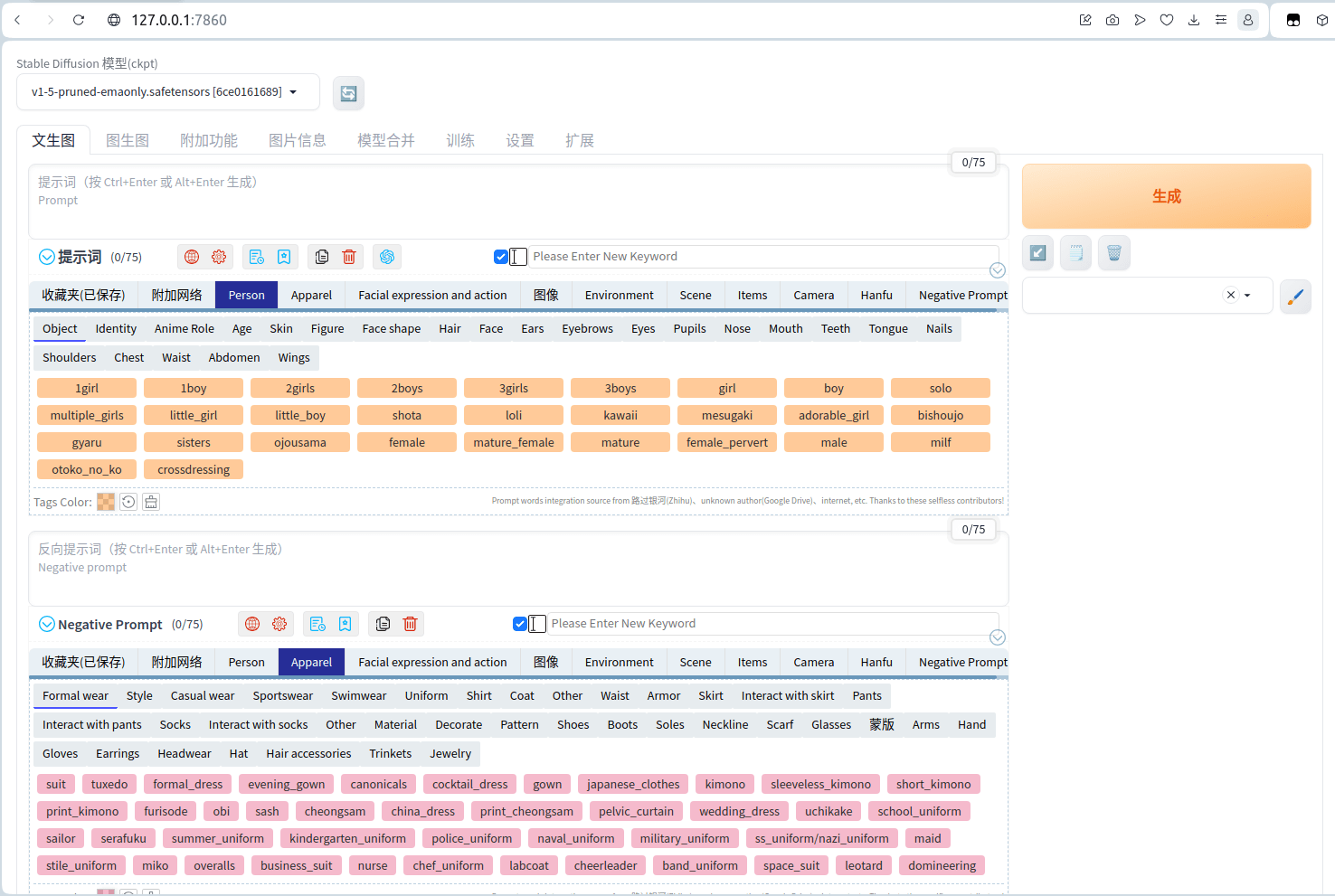
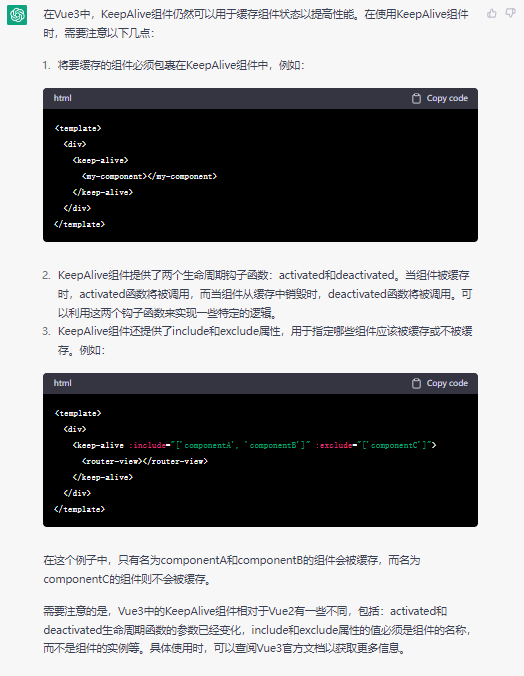
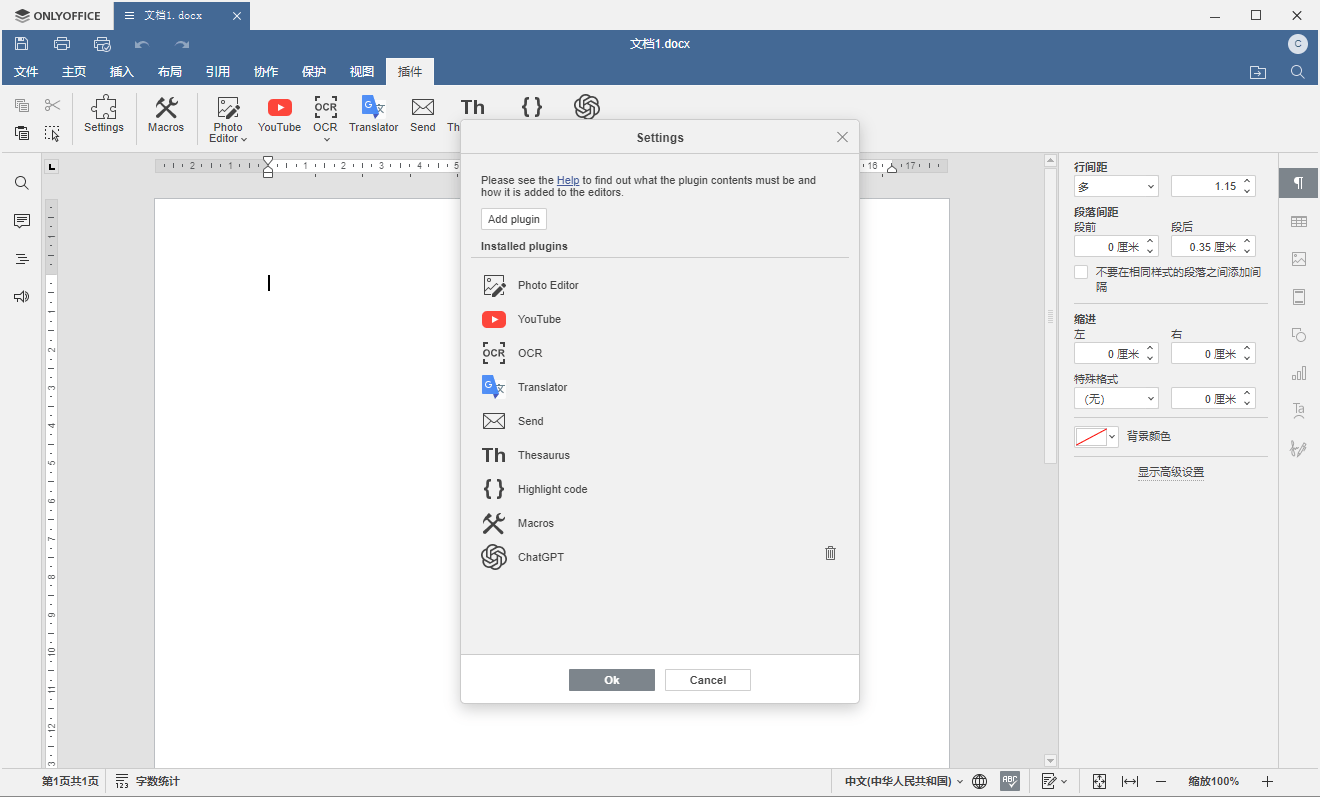
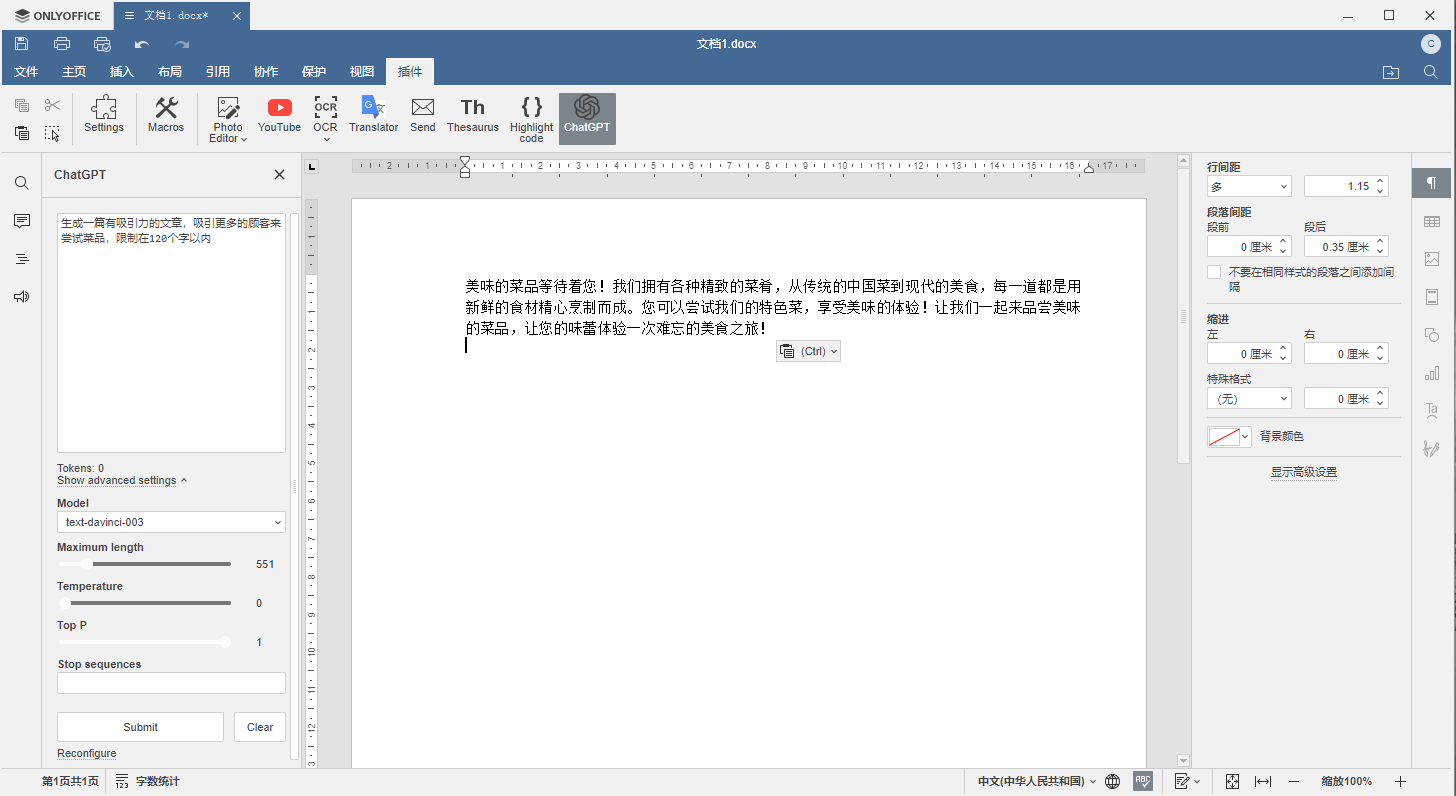
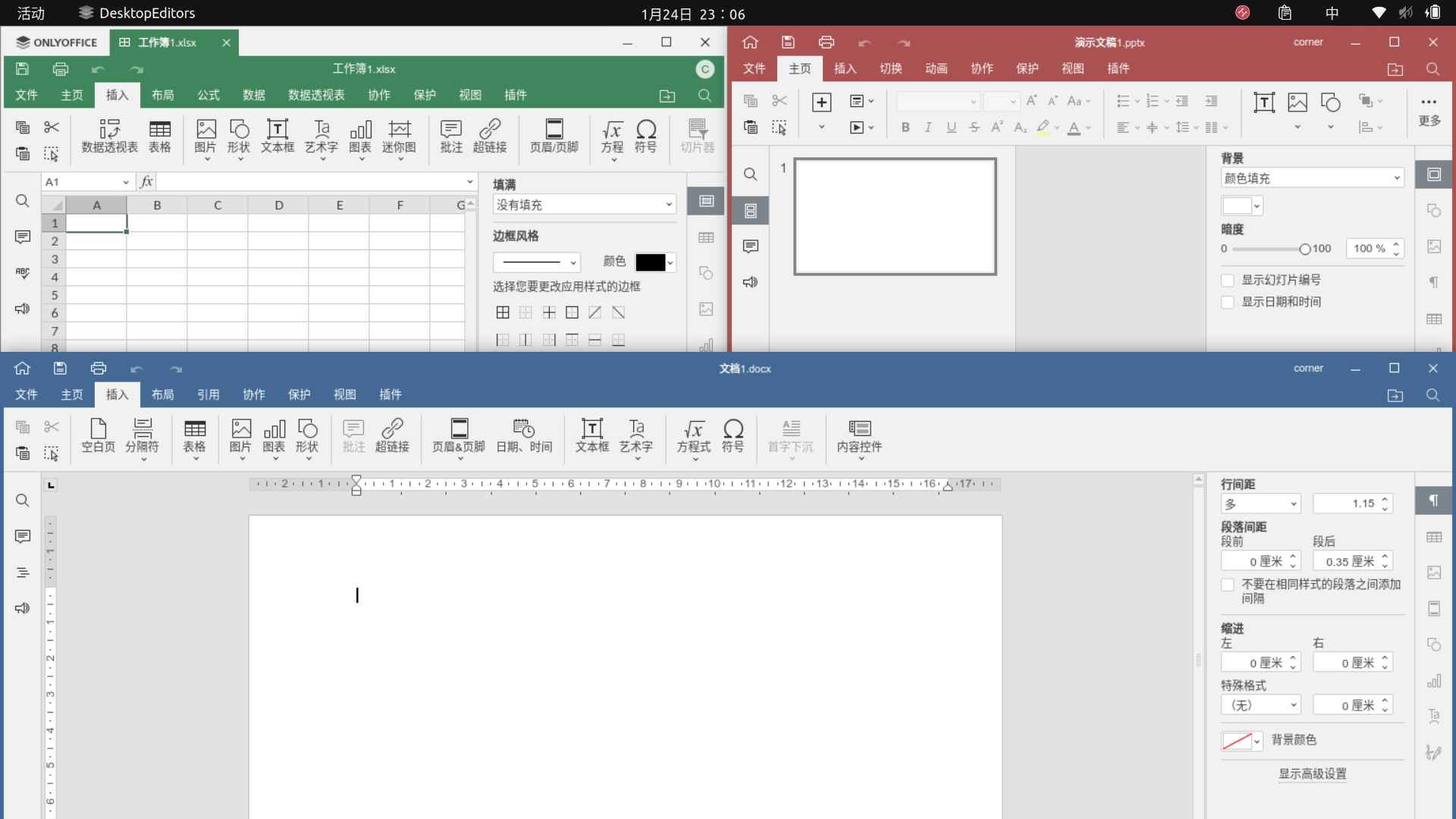
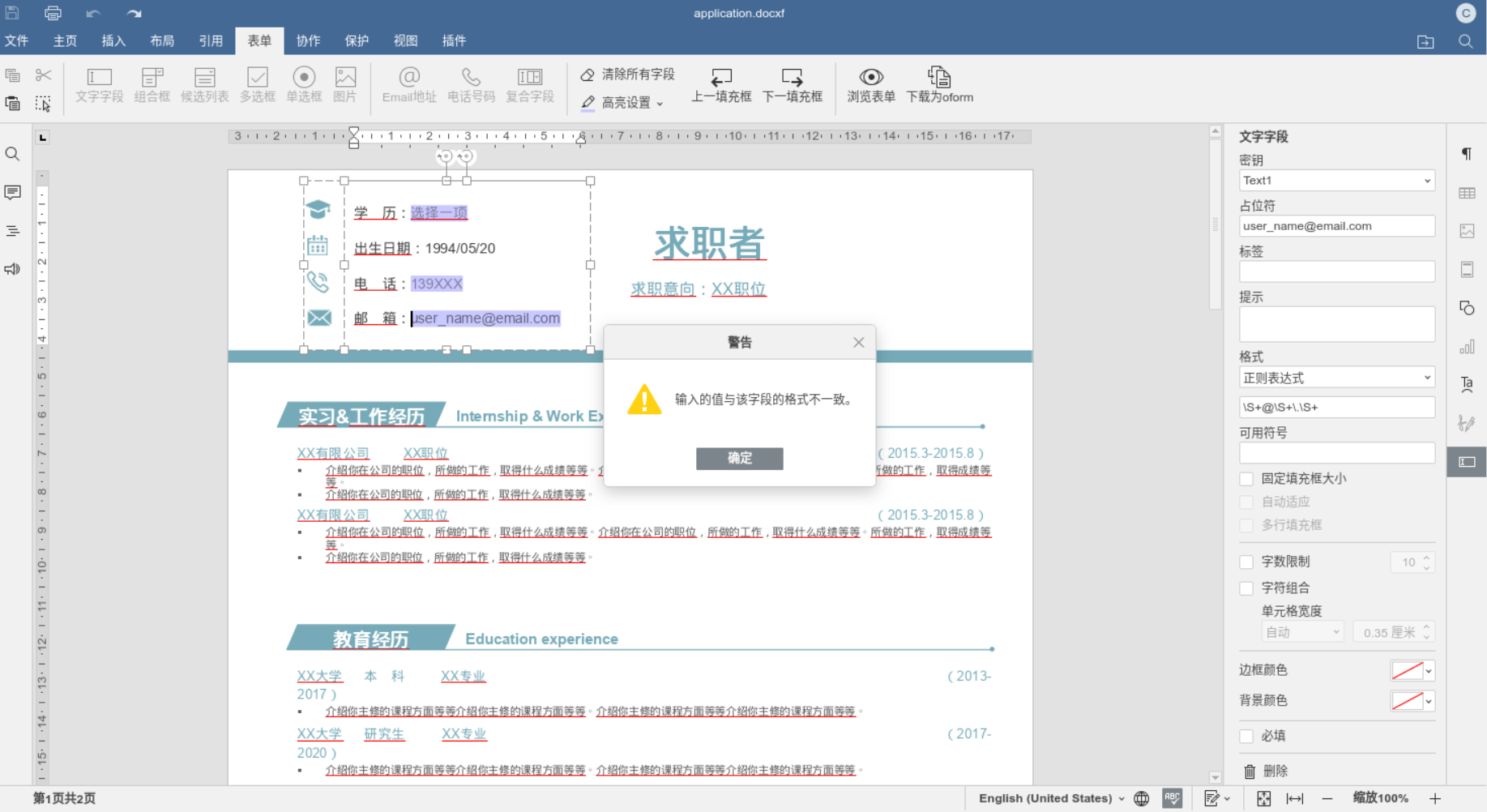
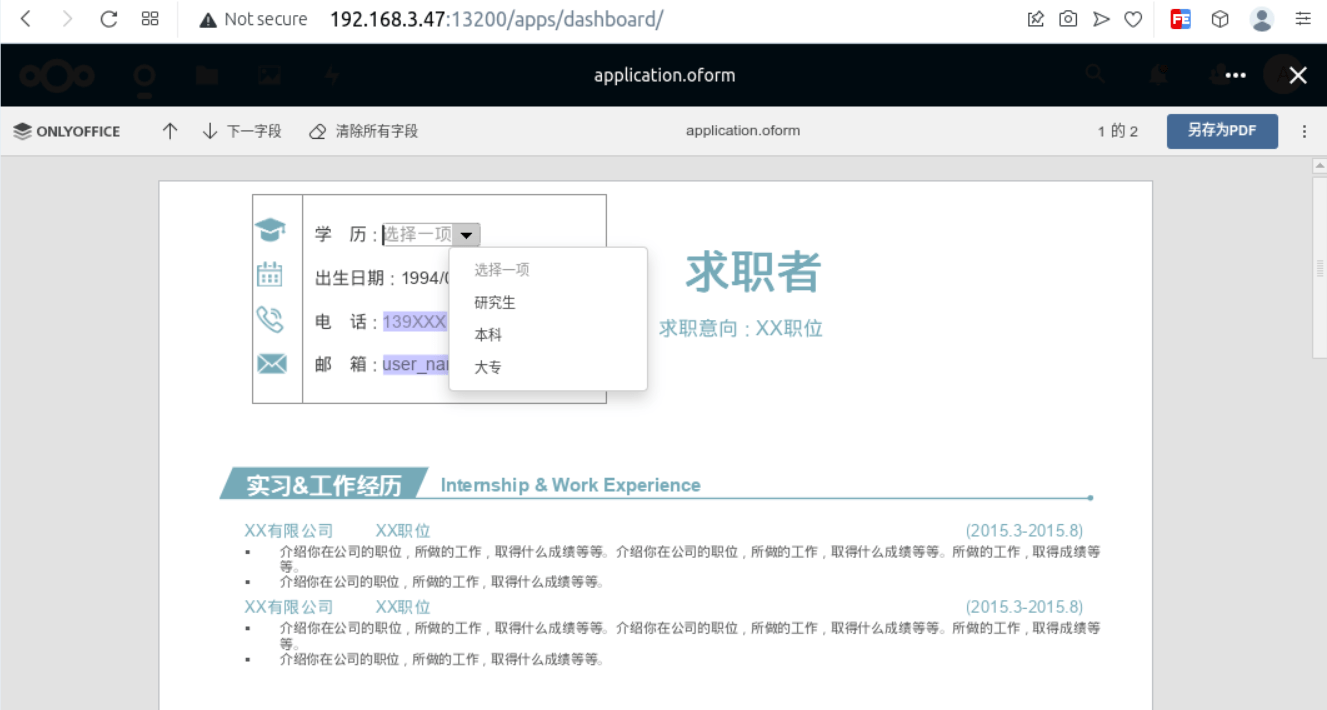
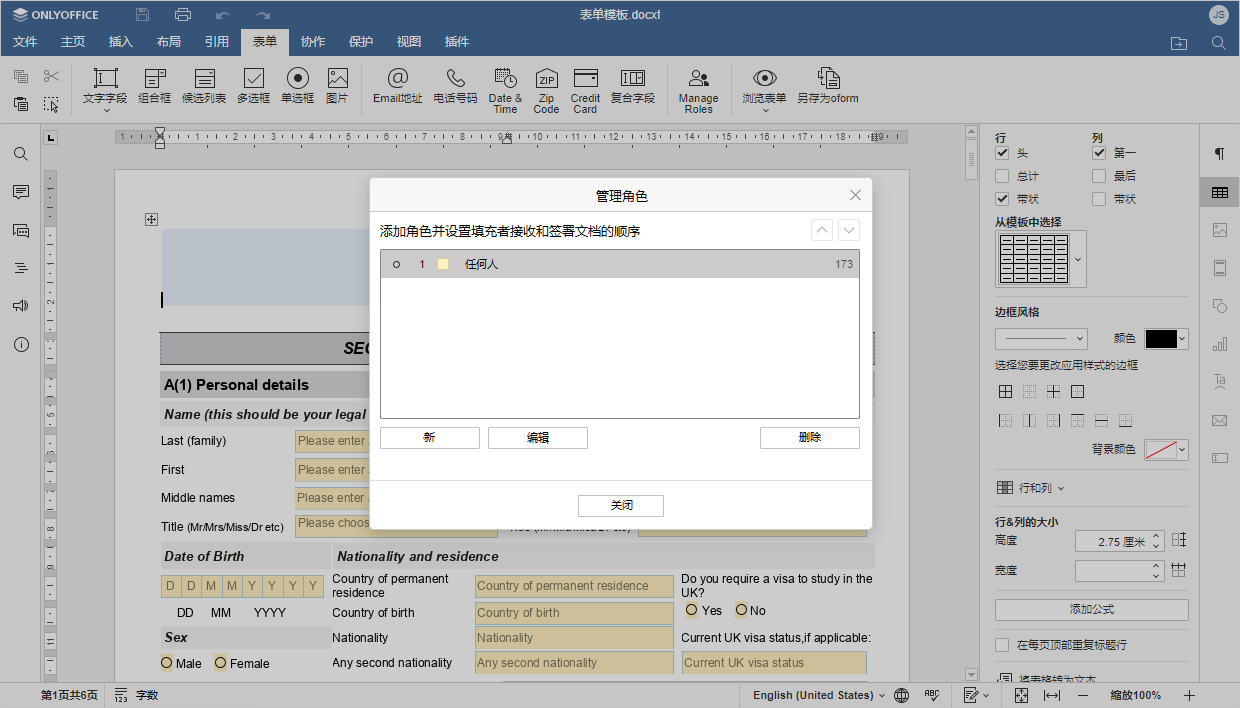
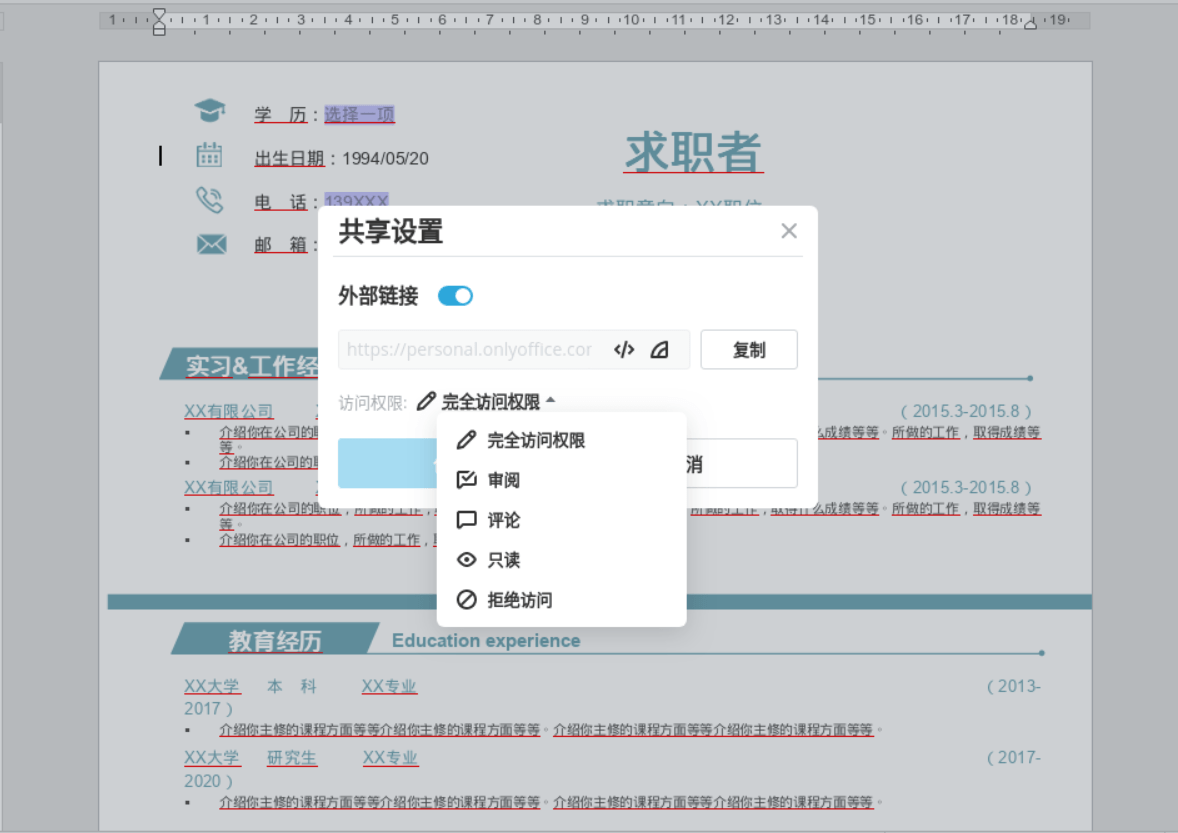
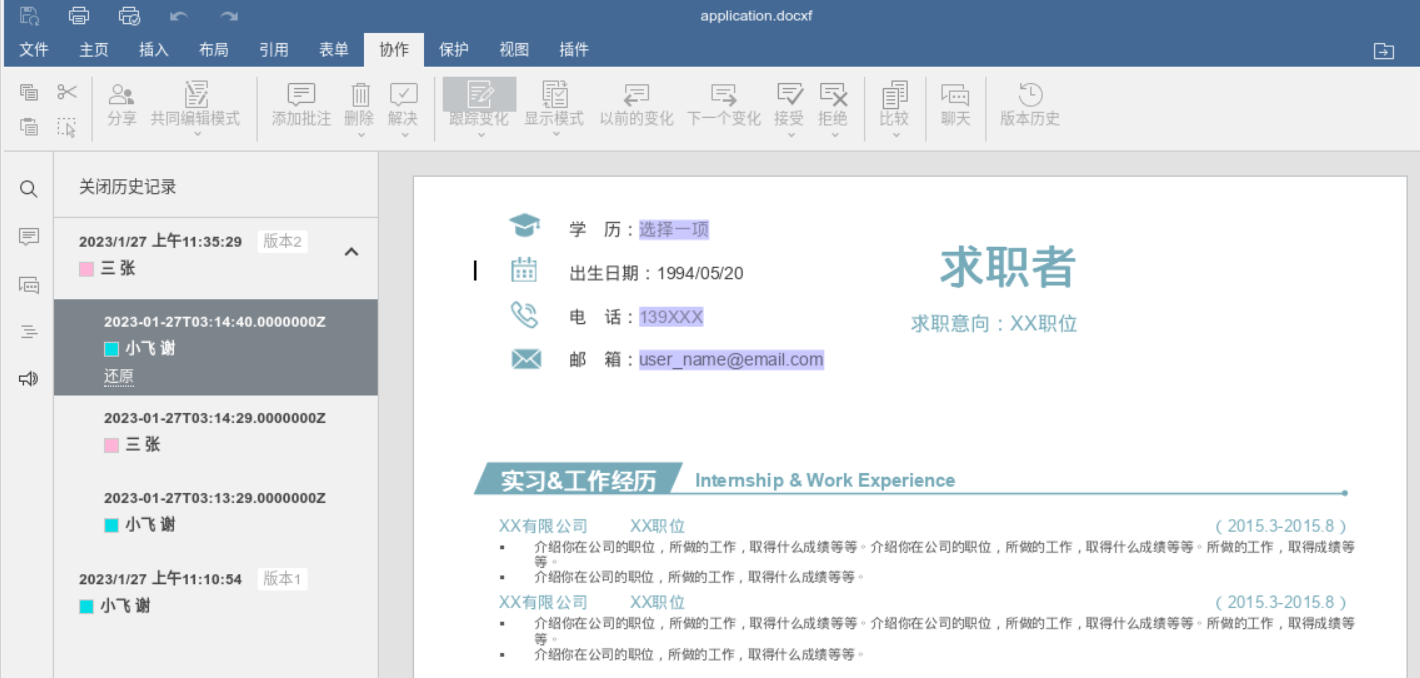
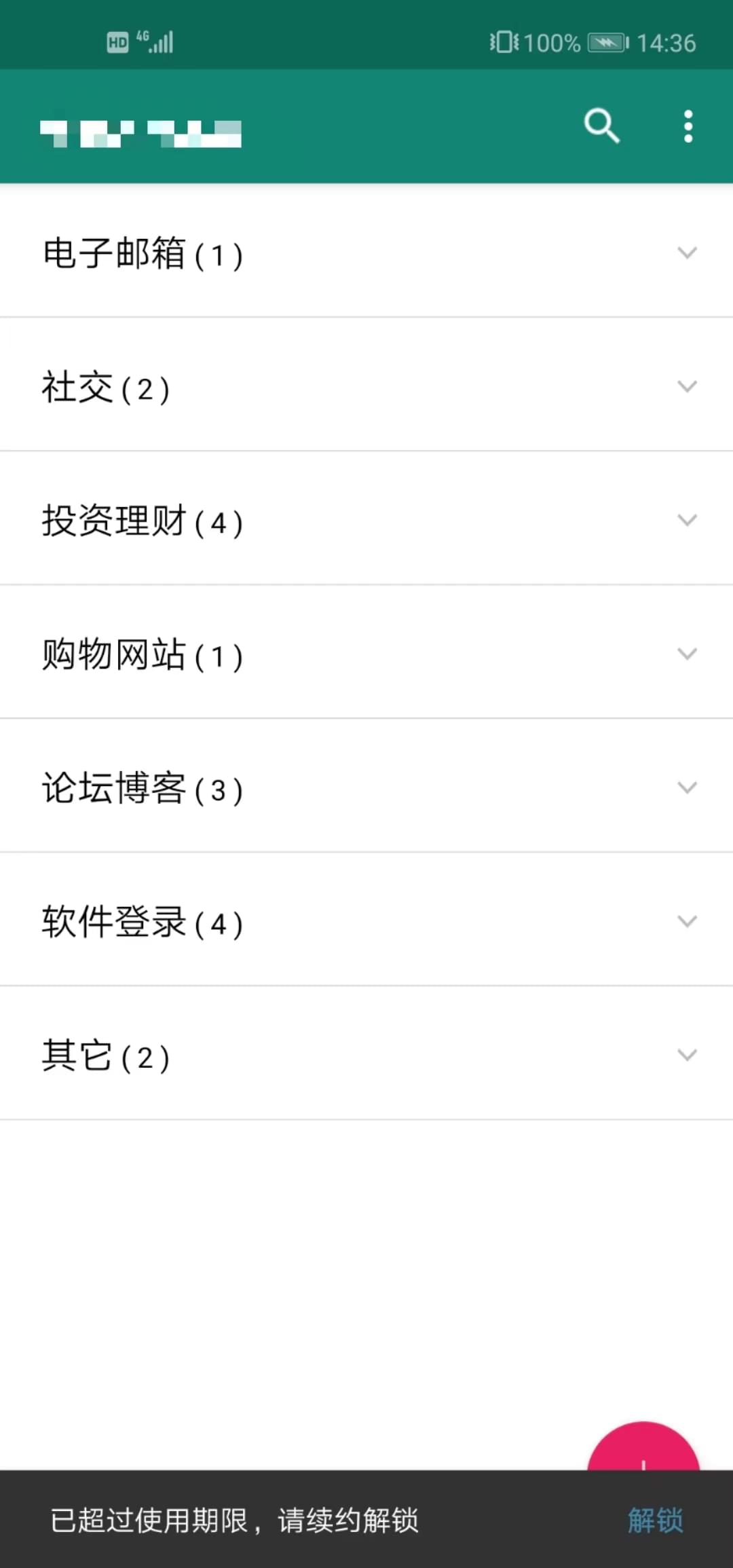
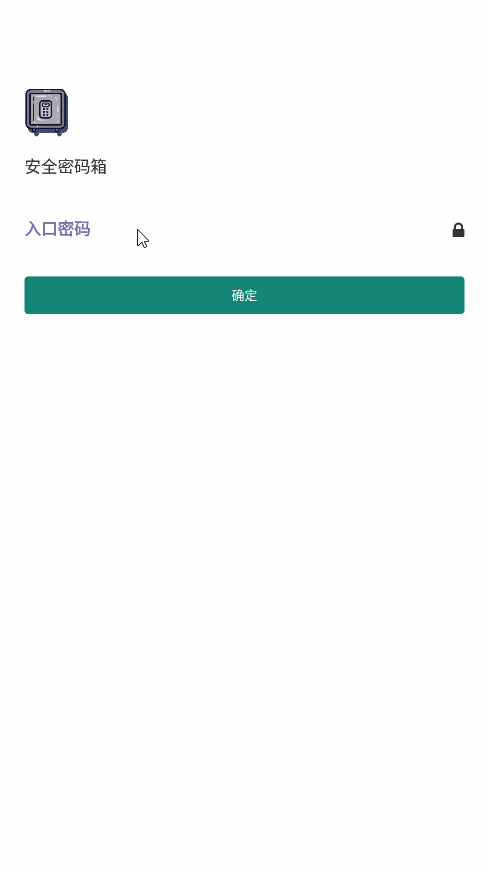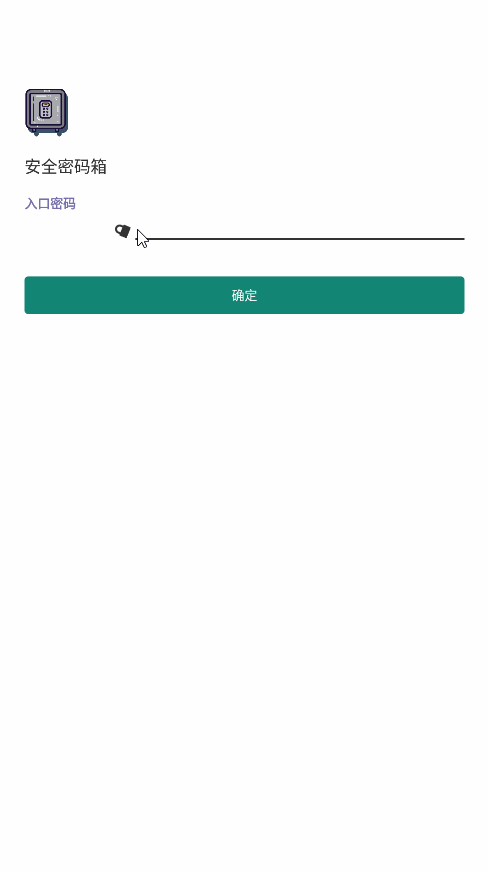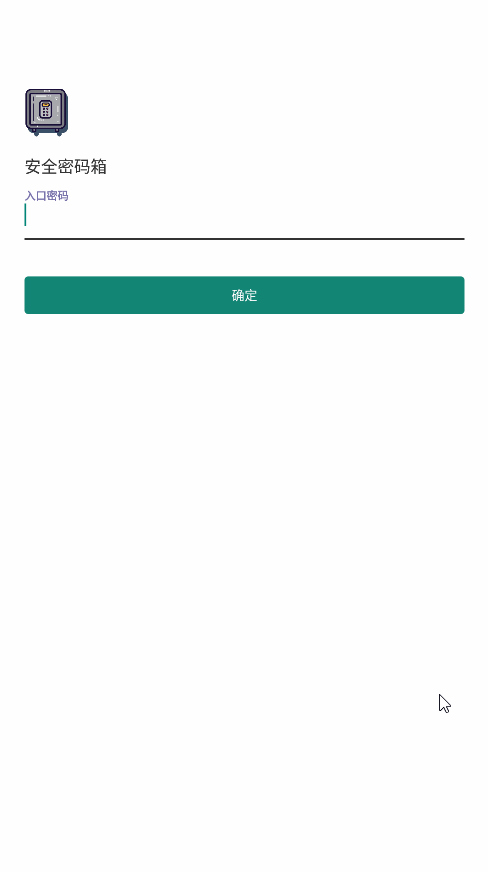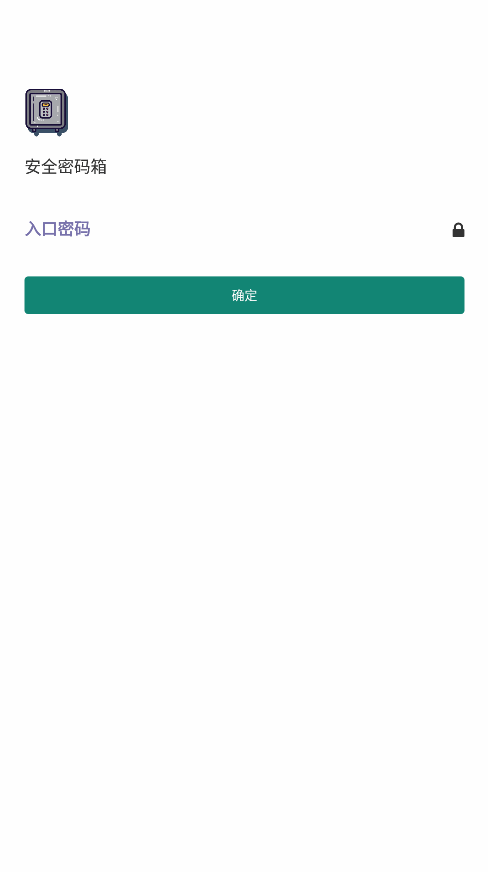
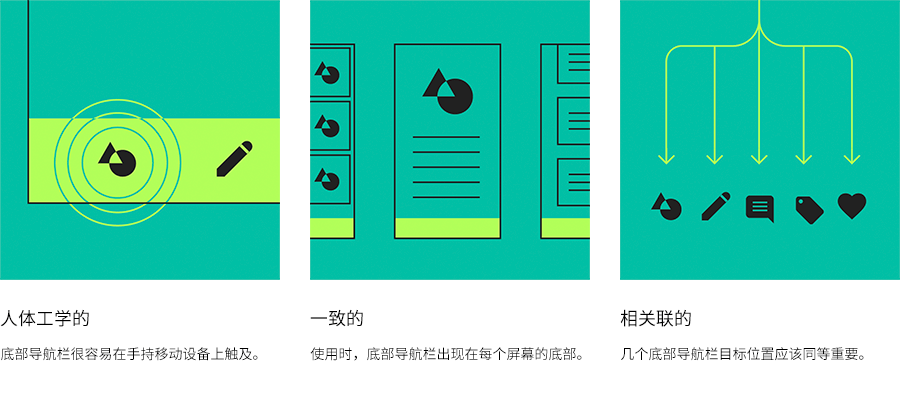
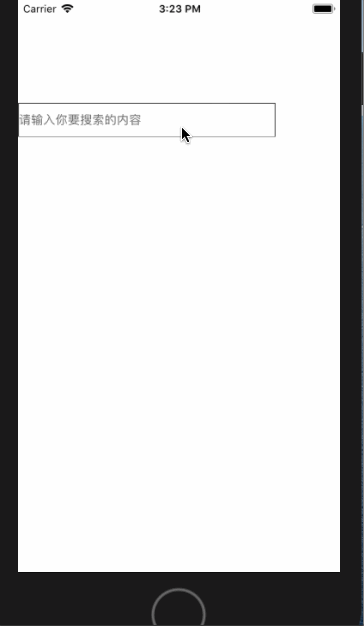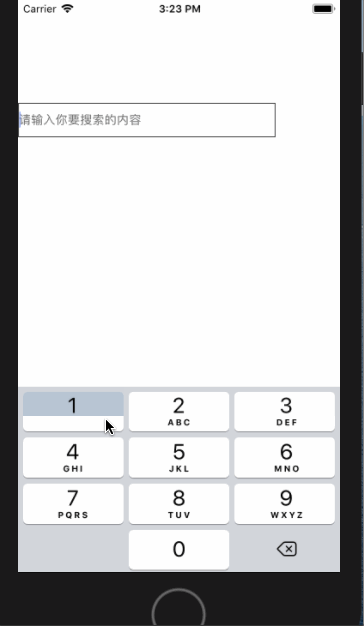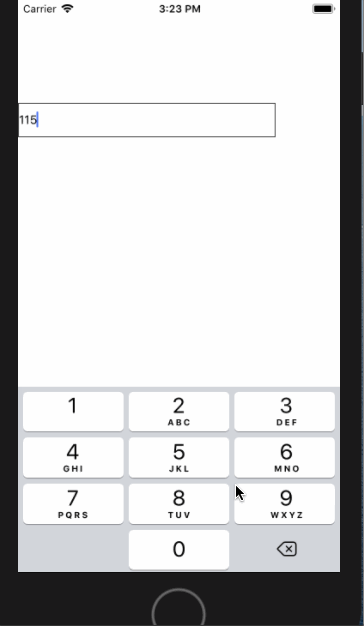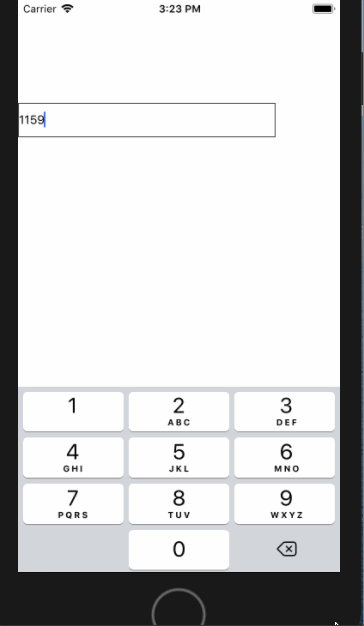
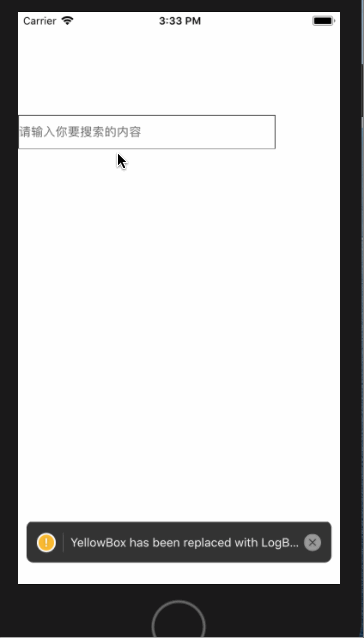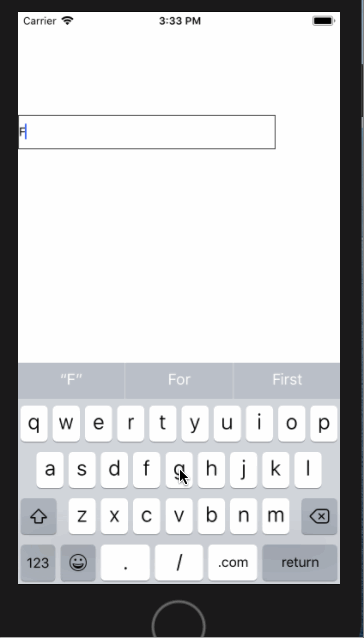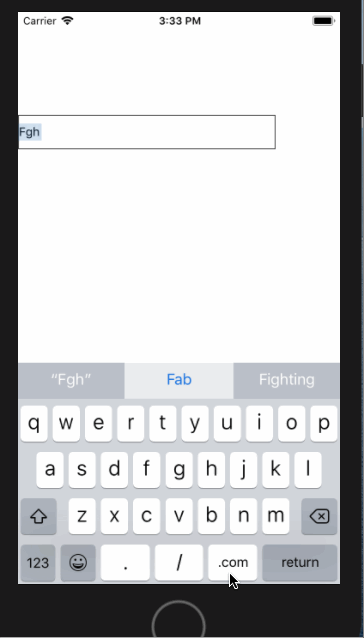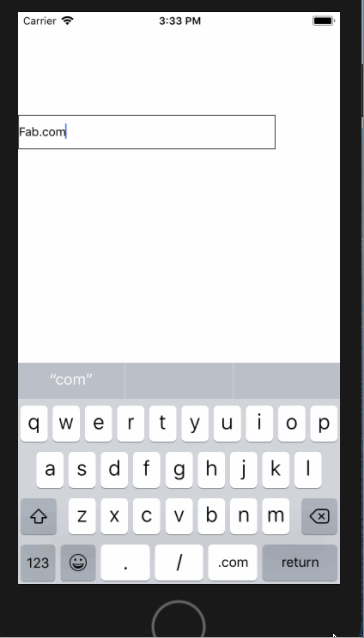
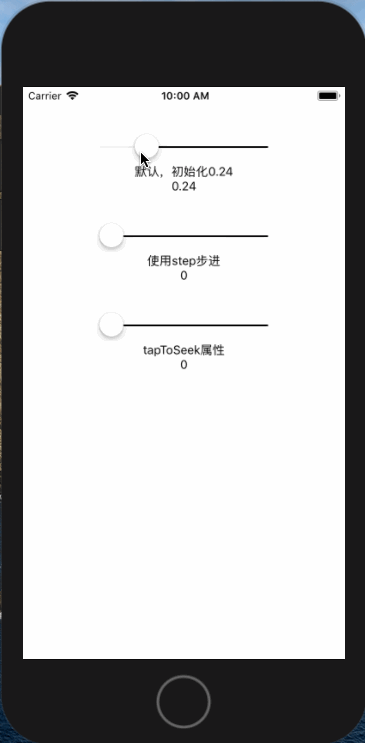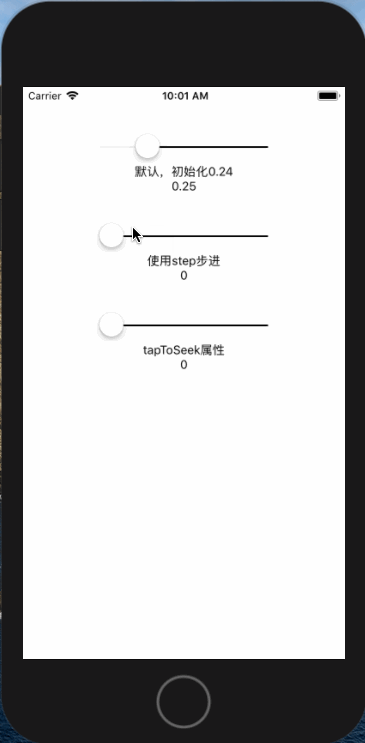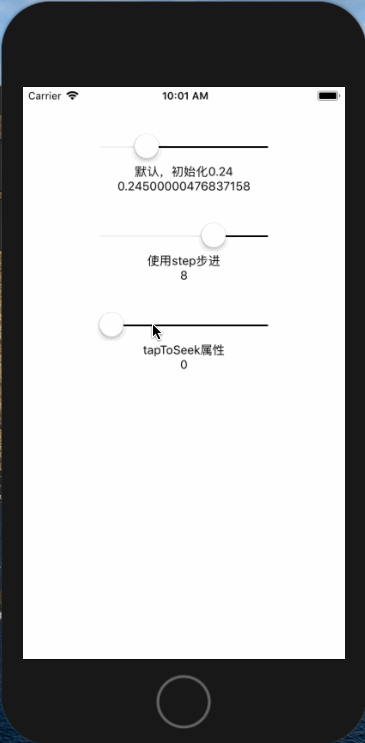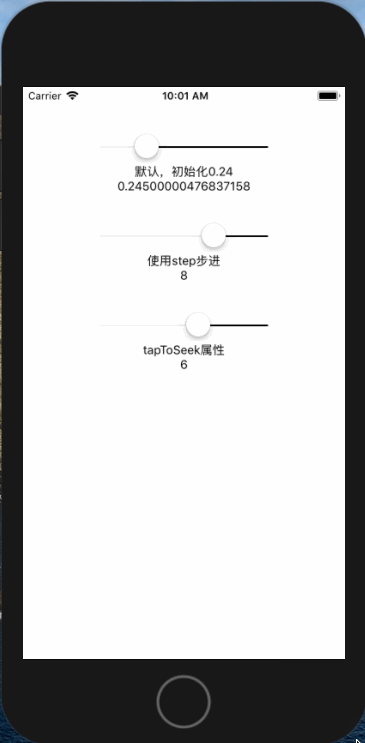
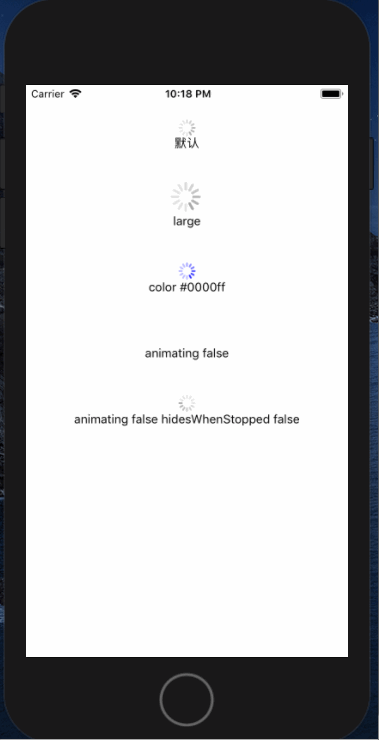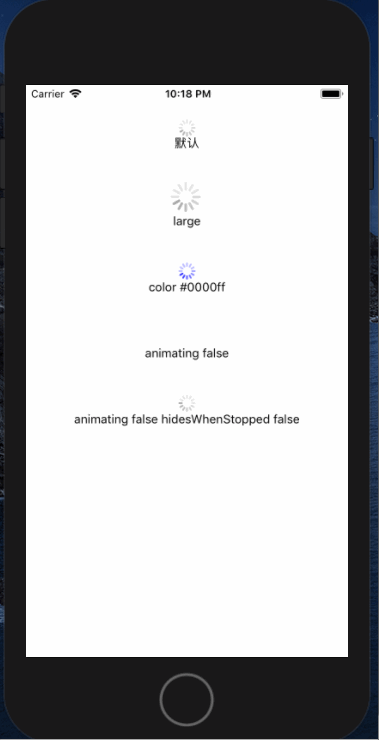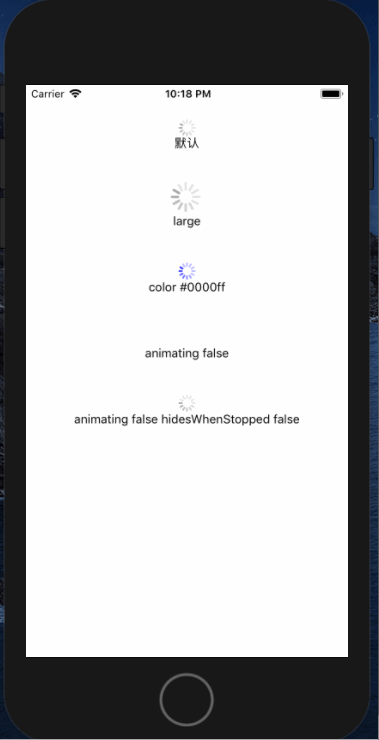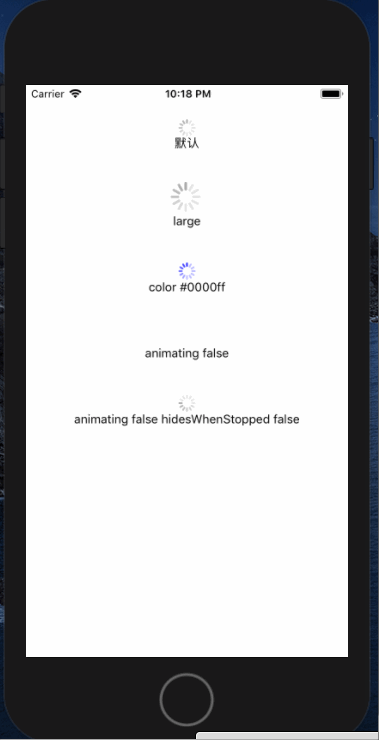
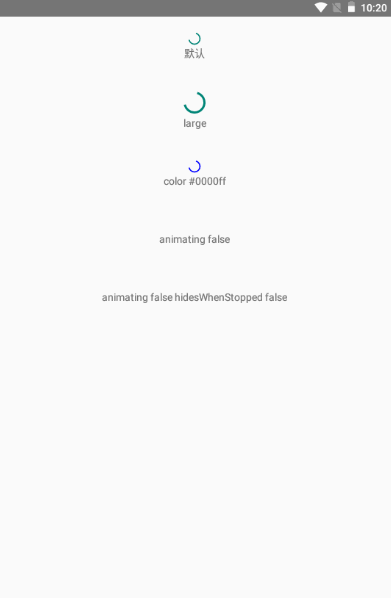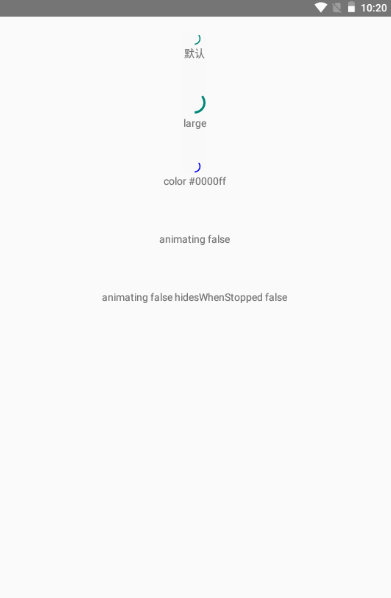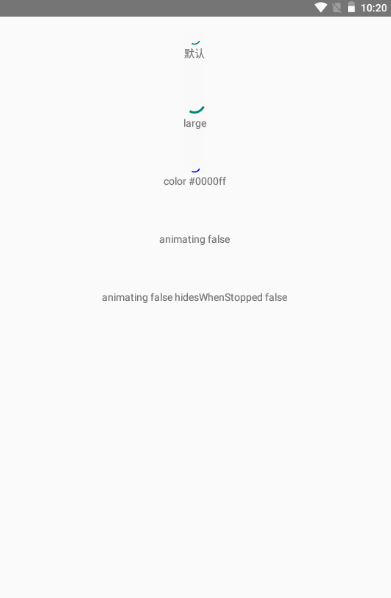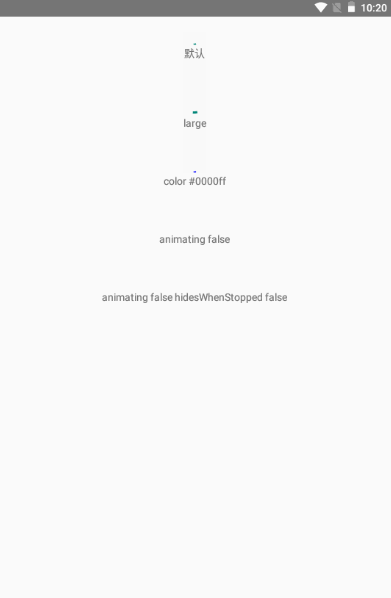
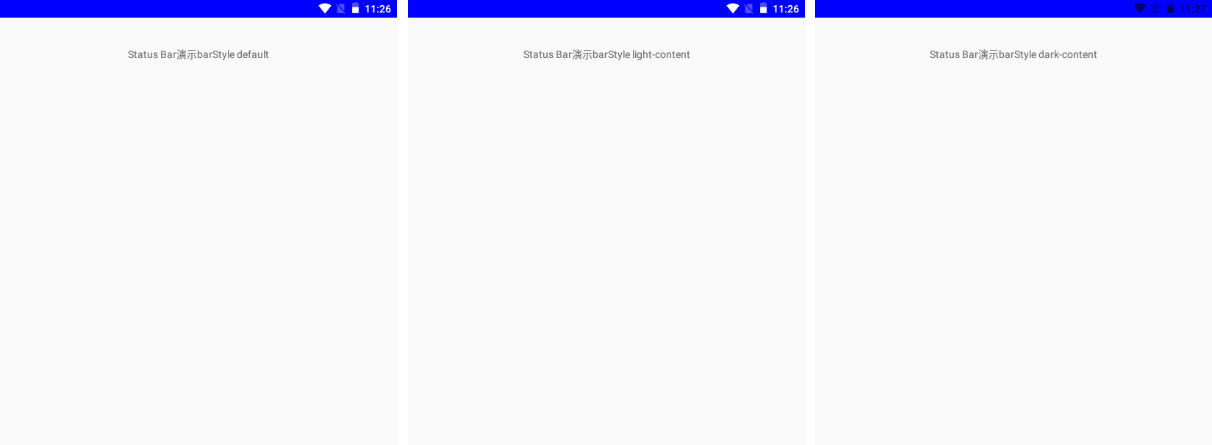
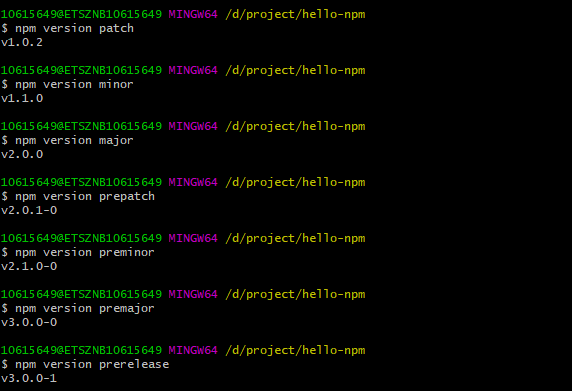
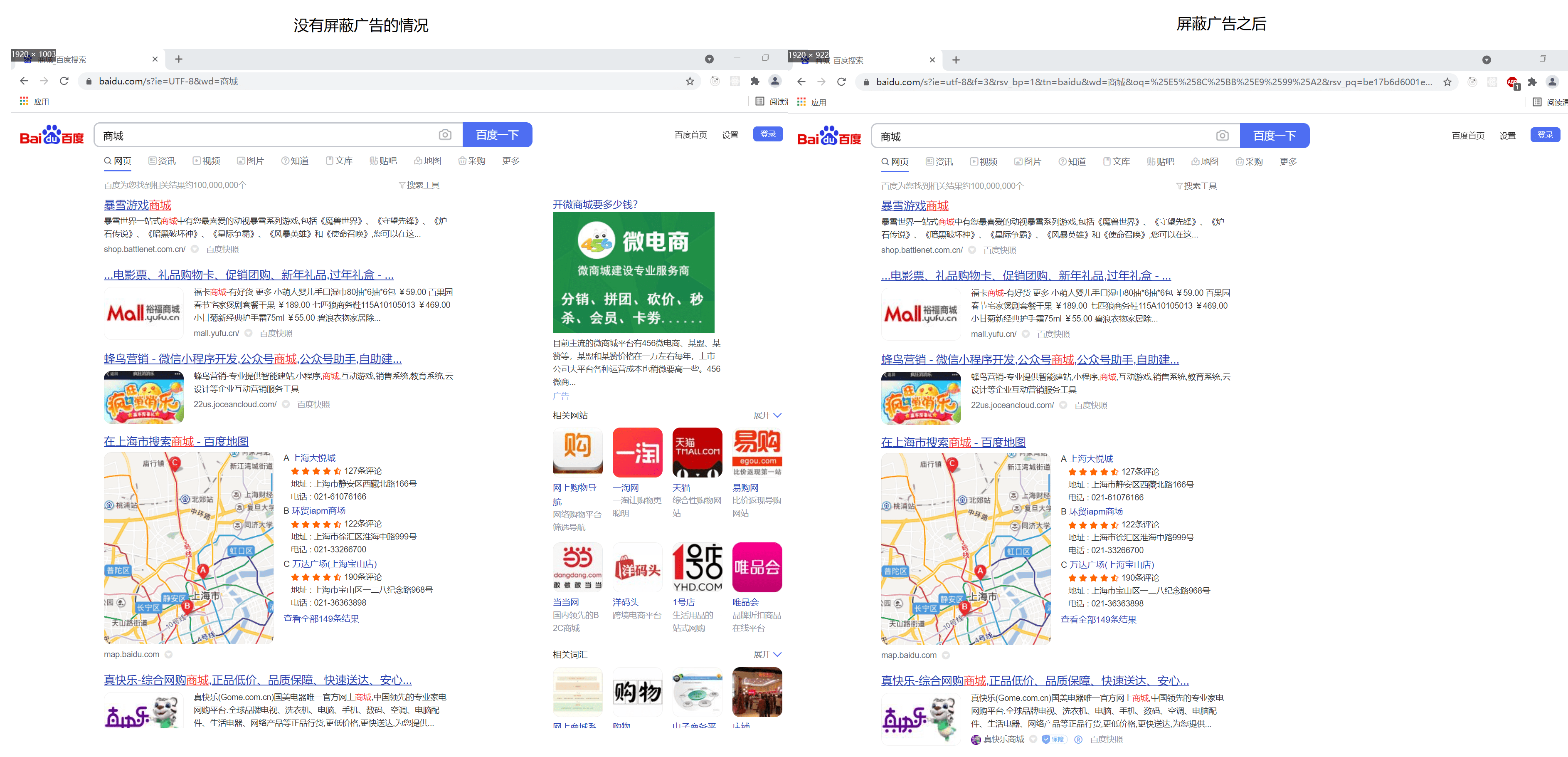
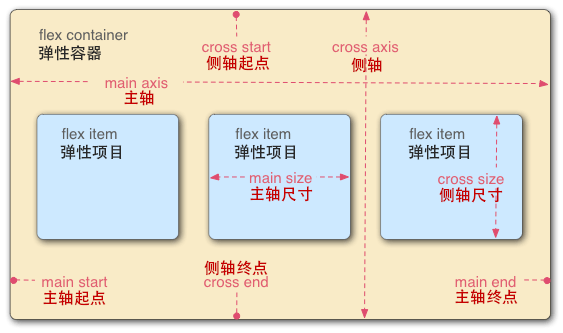
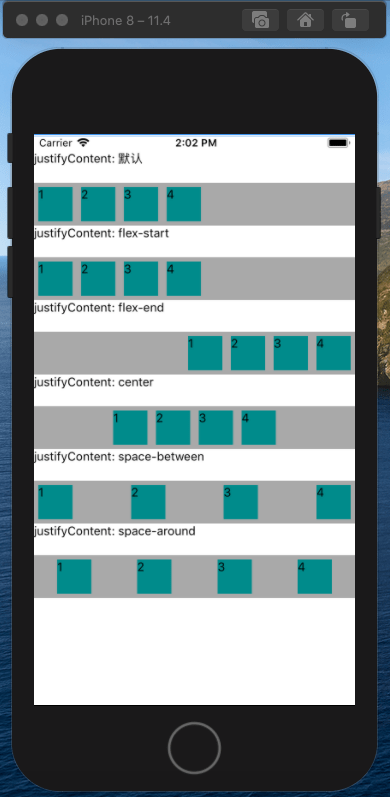
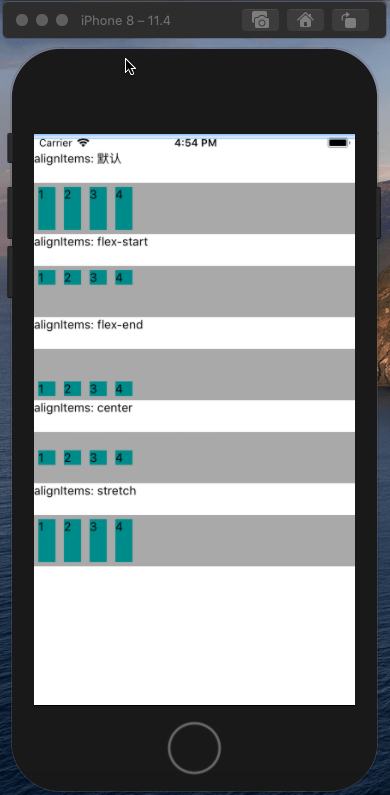
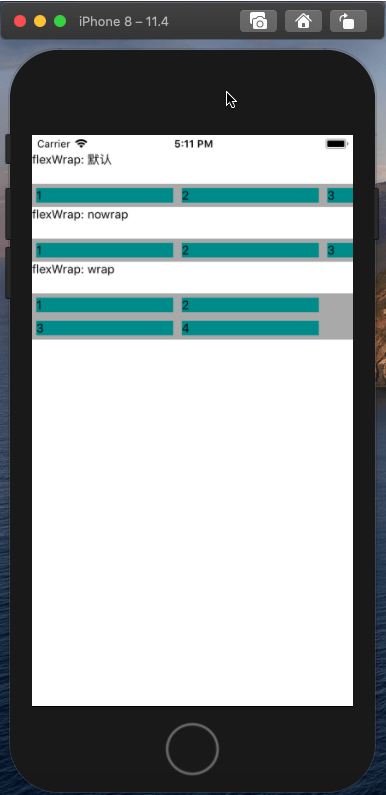
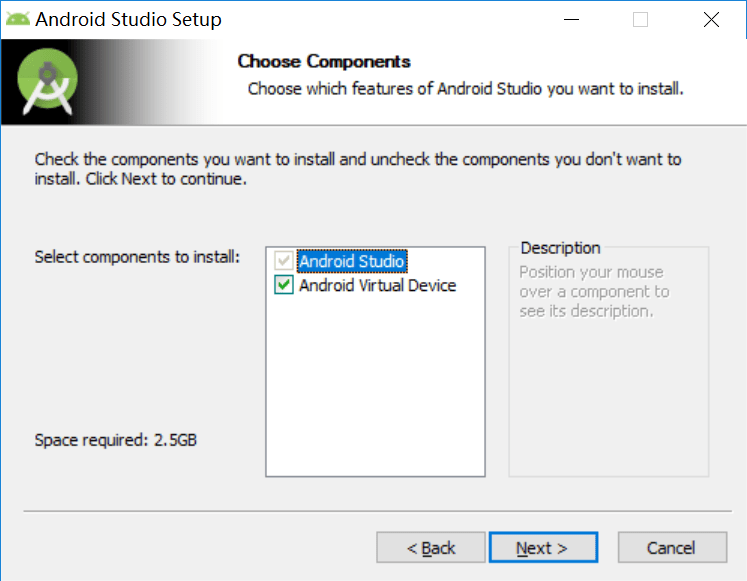
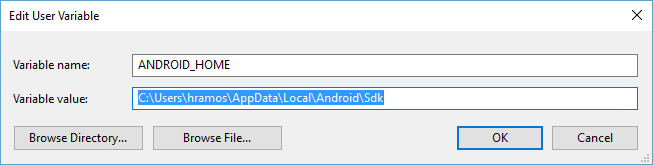
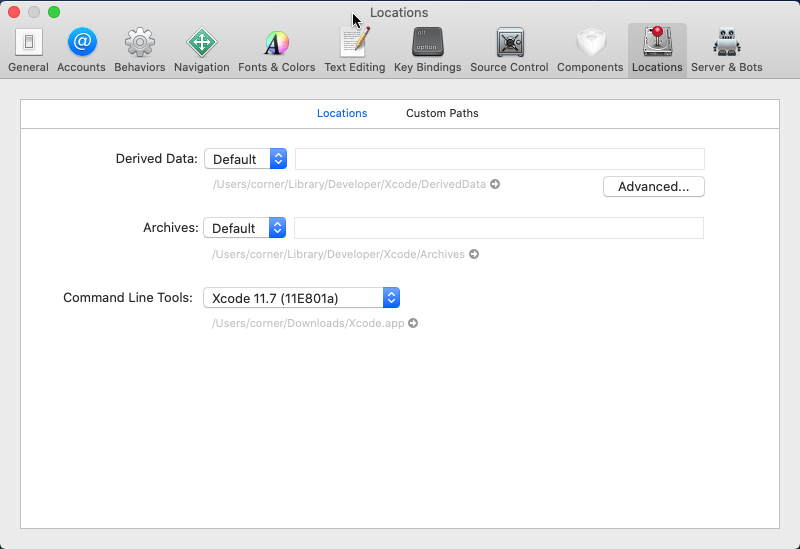
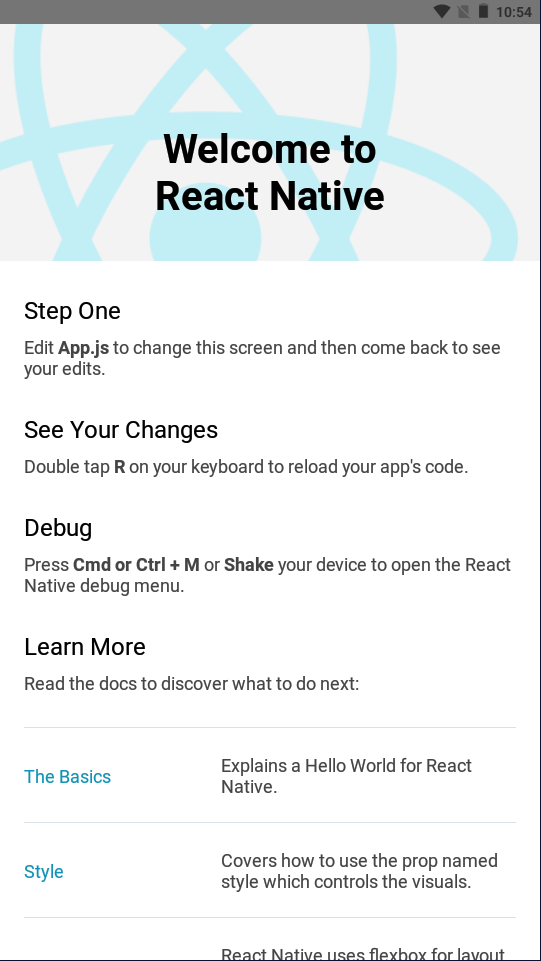
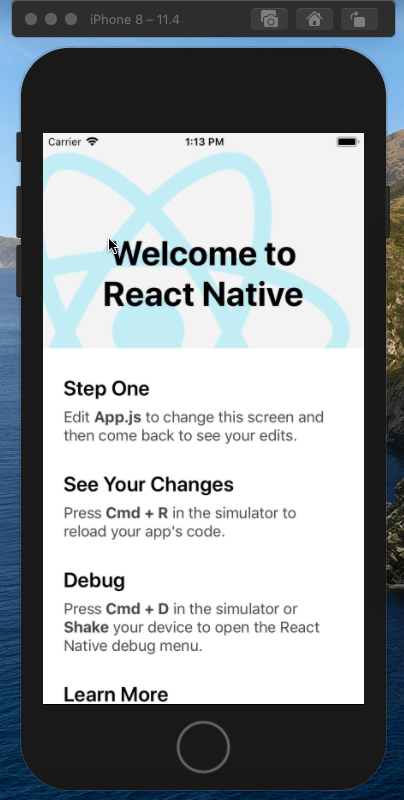
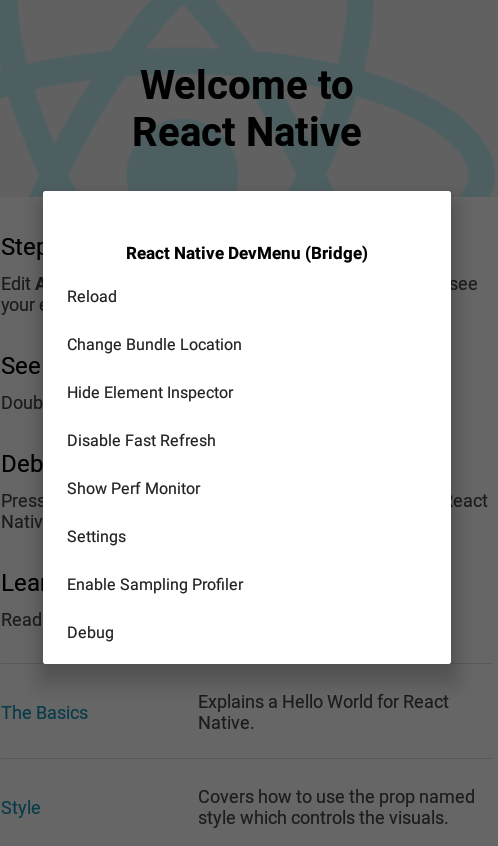
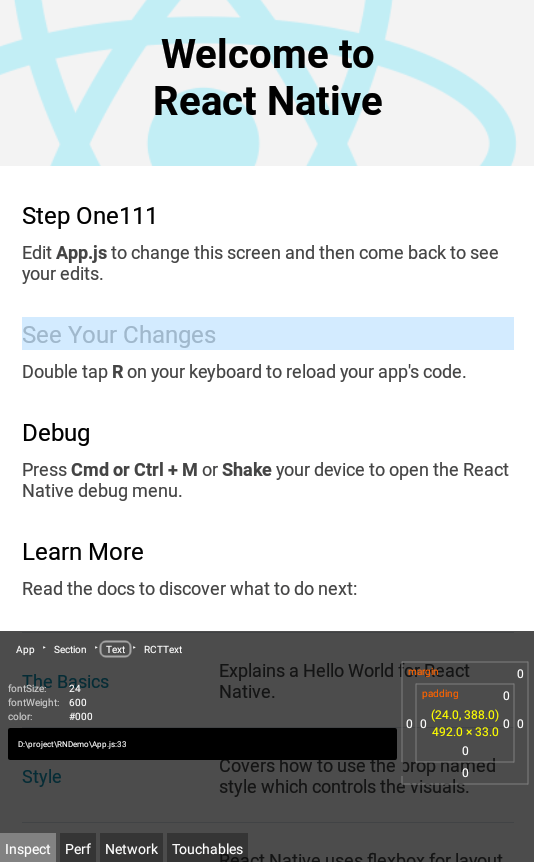
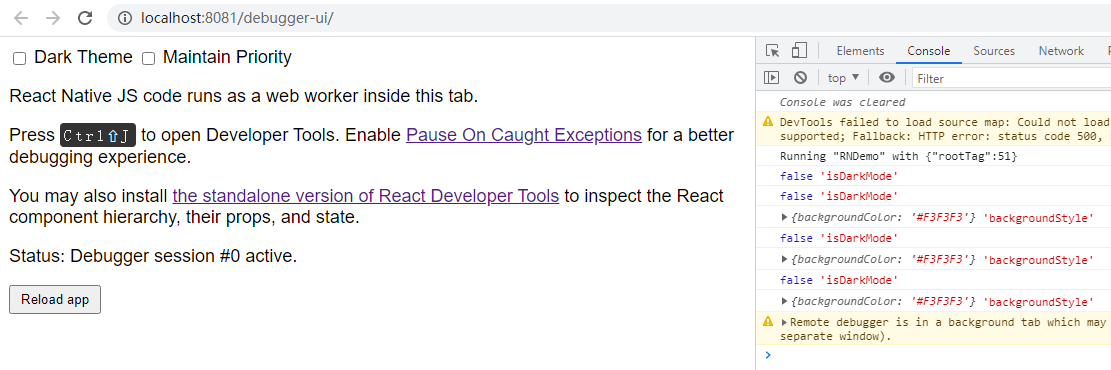
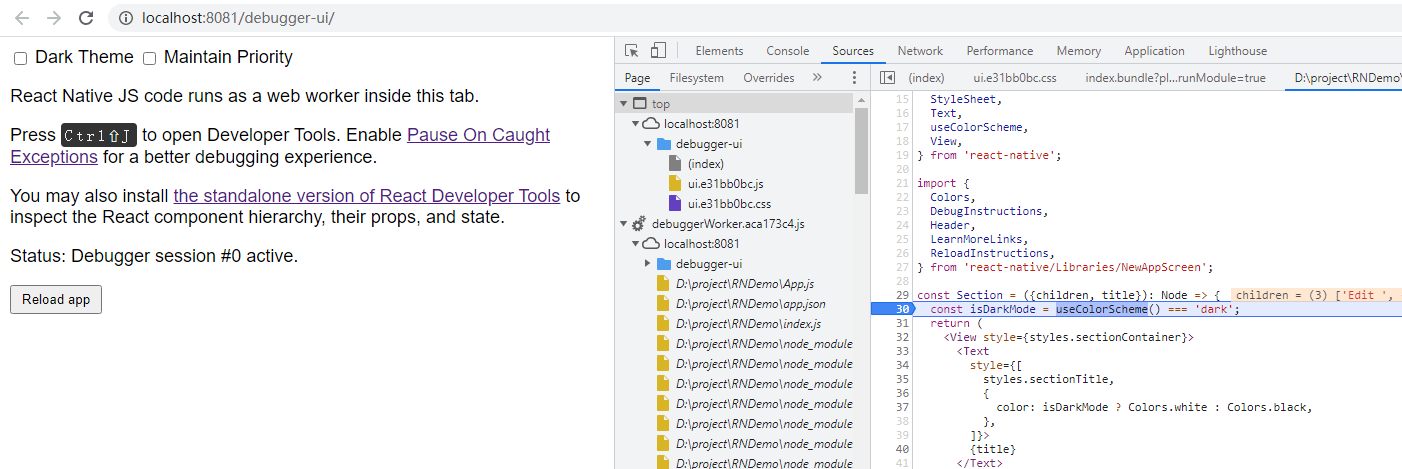
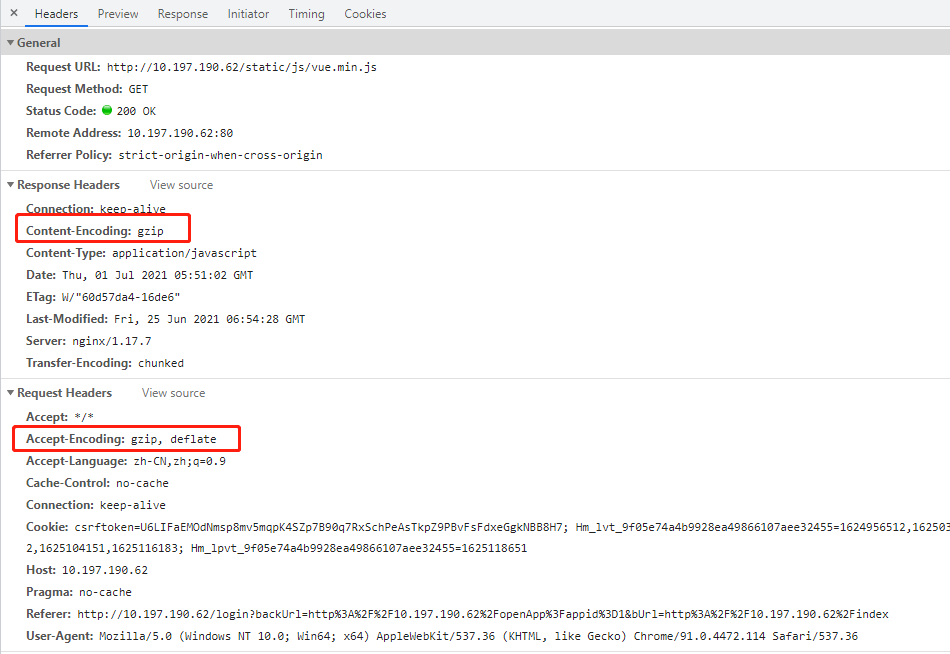
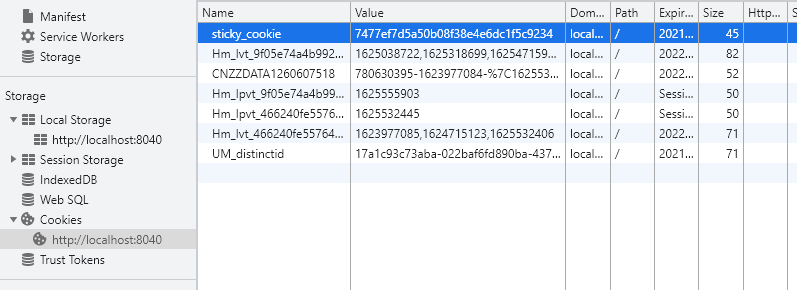
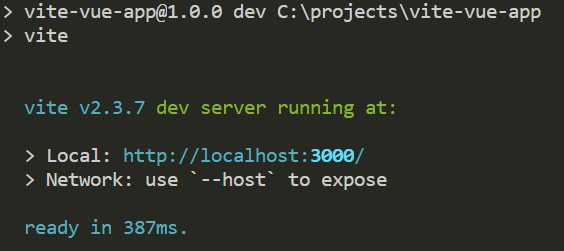
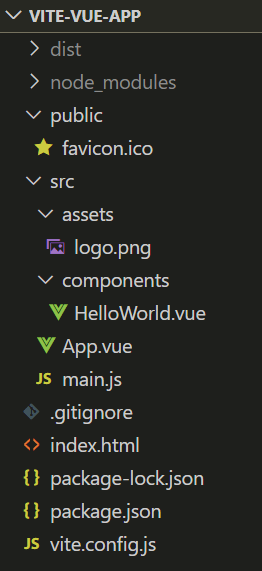
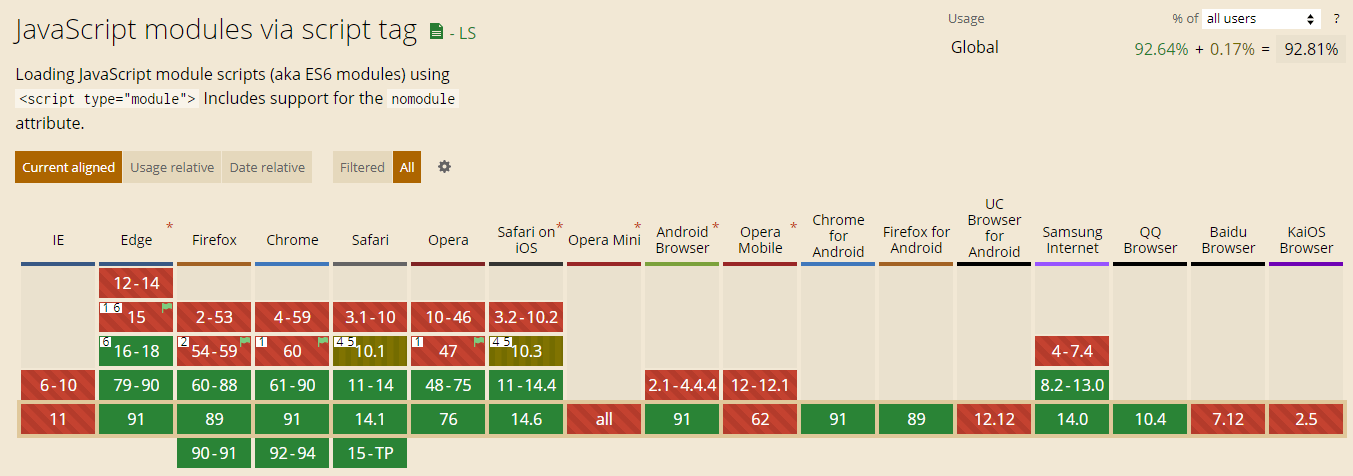
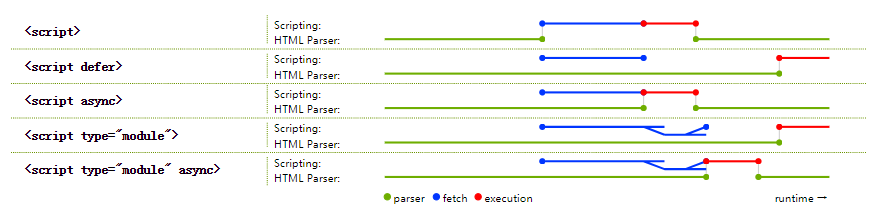
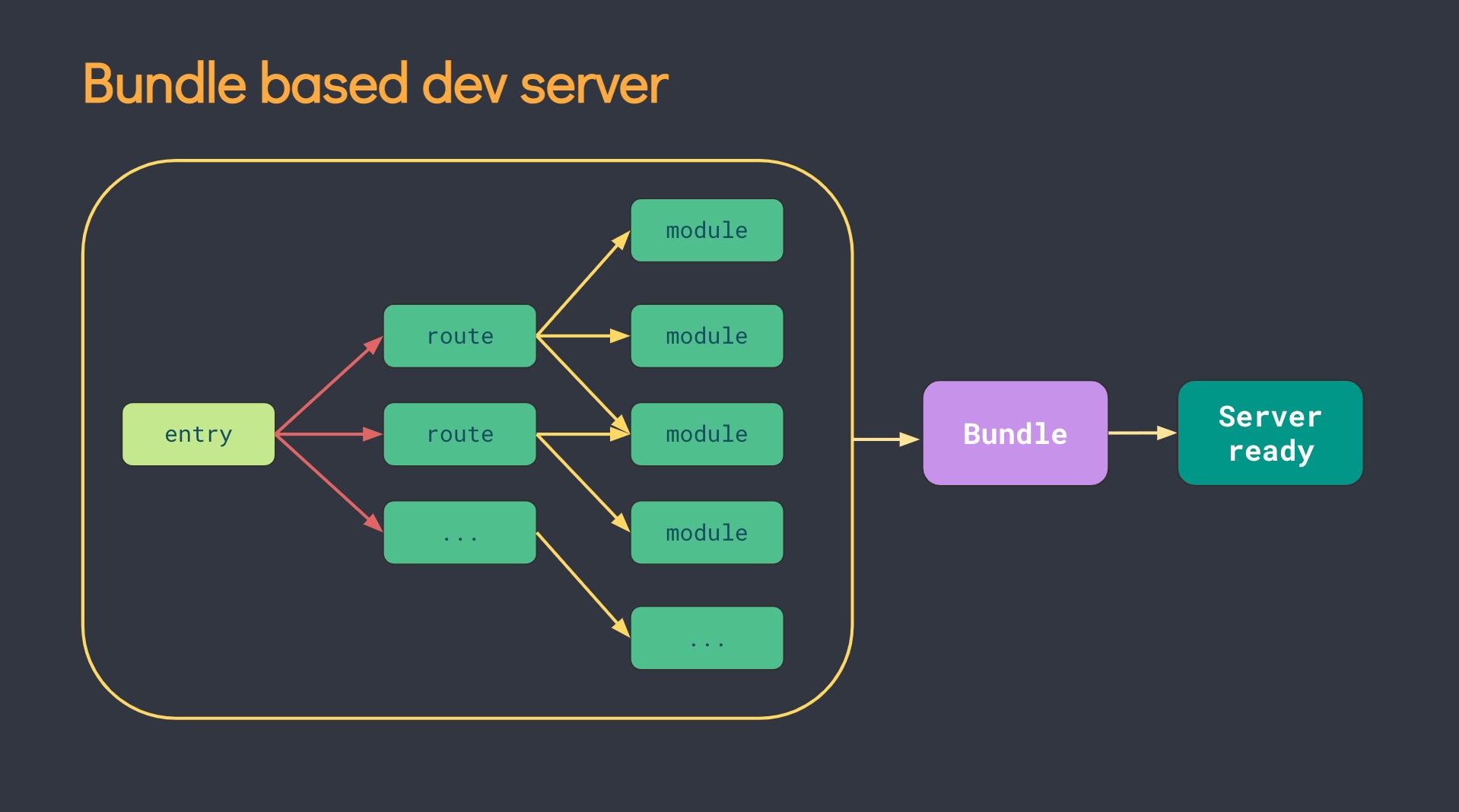
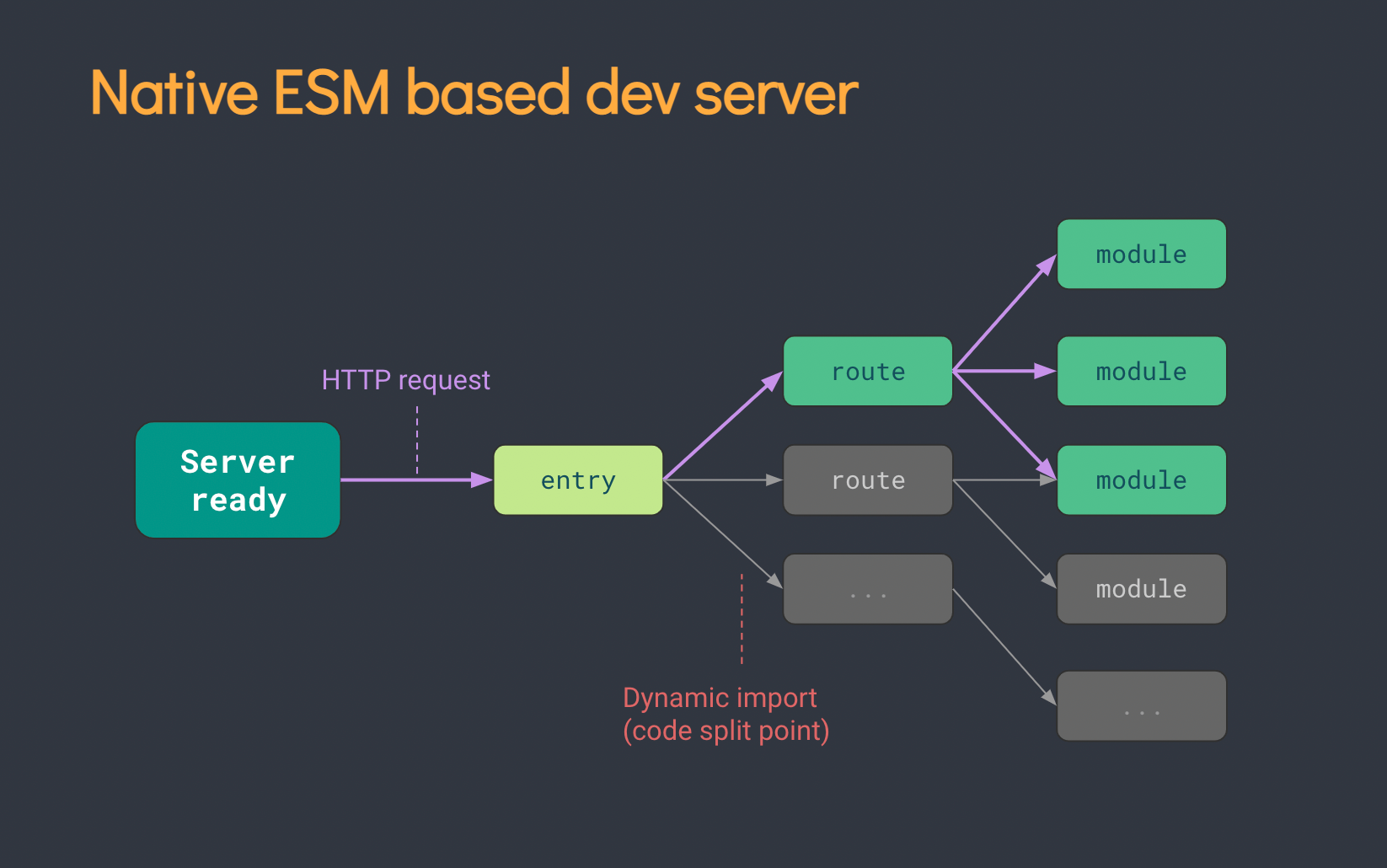
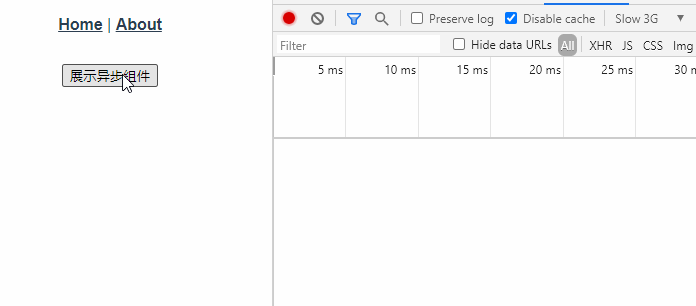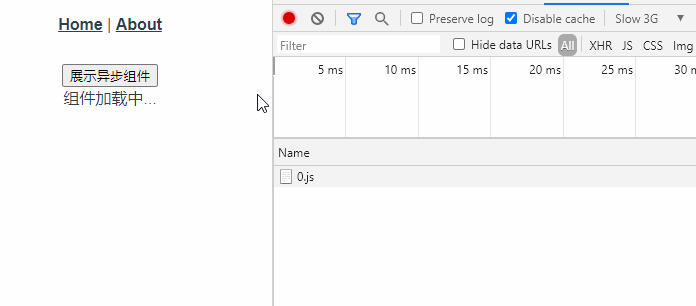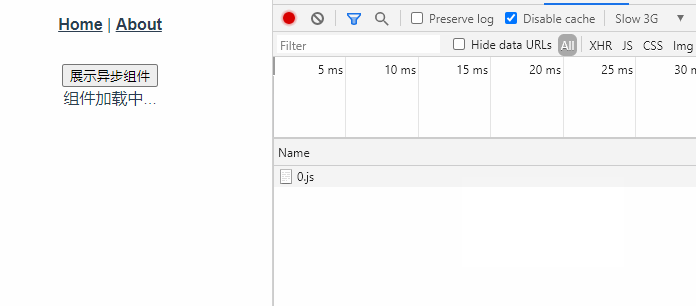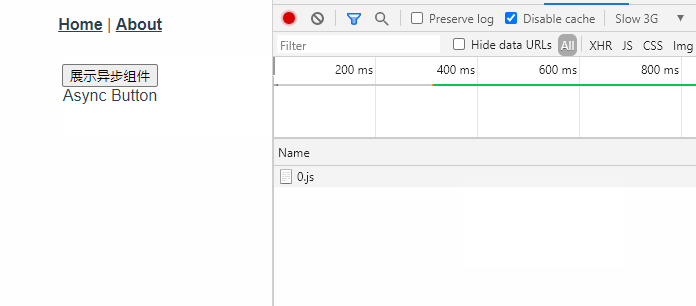
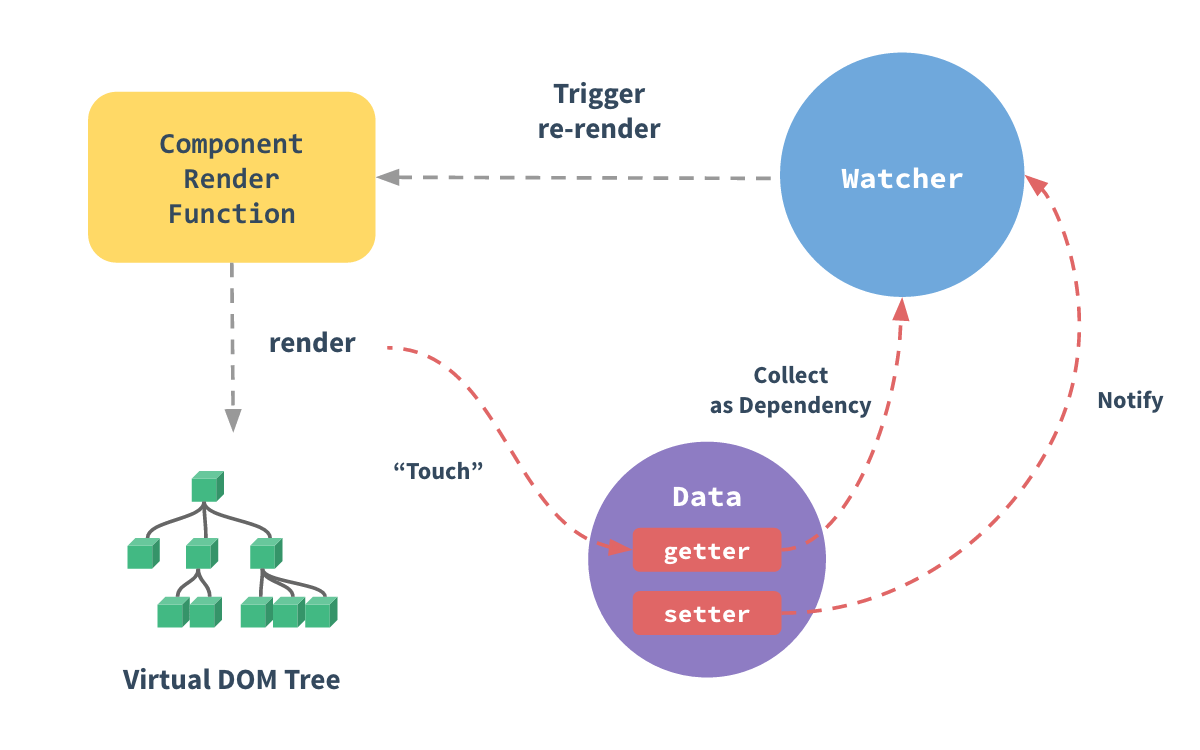
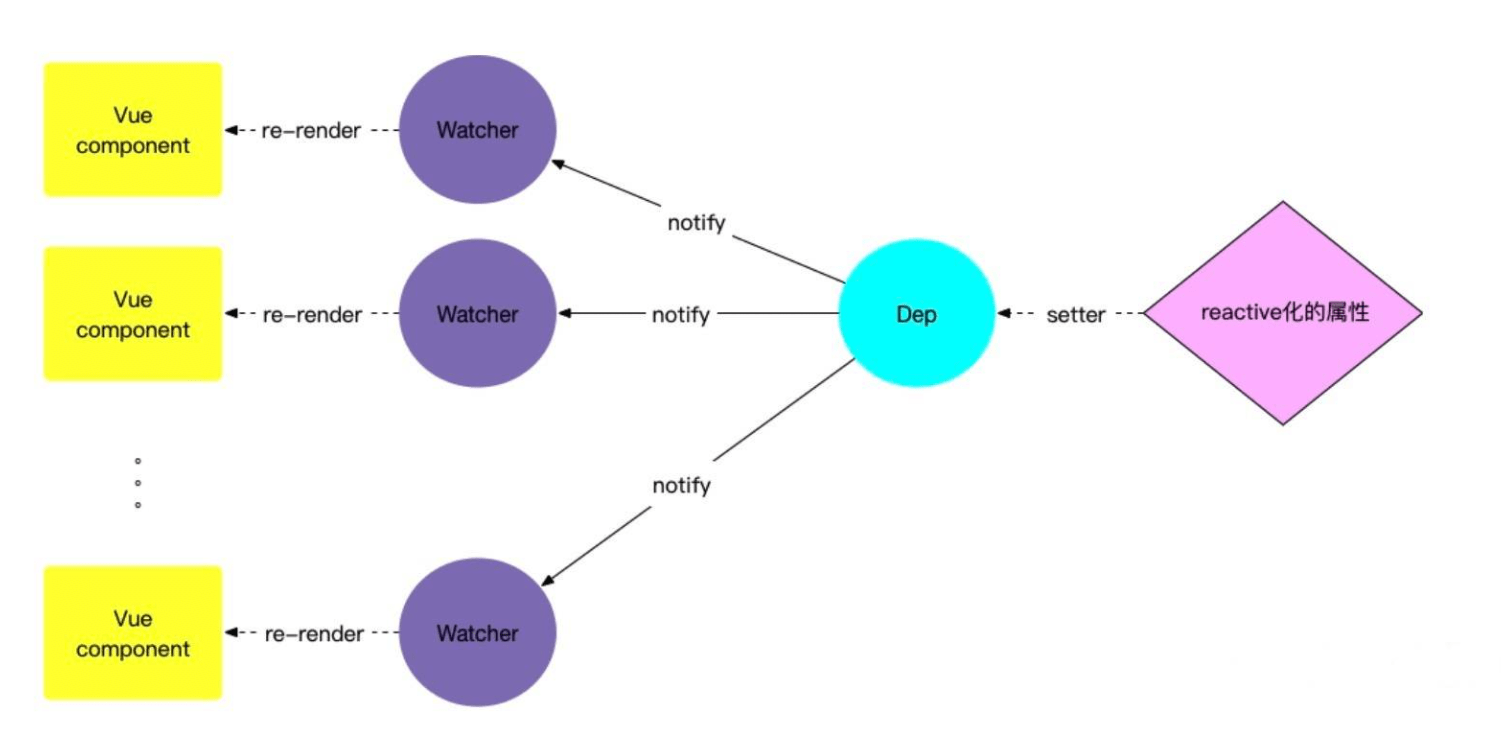
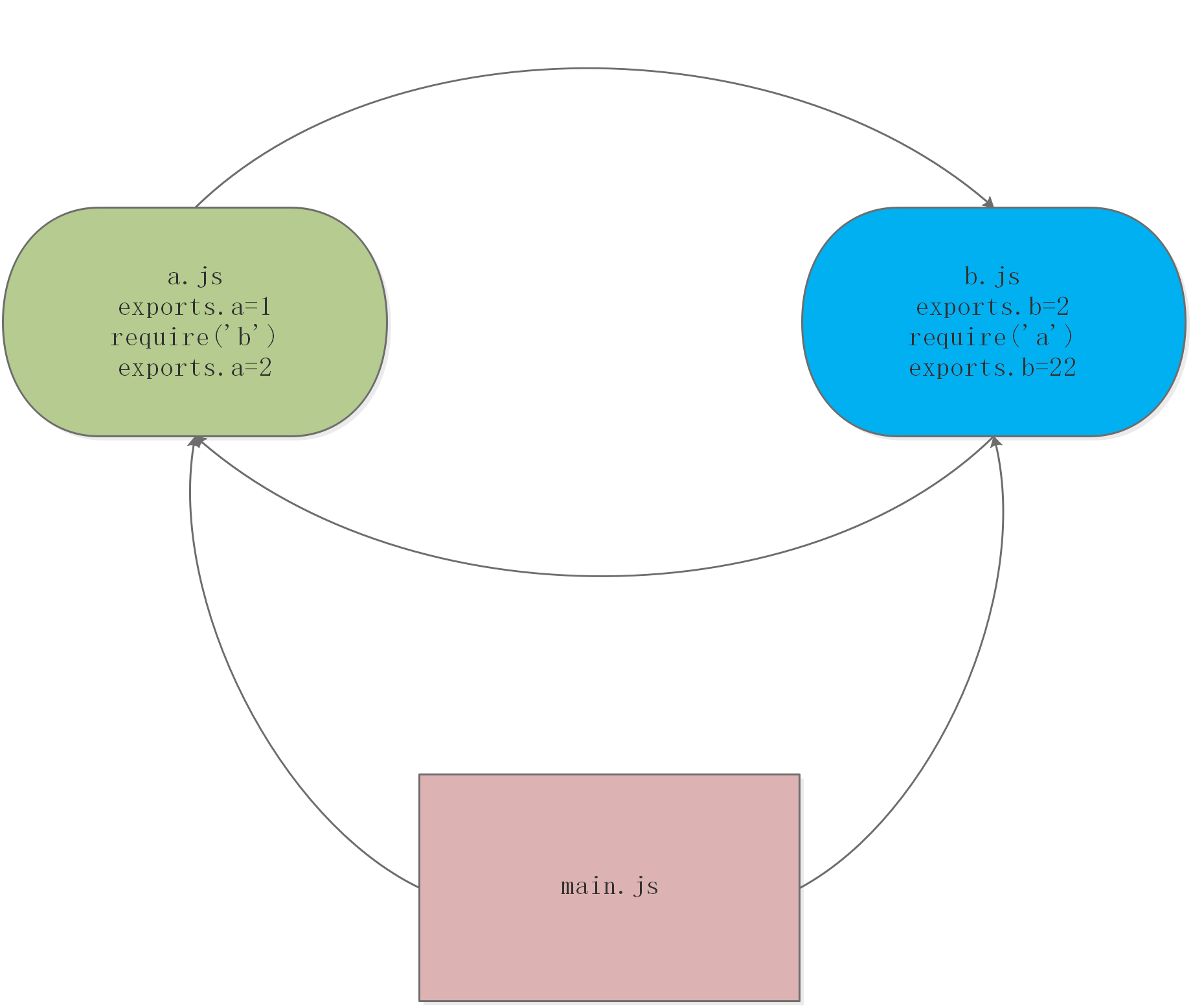
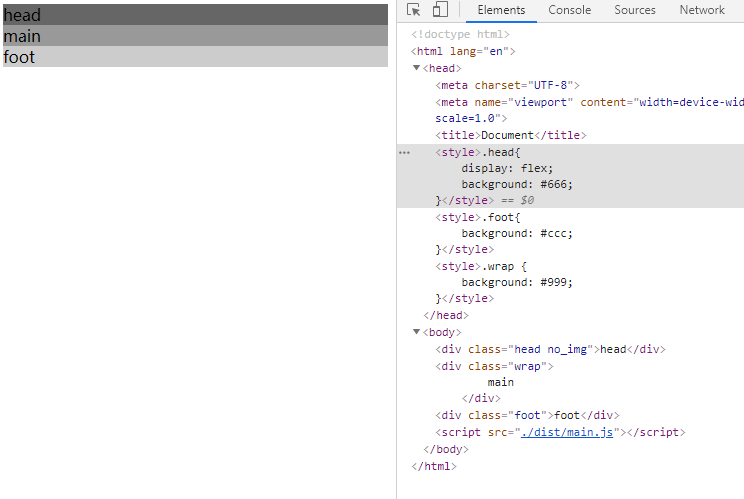
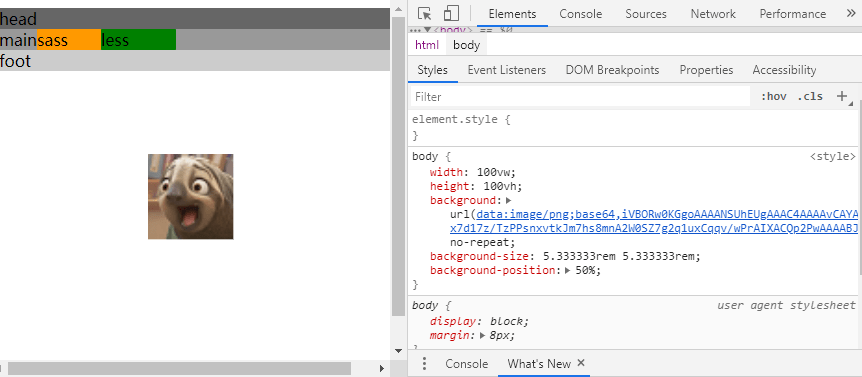
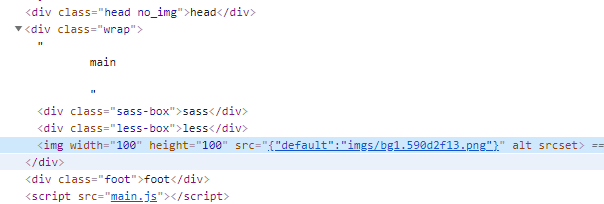
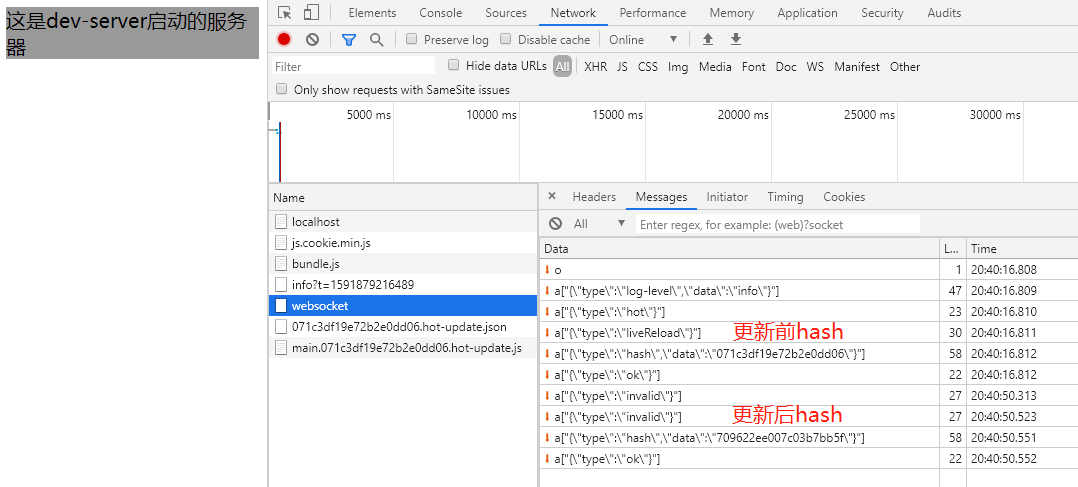
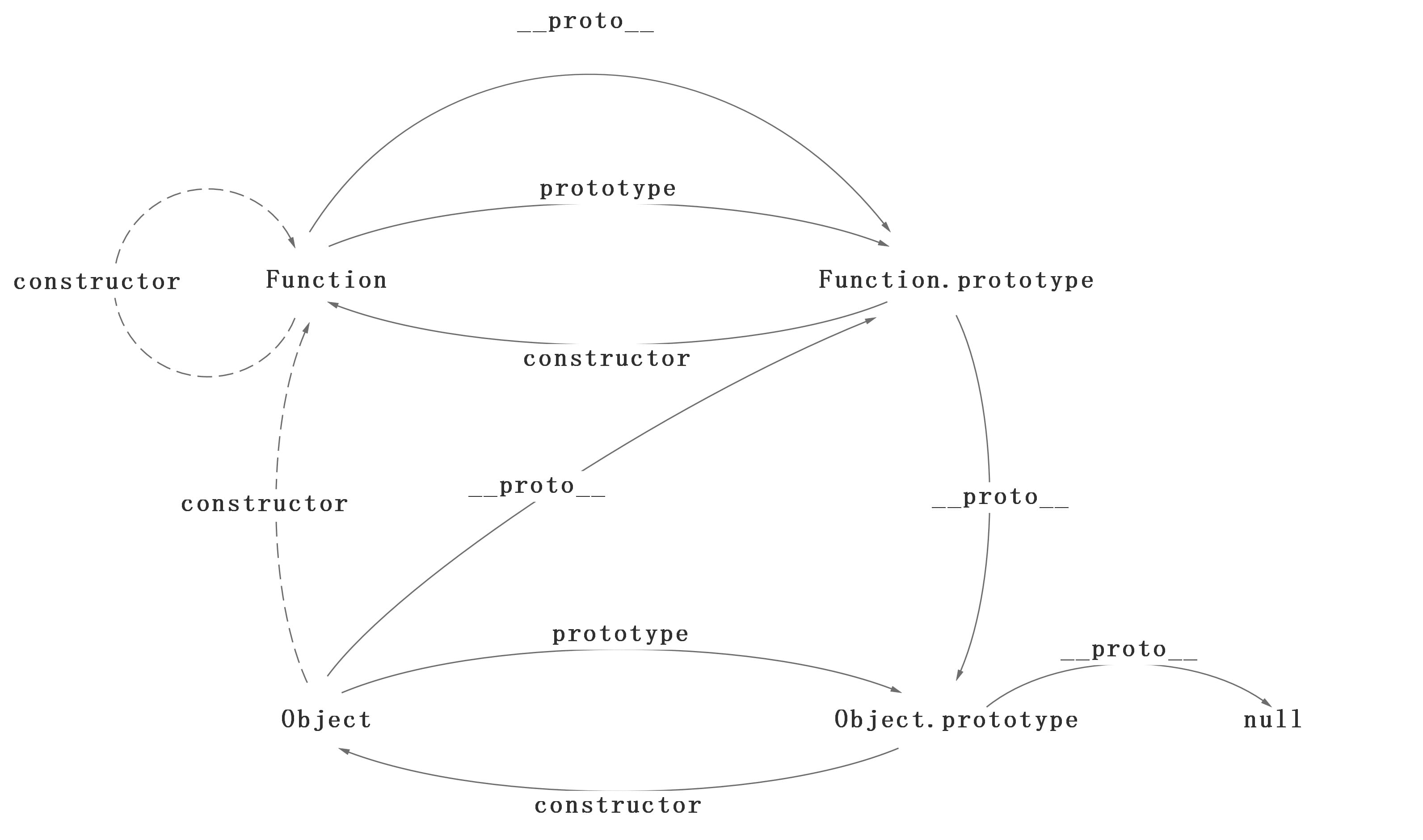
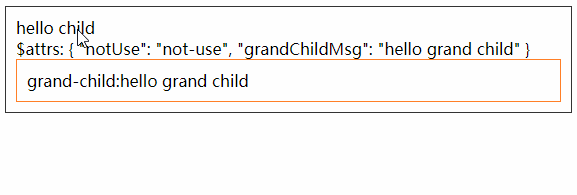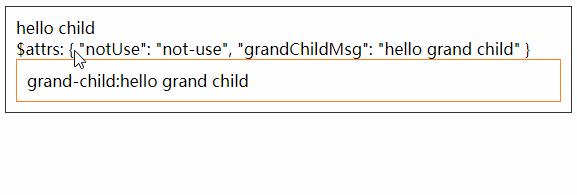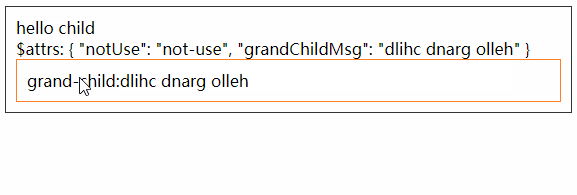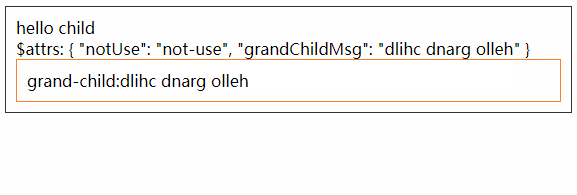
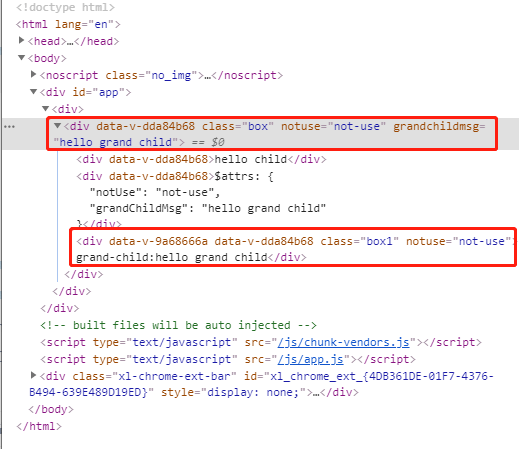
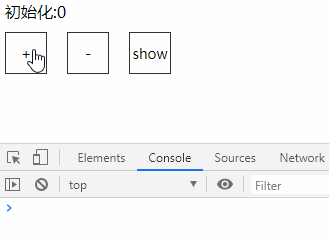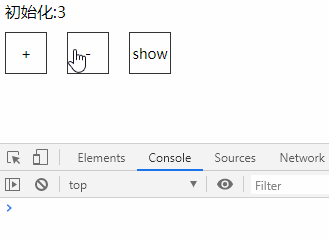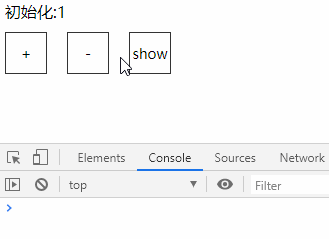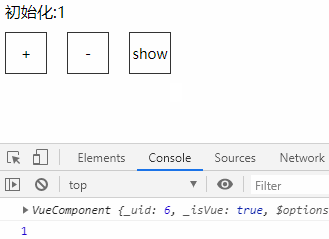
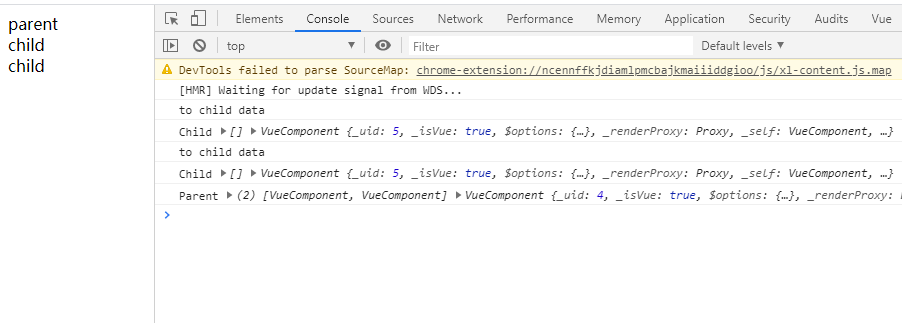
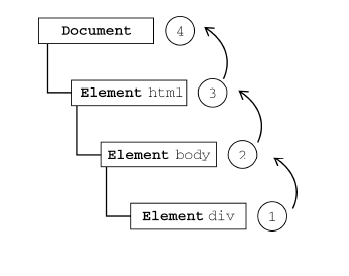
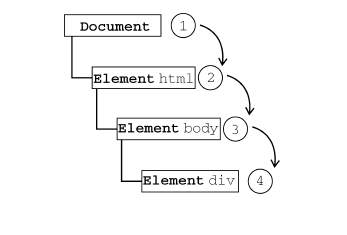
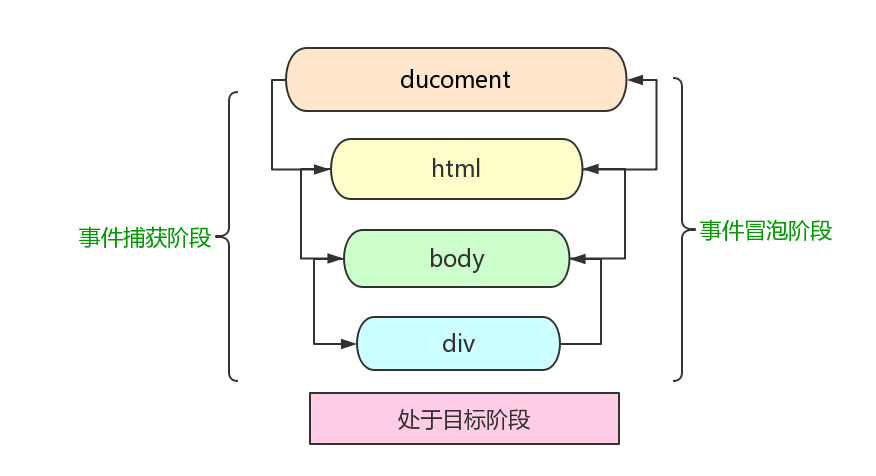
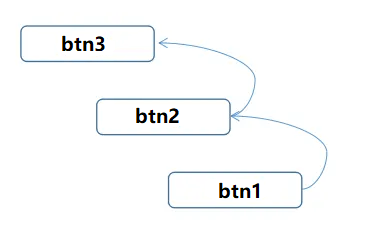
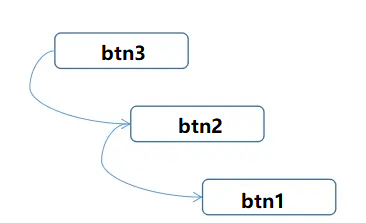
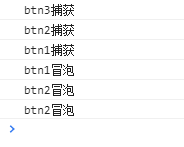
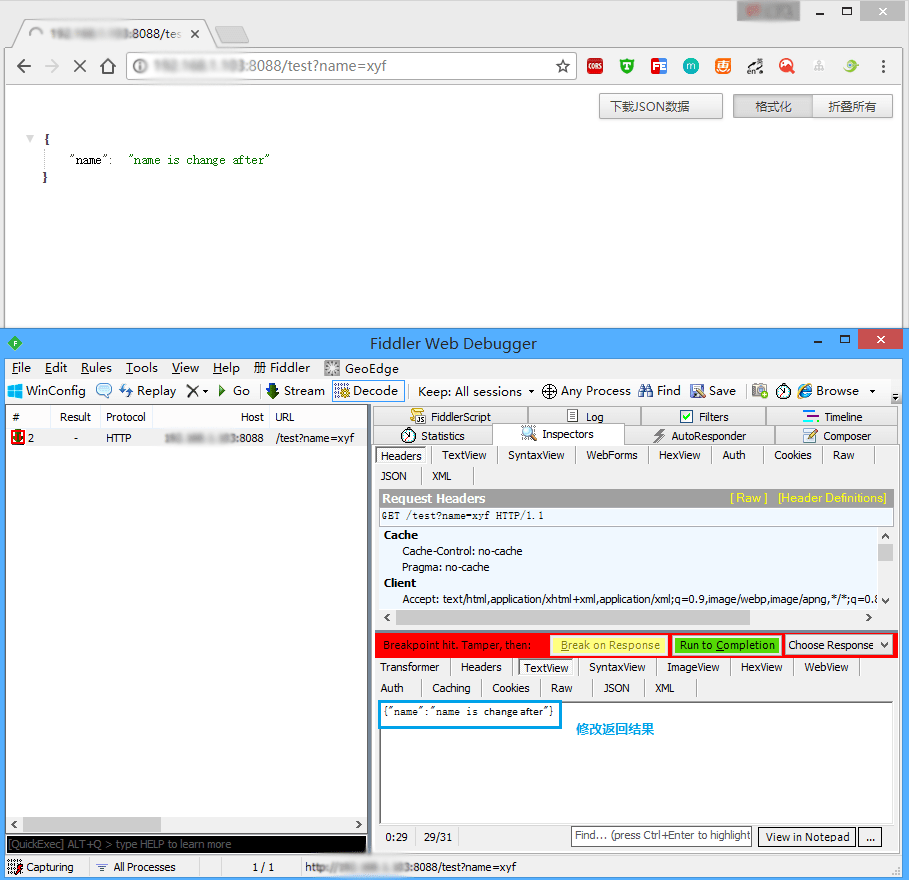
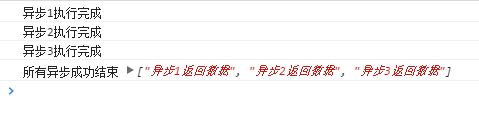
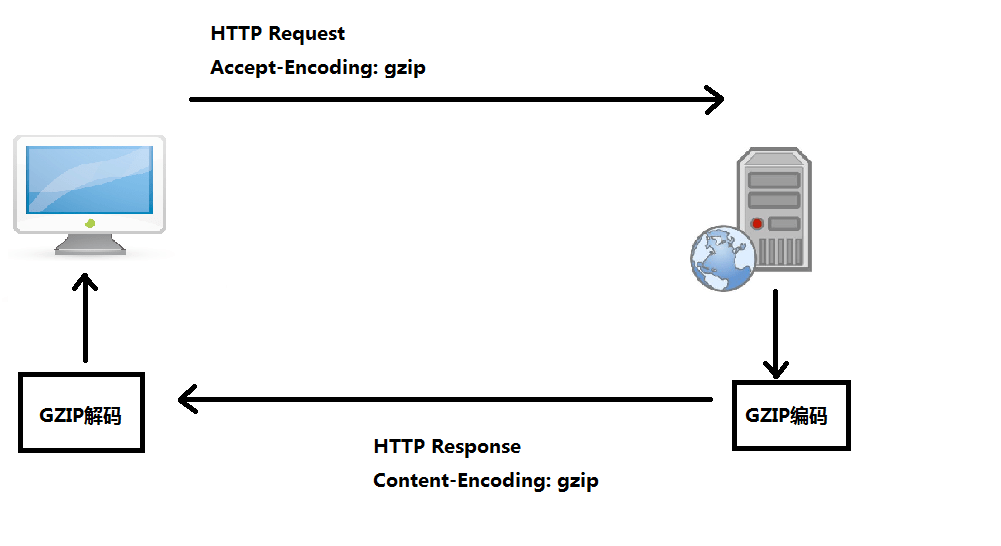
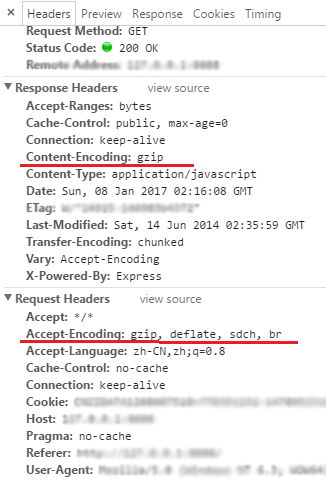
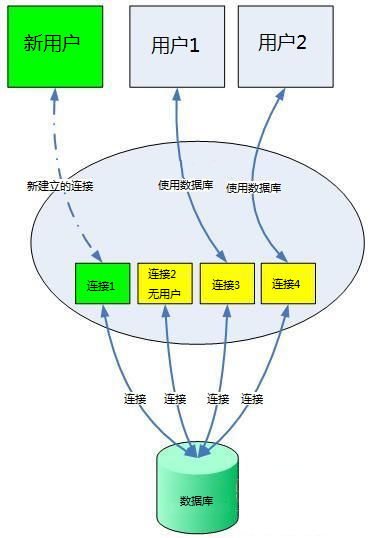
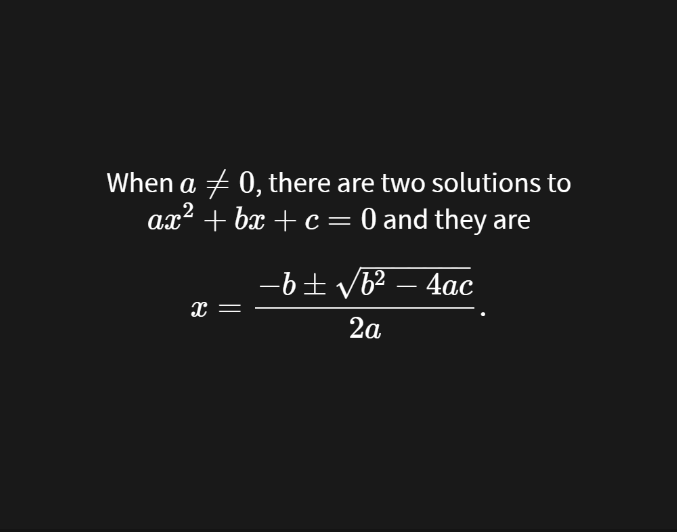<script setup> import { defineProps } from 'vue'; // 报错: // Type of the default value for 'list' prop must be a function. defineProps({ list: { type: Array, default: [], }, }), </script>
<div class="group hover:bg-blue-300" > <div class="text-black group-hover:text-white group-active:text-red-500" > ChitChat </div> <pclass="text-slate-500 group-hover:text-white"> You have a new message! </p> </div>
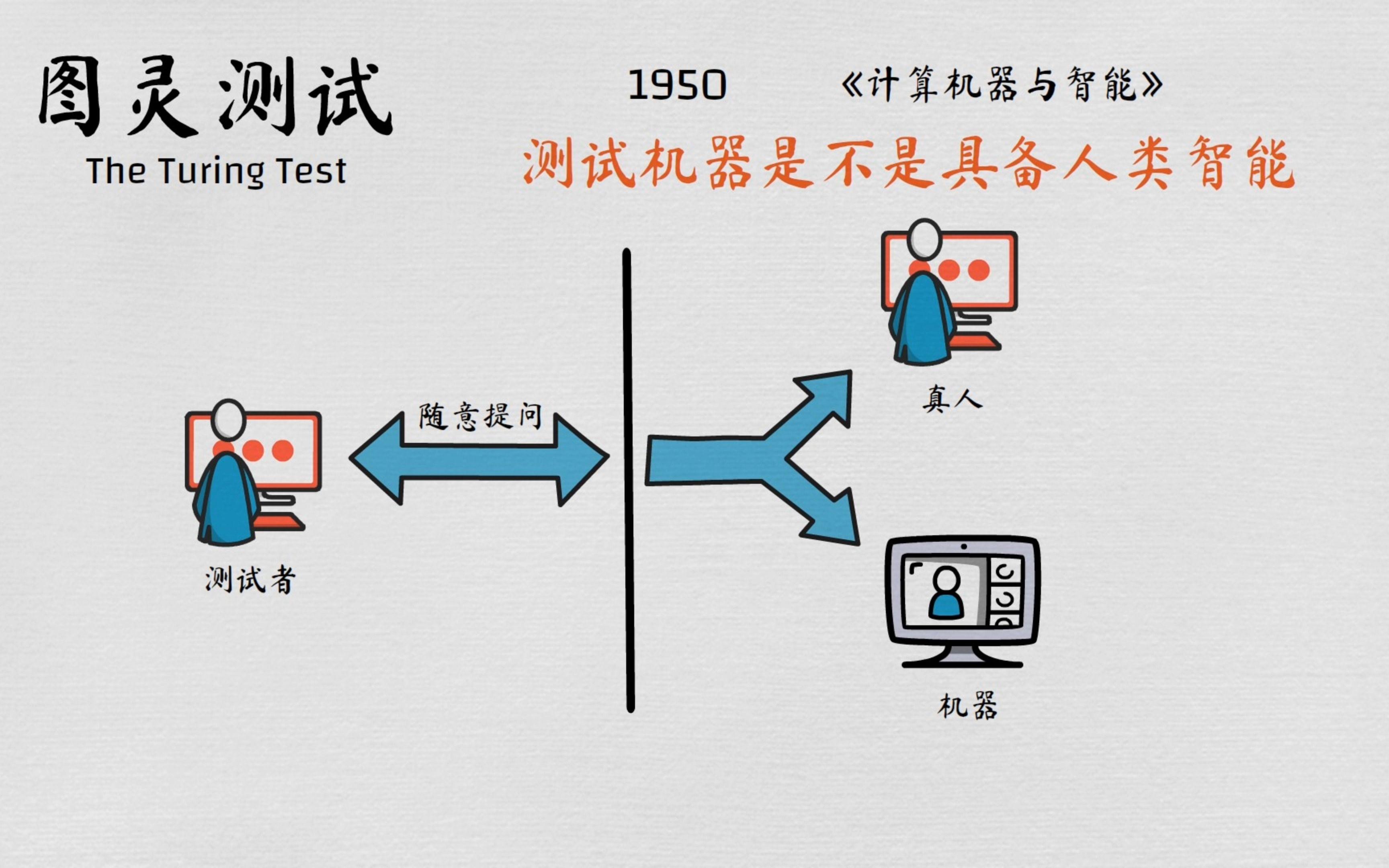
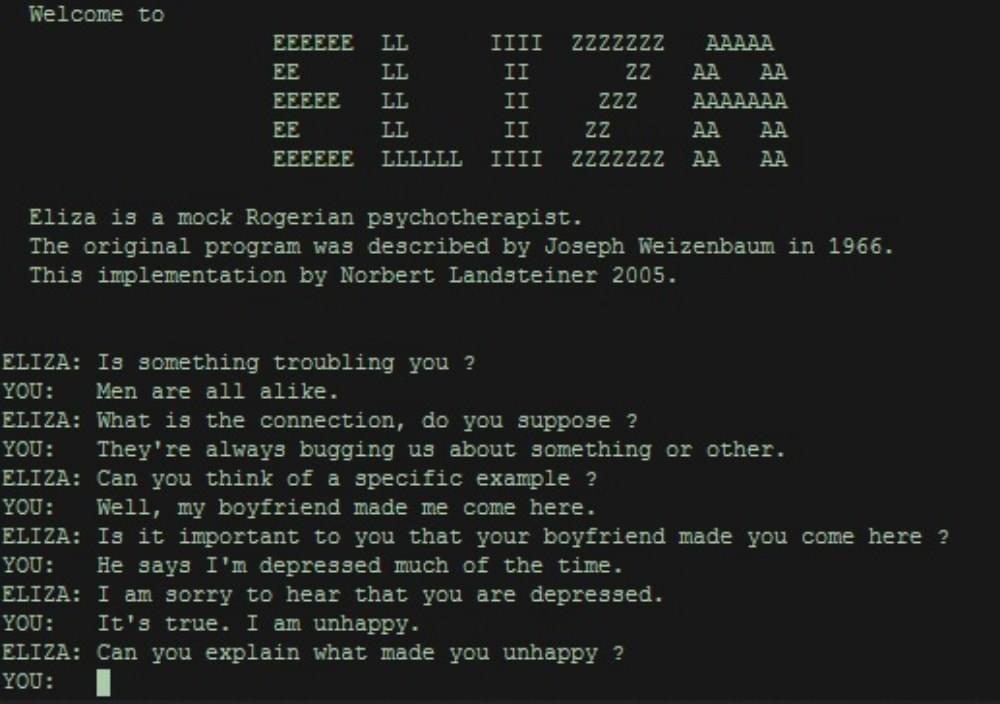
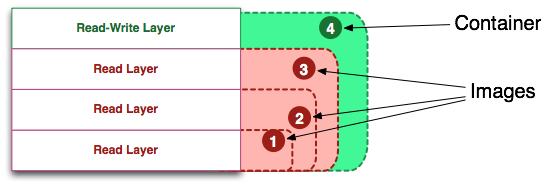
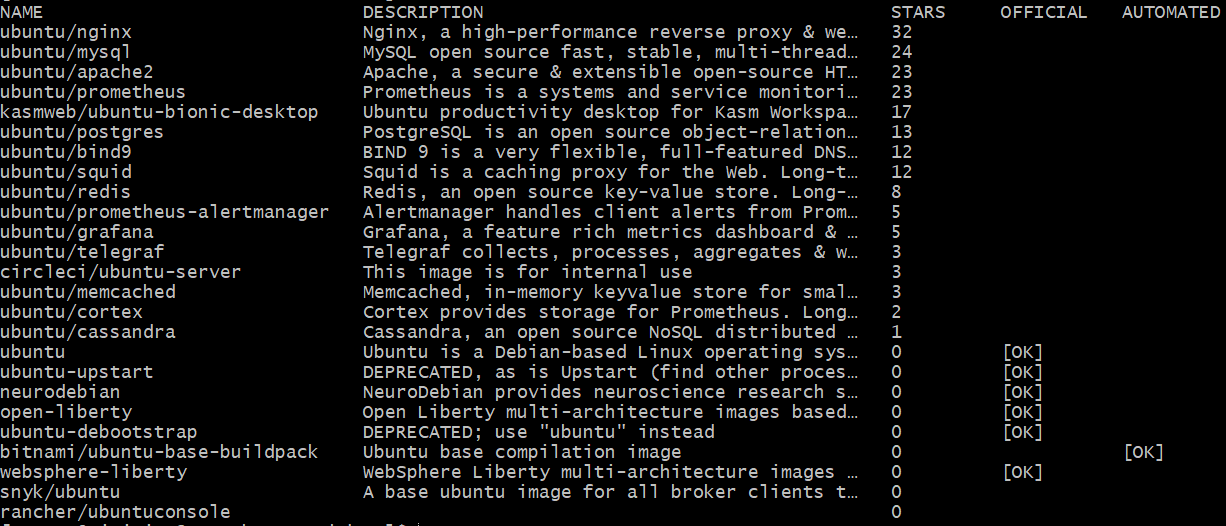
我们很多时候都能看到Linux发行版这个词,或者又看到说Linux内核怎么样,很多同学容易混淆这两个概念。其实当初Linus开发的Linux只是一个内核,是一个提供设备驱动、文件系统、进程管理、网络通信等功能的系统软件,是硬件和软件之间进行通信的桥梁,内核并不是一套完整的操作系统;我们可以把内核理解为手机的芯片,有了芯片,手机的各个功能才能运行起来,因此内核是整个操作系统的核心。我们在The Linux Kernel Archives网站可以下载到各种版本的Linux内核,并且对其进行编译。
Red Hat(红帽公司)创建于1993年,是一家开源解决方案供应商,部位于美国北卡罗来纳州的罗利市。
1993年,Bob Young 成立了ACC公司,这家公司主要是做邮购业务,主营业务是出售Linux和Unix的软件附件。1994年,Marc Ewing创建了自己的Linux发行版,并将其命名为:红帽Linux,Ewing在就读卡内基·梅隆大学期间曾经戴着一顶红色的康奈尔大学长曲棍球帽子,这是他的祖父赠送给他的。Young在1995年收购了Ewing的企业,两者合并成为红帽软件公司,由Young担任首席执行官。
Red Hat公司的产品主要包括RHEL(Red Hat Enterprise Linux,收费版本)和 CentOS(RHEL 的社区克隆版本,免费版本)、Fedora Core(由 Red Hat 桌面版发展而来,免费版本)。
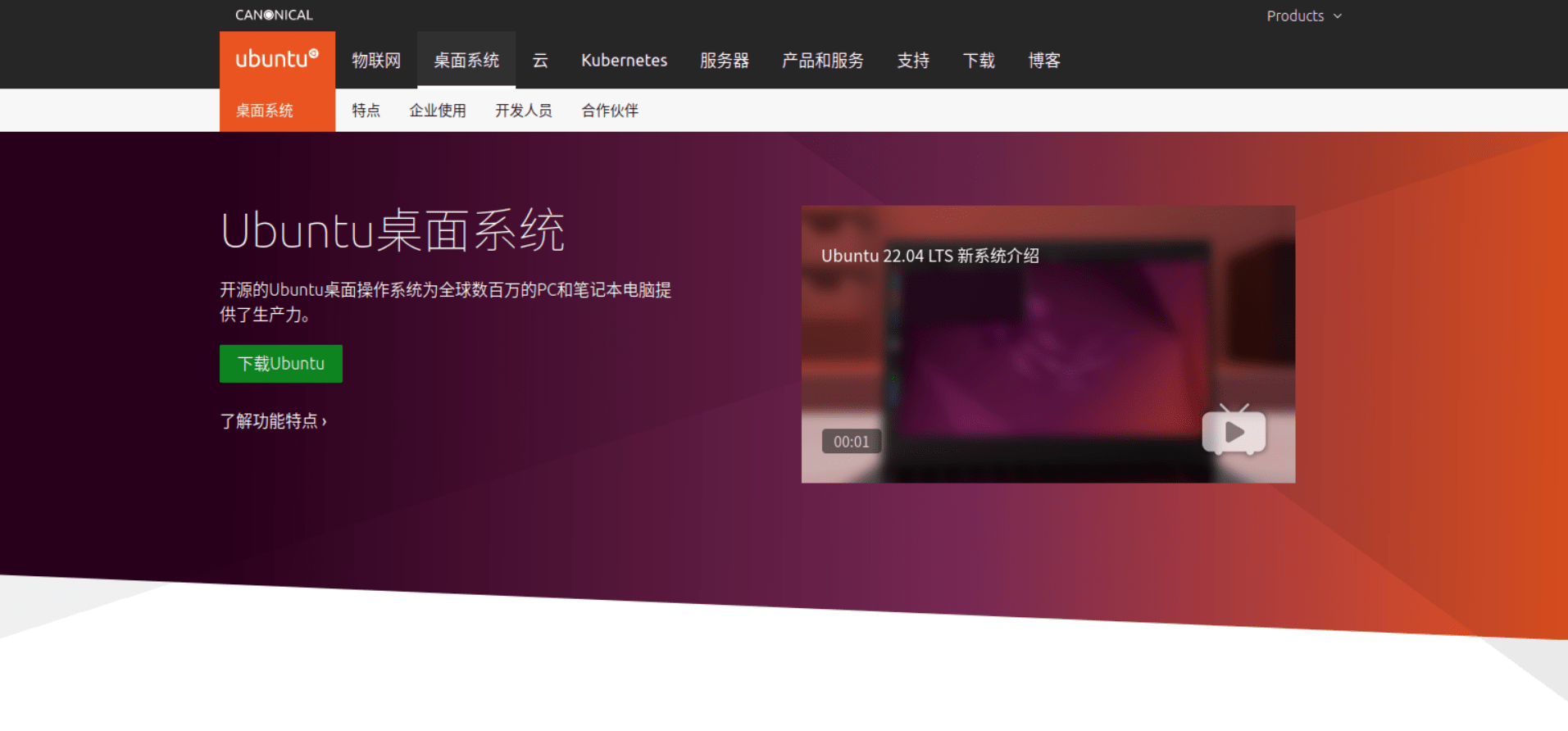
如果手头有闲置移动硬盘,想要真实体验一下Ubuntu系统(虚拟机体验不好),又不想舍弃Windows系统,可以将Ubuntu环境安装到移动硬盘,打造自己的个人移动工作平台;这样你不管是在办公室还是回家干活,只需要随身携带一块小小的硬盘就能轻松将工作用到的所有资料打包带走,保持工作的进度和环境。这里推荐笔者自用的国产的致态1TB SSD固态和绿联M2移动硬盘盒组合,方便打造自己的Ubuntu To Go环境。
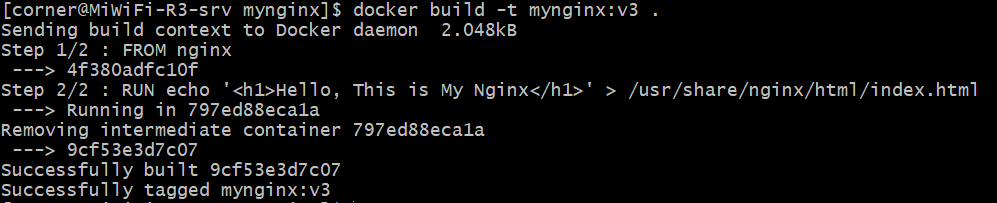
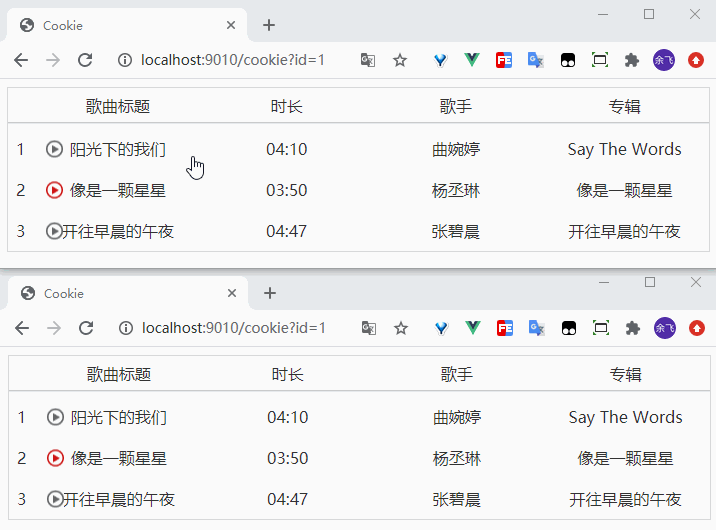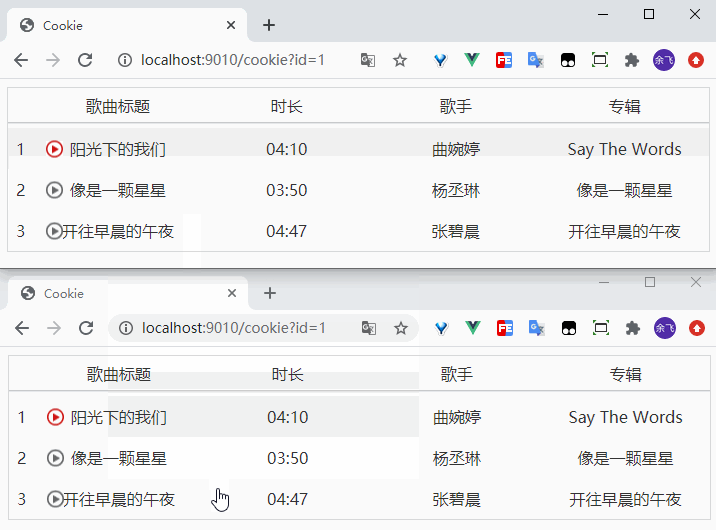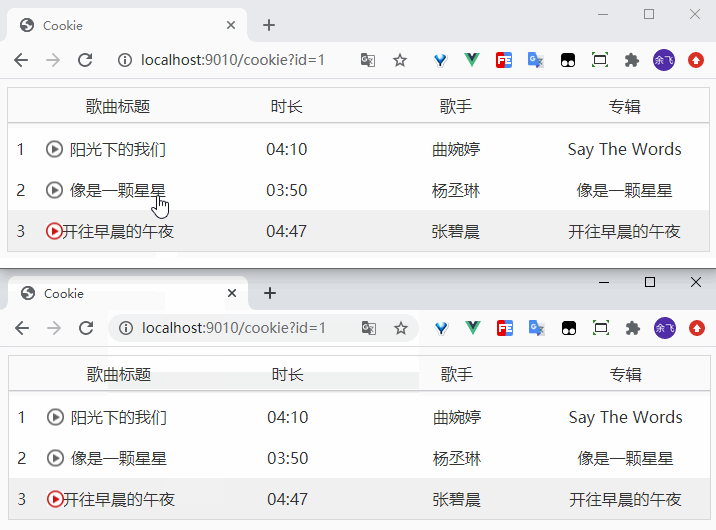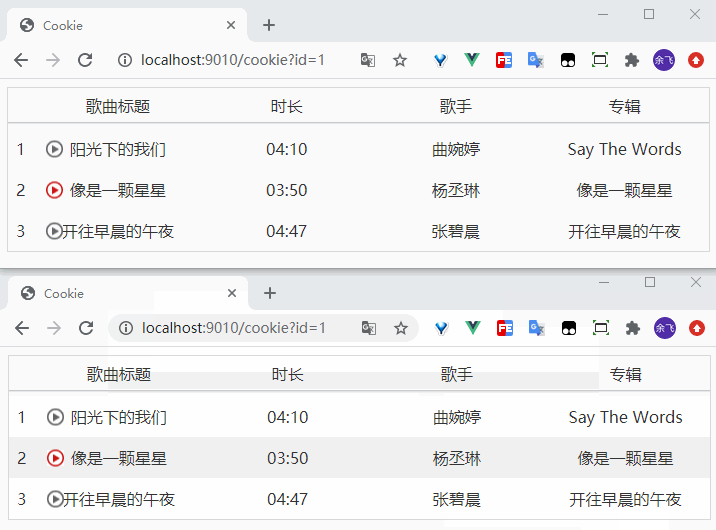
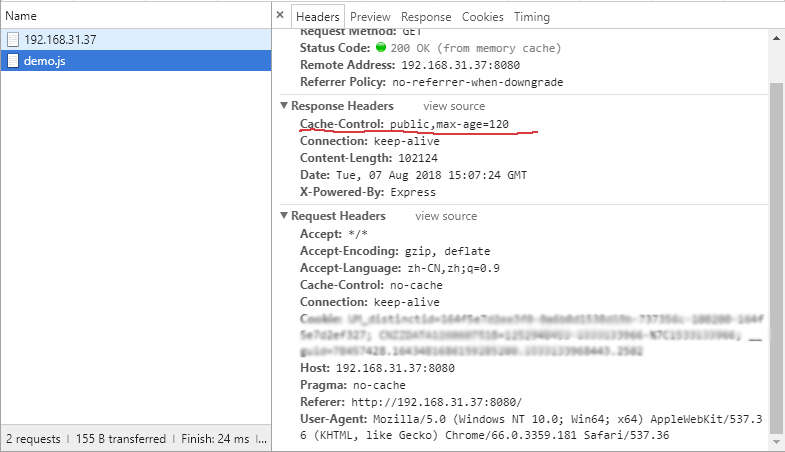
在项目中允许docker-compose up -d就在后台启动了Compose项目,访问8000端口,每次刷新页面,计数就会加1。
命令说明
ps
ps命令,列出所有的容器,以及运行状态和所有端口:
1 2 3 4 5
$ docker-compose ps Name Command State Ports ------------------------------------------------------------------------------ demo_redis_1 docker-entrypoint.sh redis ... Up 6379/tcp demo_web_1 docker-entrypoint.sh /bin/ ... Up 0.0.0.0:8080->8080/tcp
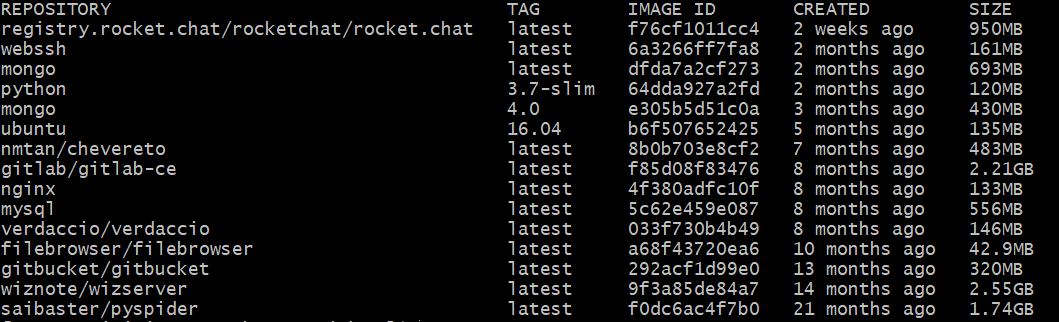
$ docker image ls node REPOSITORY TAG IMAGE ID CREATED SIZE node slim ffedf4f28439 5 days ago 241MB node alpine d2b383edbff9 3 months ago 170MB node latest a283f62cb84b 3 months ago 993MB
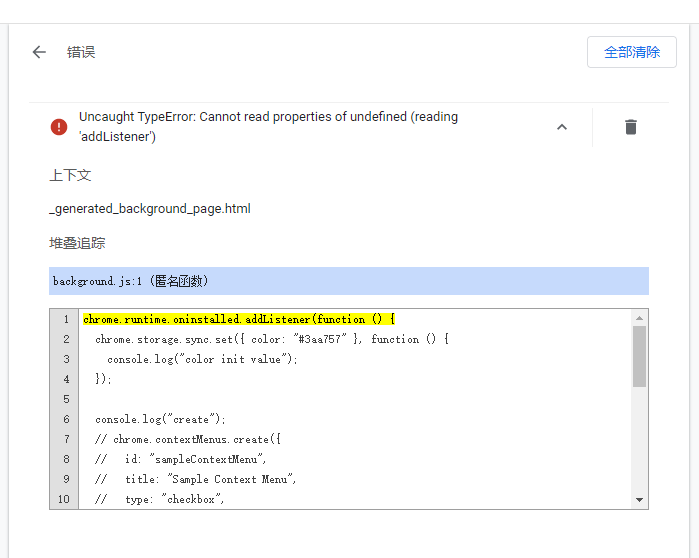
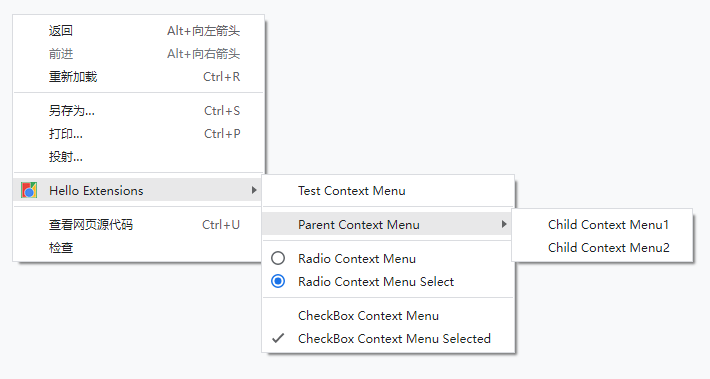
chrome.storage.onChanged.addListener(function (changes, namespace) { for (let [key, { oldValue, newValue }] ofObject.entries(changes)) { console.log( `Storage key "${key}" in namespace "${namespace}" changed.`, `Old value was "${oldValue}", new value is "${newValue}".` ); } });
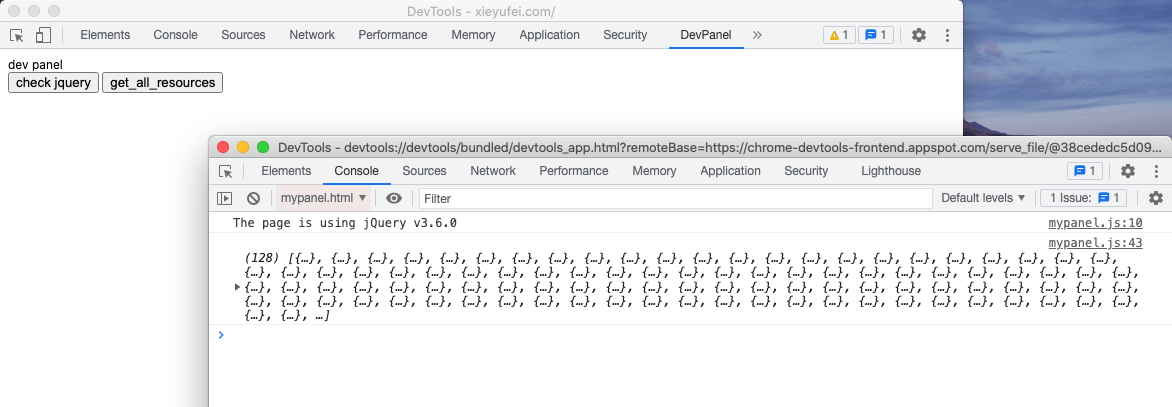
document.getElementById("check_jquery").addEventListener("click", function () { chrome.devtools.inspectedWindow.eval( "jQuery.fn.jquery", function (result, isException) { if (isException) { console.log("the page is not using jQuery"); } else { console.log("The page is using jQuery v" + result); } } ); });
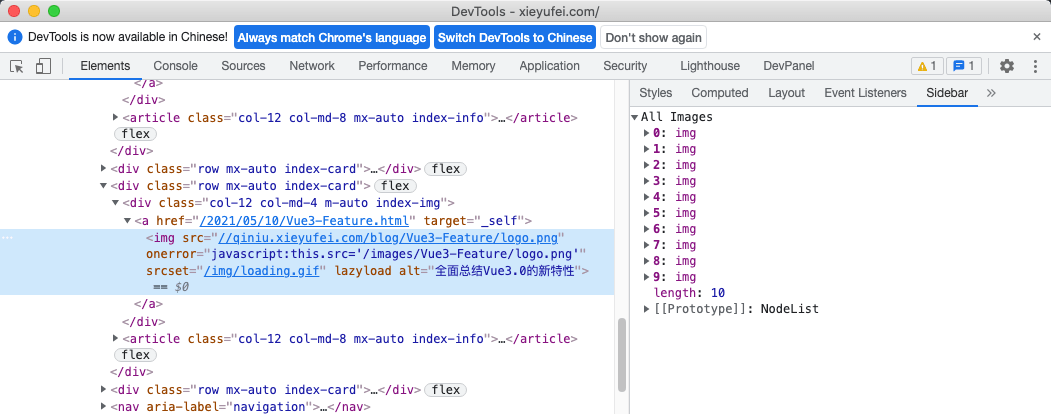
chrome.devtools.panels.elements.createSidebarPane( "All Images", function (sidebar) { sidebar.setExpression('document.querySelectorAll("img")', "All Images"); } );
$('#foo'); // or jQuery('#foo'); // 报错: // Cannot find name '$'. Do you need to install type definitions for jQuery? Try `npm i --save-dev @types/jquery` and then add `jquery` to the types field in your tsconfig.
<divclass="slides"> <section> When $a \ne 0$, there are two solutions to \(ax^2 + bx + c = 0\) and they are $$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$ </section> </div>
// 正常运行 functionreturnVoid(): void { returnundefined; } // 报错: // A function returning 'never' cannot have a reachable end point. functionreturnNever(): never { }
functionsay(age: string | number){ // toString是共有的方法 console.log(age.toString()) // 报错:Property 'length' does not exist on type 'number'. console.log(age.length) }
联合类型的变量在赋值时,会根据类型推论推断出一个类型:
1 2 3 4 5 6 7 8
letmyData: string | number
myData = "8" console.log(myData.length)
myData = 7 // 报错:Property 'length' does not exist on type 'number'. console.log(myData.length)
数组的类型
在ts中我们可以用多种方式来定义数组。
类型加[]
最简单的表示数组是使用类型+[]的形式:
1
letlist: number[] = [1, 2, 3]
数组的项中不能出现其他的类型,包括调用数组添加的方法:
1 2 3 4 5 6
// 报错:Type 'string' is not assignable to type 'number'. letlist: number[] = [1, 2, '3']
letlist1: number[] = [] // 报错:Argument of type 'string' is not assignable to parameter of type 'number' list1.push('3')
functionsum() { // 报错: //Type 'IArguments' is missing the following properties from type 'any[]': pop, push, concat, join, and 15 more. letarg: any[] = arguments; }
constenumMonth { Jan, Feb, Mar, } //报错: //'const' enums can only be used in property or index access expressions or the right hand side of an import declaration or export assignment or type query. console.log(Month) //正常运行,输出0 console.log(Month.Jan);
由于常量枚举在编译时会被移除,因此常量枚举不能包含计算项:
1 2 3 4 5 6 7 8
constenumMonth { Jan, //正常运行 Feb = 1 + 2, // 报错: // const enum member initializers can only contain literal values and other computed enum values. Mar = "123".length, }
// 报错: // Property 'gender' is missing in type '{ name: string; age: number; }' but required in type 'Duck'. letdog: Duck = { name: "yellow", age: 2, };
// 报错: // Property 'age' of type 'number' is not assignable to 'string' index type 'string'. // Property 'gender' of type 'boolean' is not assignable to 'string' index type 'string'. interfaceDuck { name: string; age?: number; gender?: boolean; [propName: string]: string; }
//通过 add(1, '1') //通过 add('2', 2) //报错: //The call would have succeeded against this implementation, but implementation signatures of overloads are not externally visible. add('2', '2')
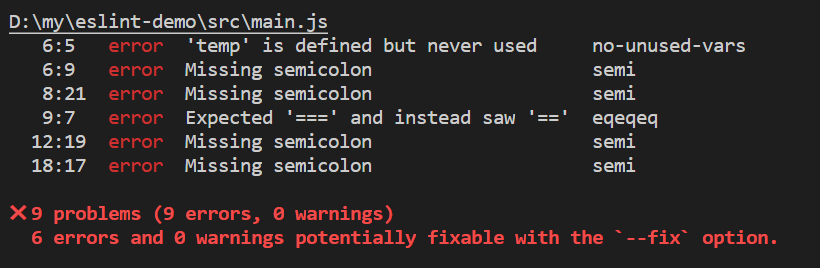
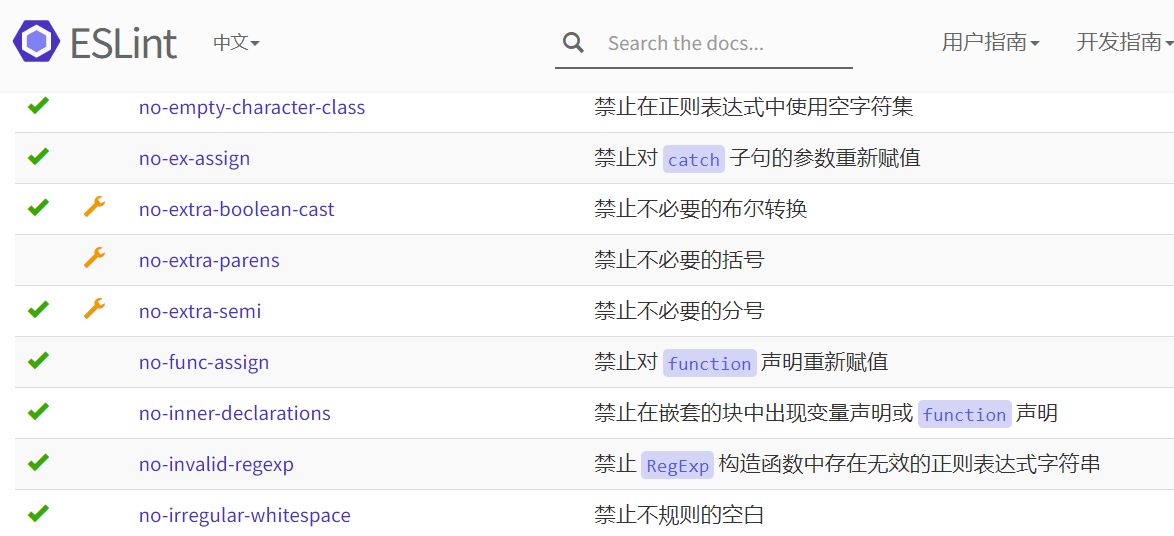
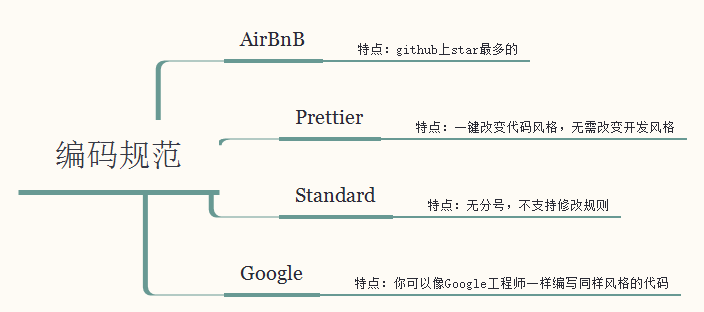
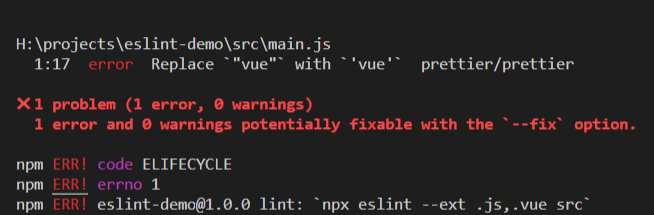
对于刚接触ESLint的同学,看到这么多的规则肯定很懵逼,难道要一条一条来记么?肯定不是的;项目的ESLint配置文件并不是一次性完成的,而是在项目开发中慢慢完善起来的,因为并不是所有的规则都是我们项目所需要的。因此我们可以先进行编码,在编码的过程中使用npm run lint校验代码规范,如果报错,可以通过报错信息去详细查看是那一条规范报错:
//报错 let moduleName = './num' import { num, add } from moduleName;
//报错 //SyntaxError: 'import' and 'export' may only appear at the top level let num = 10; if (num > 2) { import a from"./a"; } else { import b from"./b"; }
//报错 //SyntaxError: Only one default export allowed per module. //add.js exportdefaultfunction (x, y) { return x + y; }; exportdefaultfunction (x, y) { return x + y + 1; };
if (!Array.prototype.filter) { Array.prototype.filter = function (fun /*, thisp*/) { var len = this.length; if (typeof fun != "function") { thrownewTypeError(); } var res = newArray(); var thisp = arguments[1]; for (var i = 0; i < len; i++) { if (i inthis) { var val = this[i]; if (fun.call(thisp, val, i, this)) { res.push(val); } } } return res; }; }
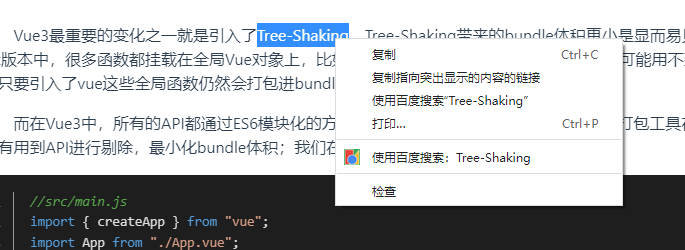
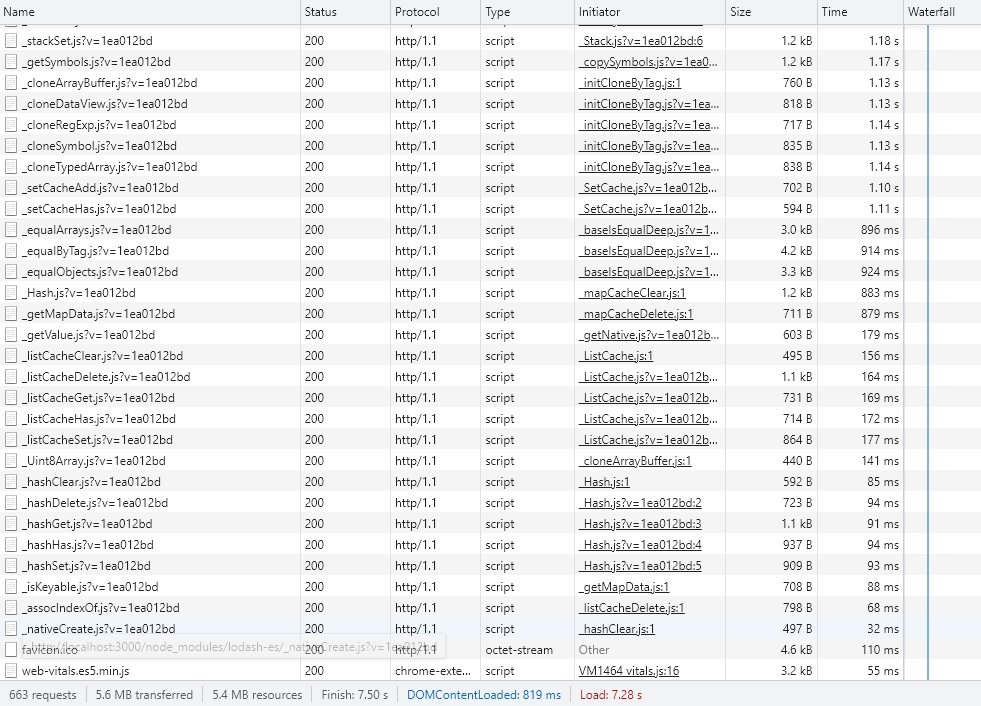
打包出来发现包的大小还是能达到70+kb,如果只引用了chunk不应该有这么大;我们打开/node_modules/lodash/index.js发现他还是使用了require的模式导入导出模块,因此导致Tree Shaking失败;我们先安装使用ES6模块版本的lodash:npm i -S lodash-es,然后修改引入包:
import { extend } from'/lib/utils.js' var context = { name: 'context' } var target = { name: 'target', say() { console.log('i am target,my name is ' + this.name) } } var source = { name: 'source', say() { console.log('i am source,my name is ' + this.name) } } extend(target, source, context) //source target.name //i am source,my name is context target.say()
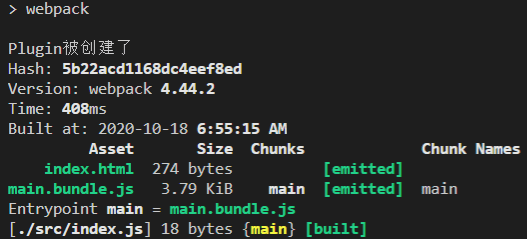
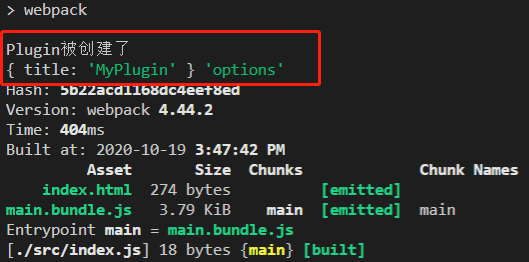
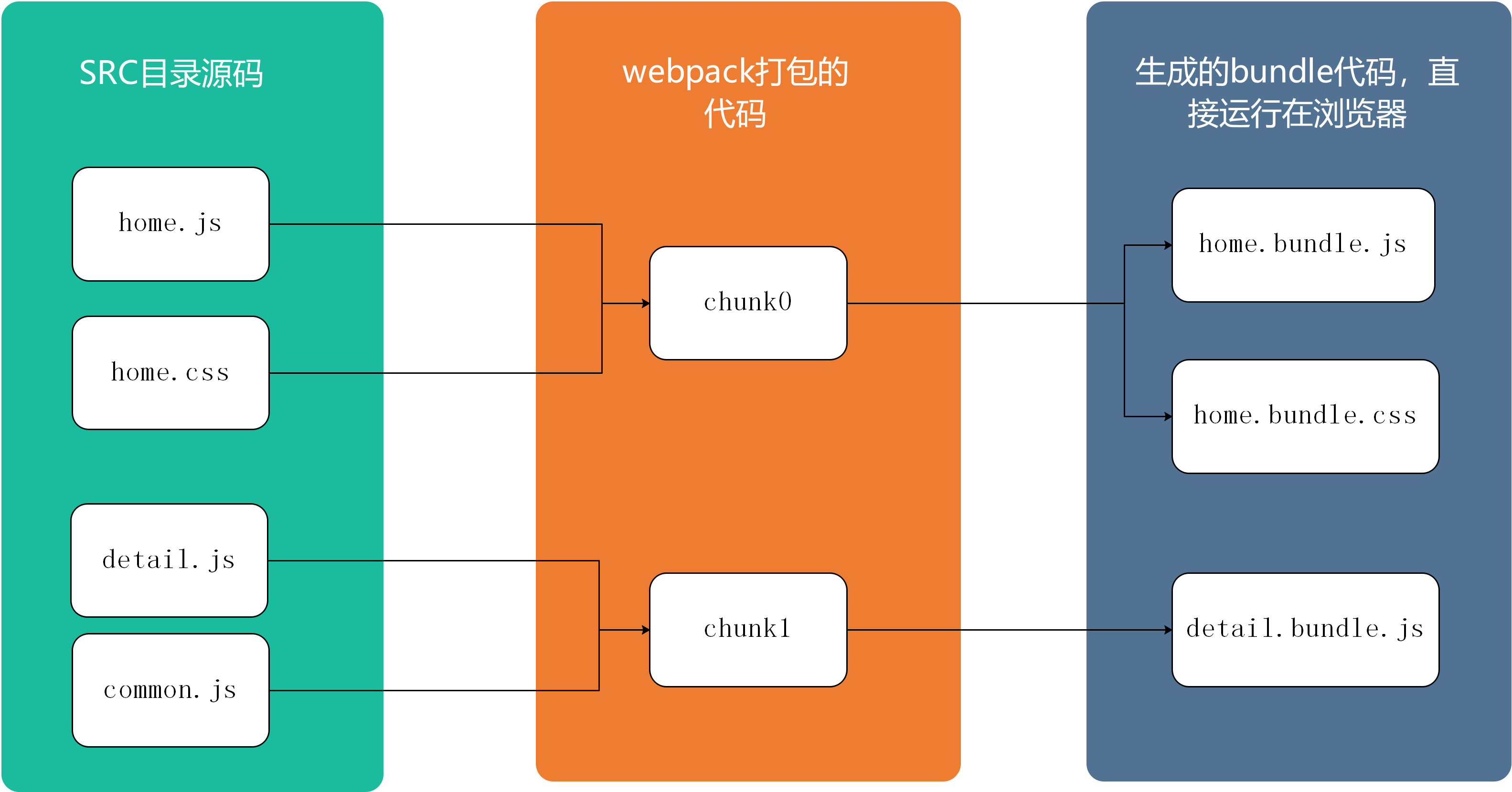
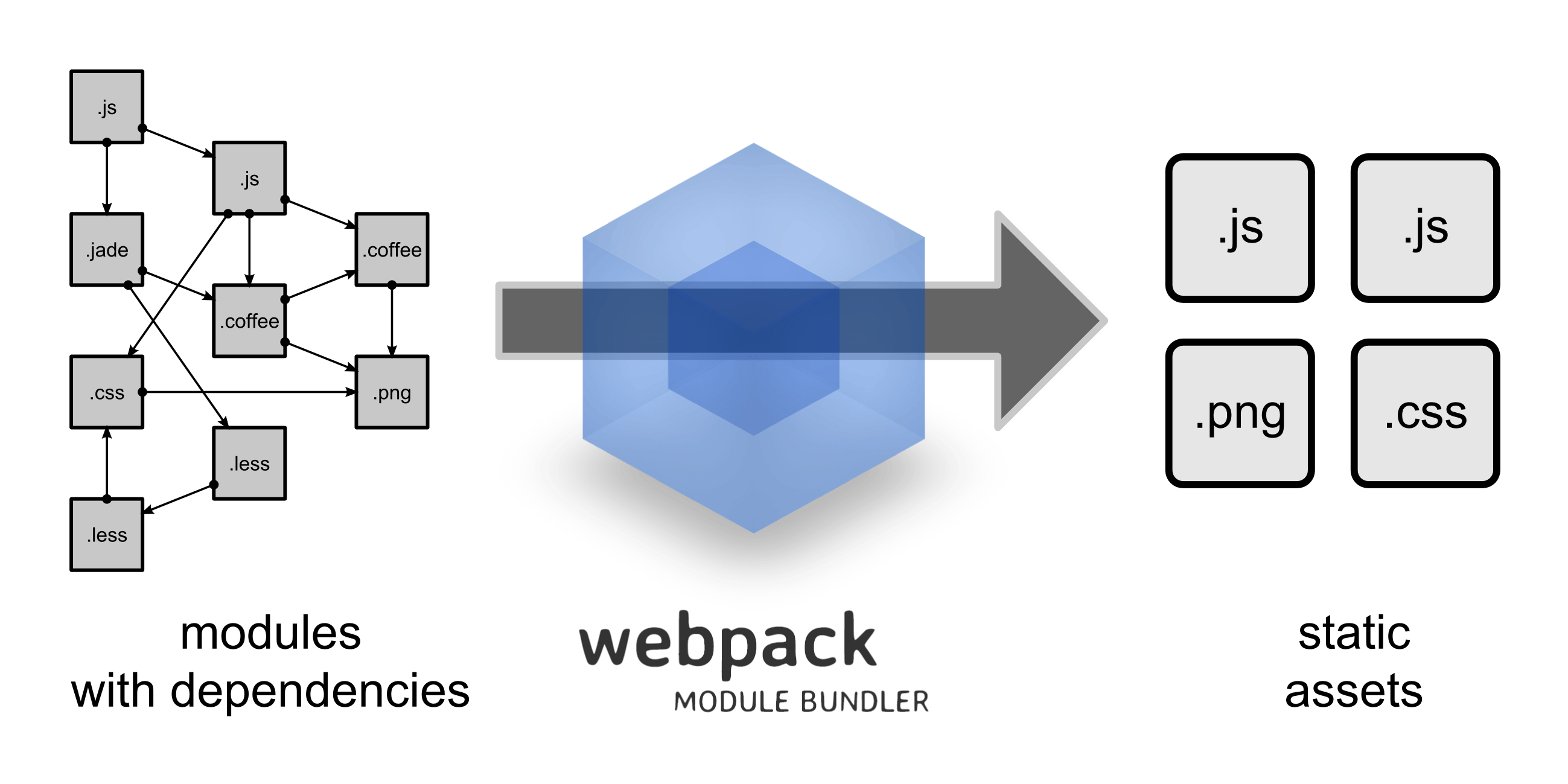
这里我们配置了一个单入口,输出也就是bundle.js;但是如果存在多入口的模式就行不通了,webpack会提示Conflict: Multiple chunks emit assets to the same filename,即多个文件资源有相同的文件名称;webpack提供了占位符来确保每一个输出的文件都有唯一的名称:
//_this是promise1的实例对象 var _this = this onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value onRejected = typeof onRejected === 'function' ? onRejected : reason => { throw reason }
var promise2 = newPromise((resolve, reject)=>{ if(_this.state === FULFILLED){ let x = onFulfilled(_this.value) resolvePromise(promise2, x, resolve, reject) } elseif(_this.state === REJECTED){ let x = onRejected(_this.reason) resolvePromise(promise2, x ,resolve, reject) } elseif(_this.state === PENDING){ _this.onFulfilled.push(()=>{ let x = onFulfilled(_this.value) resolvePromise(promise2, x, resolve, reject) }) _this.onRejected.push(()=>{ let x = onRejected(_this.reason) resolvePromise(promise2, x ,resolve, reject) }) } })
我们发现函数中有一个resolvePromise,就是上面说的Promise解决过程,它是对新的promise2和上一个执行结果 x 的处理,由于具有复用性,我们把它抽成一个单独的函数,这也是上面规范中定义的第一点。
var p = newPromise(function(resolve, reject){ resolve(3) }); //Uncaught (in promise) TypeError: Chaining cycle detected for promise #<Promise> var p2 = p.then(function(){ return p2 })
if(x && typeof x === 'object' || typeof x === 'function'){ let used; try { let then = x.then if(typeof then === 'function'){ then.call(x, (y)=>{ if (used) return; used = true resolvePromise(promise2, y, resolve, reject) }, (r) =>{ if (used) return; used = true reject(r) }) } else { if (used) return; used = true resolve(x) } } catch(e){ if (used) return; used = true reject(e) } } else { resolve(x) } }
functionmyNew(Fn, ...param){ var obj = newObject() var result = Fn.call(obj, ...param) obj.__proto__ = Fn.prototype returntypeof result === 'object' || typeof result === 'function' ? result : obj }
Vue.prototype.$mount = function ( el?: string | Element, hydrating?: boolean ): Component { el = el && query(el) /* istanbul ignore if */ if (el === document.body || el === document.documentElement) { process.env.NODE_ENV !== 'production' && warn( `Do not mount Vue to <html> or <body> - mount to normal elements instead.` ) returnthis } //以下省略无关代码 //... }
可以看到挂载函数传了一个el参数,这个参数可以是string类型,也可以是一个element元素,也就是dom节点。最重要的是el = el && query(el)这一行代码,那就继续看一下query函数是做什么的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/** * Query an element selector if it's not an element already. */ exportfunctionquery (el: string | Element): Element { if (typeof el === 'string') { const selected = document.querySelector(el) if (!selected) { process.env.NODE_ENV !== 'production' && warn( 'Cannot find element: ' + el ) returndocument.createElement('div') } return selected } else { return el } }
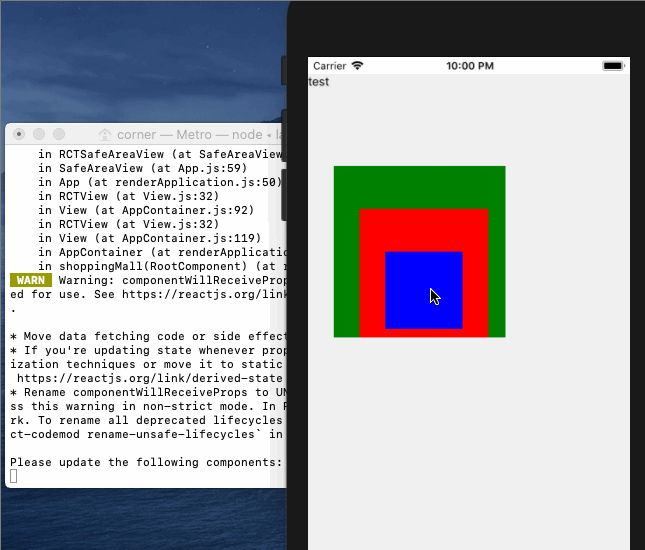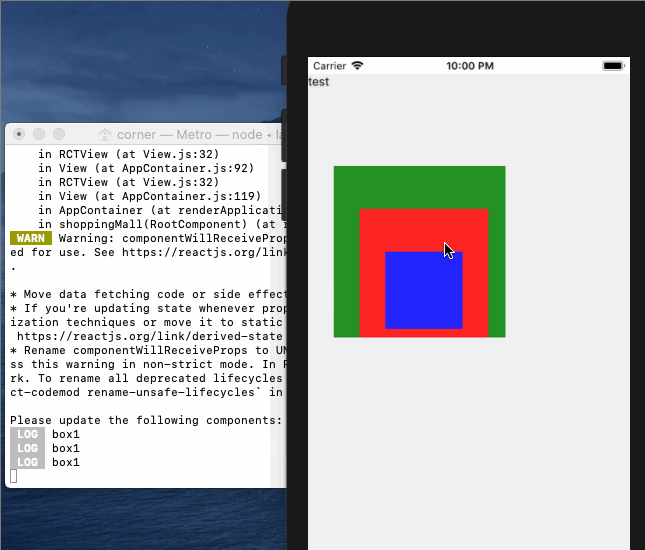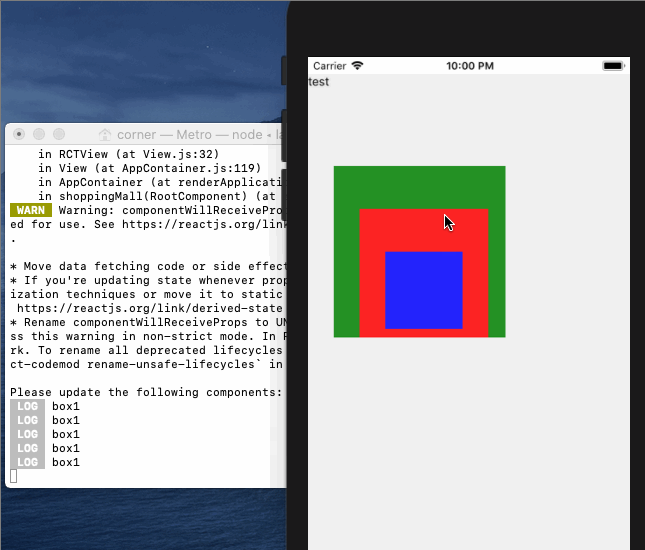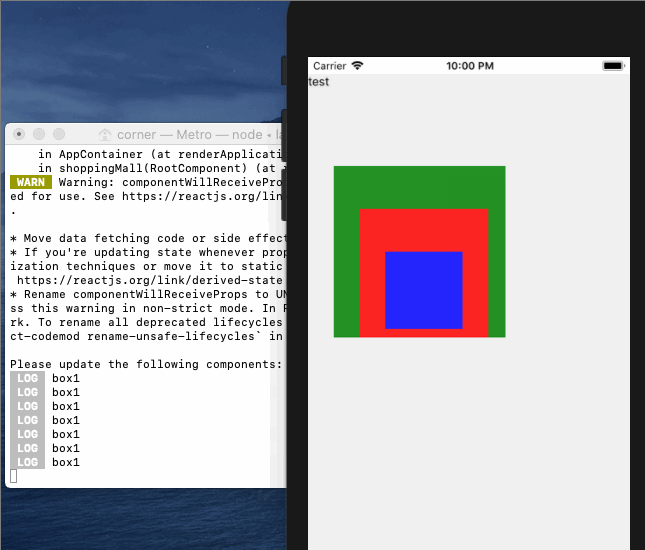
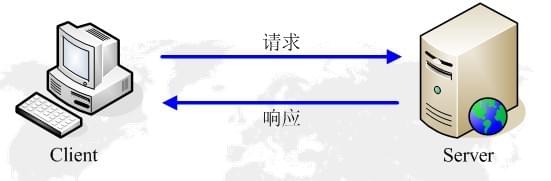
]]><p> 我们在初学Vue时,第一个上手的例子基本都是 new Vue({el:’#app’}),但是为什么Vue实例只能挂载在一个div上呢?同样的当我们开始写第一个Vue页面的时候,我们试图在template标签下写两个div,Vue提醒我们只能写一个元素,但是为什么只能有一个元素呢?很多时候我们都已经习以为常,但是却说不上来为什么。</p>从一道面试题来理解JS事件循环https://xieyufei.com/2019/12/30/Quiz-Eventloop.html2019-12-30T03:00:00.000Z2024-04-07T13:39:45.375Z 上周一个朋友发了某互联网公司的笔试题给我看,其中有一道题比较有意思,考察了对JS事件循环的理解,所以故事的开始让我们从一道复杂的面试题开始。。。
let arr = [1,'1',2,'2',1,2,'x','y','f','x','y','f']; functionunique1(arr){ let result = [arr[0]]; for (let i = 1; i < arr.length; i++) { let item = arr[i]; if(result.indexOf(item) == -1){ result.push(item); } } return result; } console.log(unique1(arr));
var name = 'window'; var sayName = function (param) { console.log('my name is:' + this.name + ',my param is ' + param) }; //my name is:window,my param is window param sayName('window param')
var callObj = { name: 'call' }; //my name is:call,my param is call param sayName.call(callObj, 'call param');
var applyObj = { name: 'apply' }; //my name is:apply,my param is apply param sayName.apply(applyObj, ['apply param']);
var bindObj = { name: 'bind' } var bindFn = sayName.bind(bindObj, 'bind param') //my name is:bind,my param is bind param bindFn();
functionDog(name) { Animal.call(this) this.name = name || 'mica' } var dog = newDog() dog.color.push('blue') dog.sleep() // mica正在睡觉! dog.eat('bone') //Uncaught TypeError: dog.eat is not a function console.log(dog.color) //["black", "blue"] console.log(dog instanceofAnimal) //false console.log(dog instanceofDog) //true var new_dog = newDog() console.log(new_dog.color) //["black"]
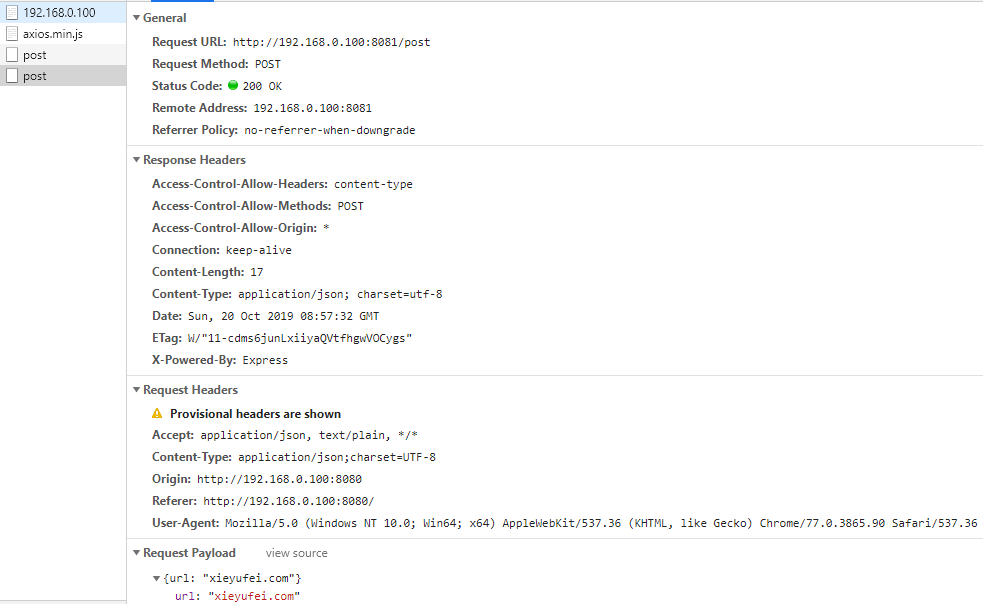
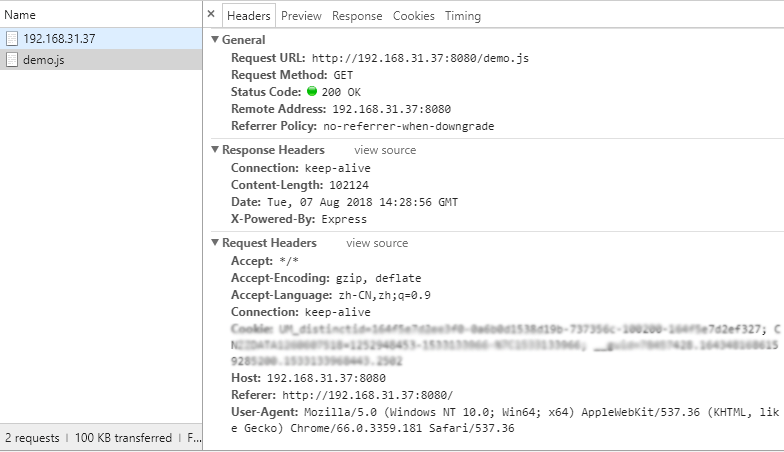
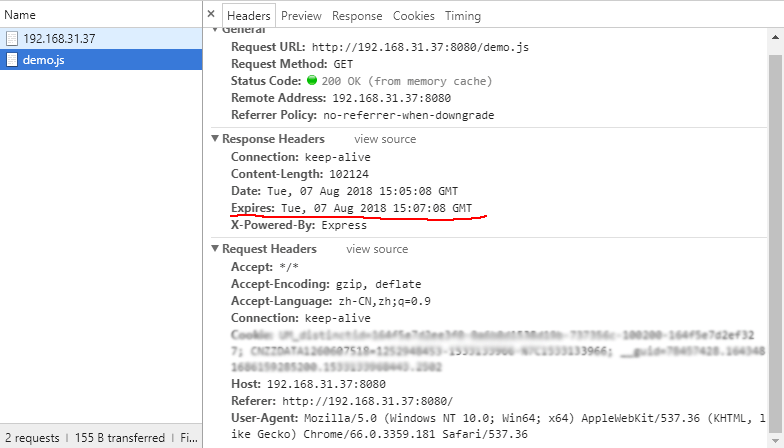
app.get('/demo.js',(req, res)=>{ let jsPath = path.resolve(__dirname,'./static/js/demo.js') let cont = fs.readFileSync(jsPath); let status = fs.statSync(jsPath)
// toFixed兼容方法 Number.prototype.toFixed = function(len){ if(len>20 || len<0){ thrownewRangeError('toFixed() digits argument must be between 0 and 20'); } // .123转为0.123 var number = Number(this); if (isNaN(number) || number >= Math.pow(10, 21)) { return number.toString(); } if (typeof (len) == 'undefined' || len == 0) { return (Math.round(number)).toString(); } var result = number.toString(), numberArr = result.split('.');
moment({ y :2010, M :3, d :5, h :15, m :10, s :3, ms :123}); moment({ year :2010, month :3, day :5, hour :15, minute :10, second :3, millisecond :123}); moment({ years:2010, months:3, days:5, hours:15, minutes:10, seconds:3, milliseconds:123}); moment({ years:2010, months:3, date:5, hours:15, minutes:10, seconds:3, milliseconds:123});
上面代码中的day和date都表示当前月的第几天。
Date 对象
我们也可以传入JS原生的Date对象来创建moment对象。
1 2
varday = newDate(2011, 9, 16); var dayWrapper = moment(day);
let arr = [1,'1',2,'2',1,2,'x','y','f','x','y','f'];
functionunique1(arr){ let result = [arr[0]]; for (let i = 1; i < arr.length; i++) { let item = arr[i]; if(result.indexOf(item) == -1){ result.push(item); } } return result; }
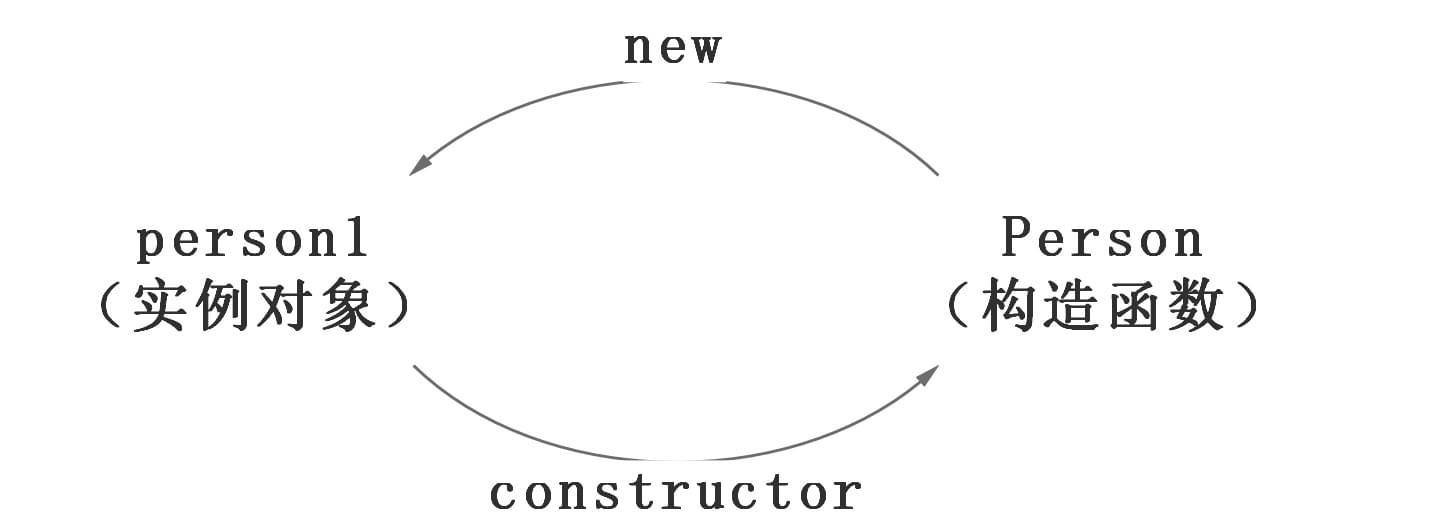
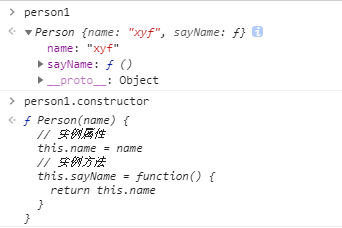
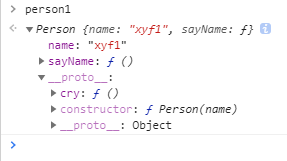
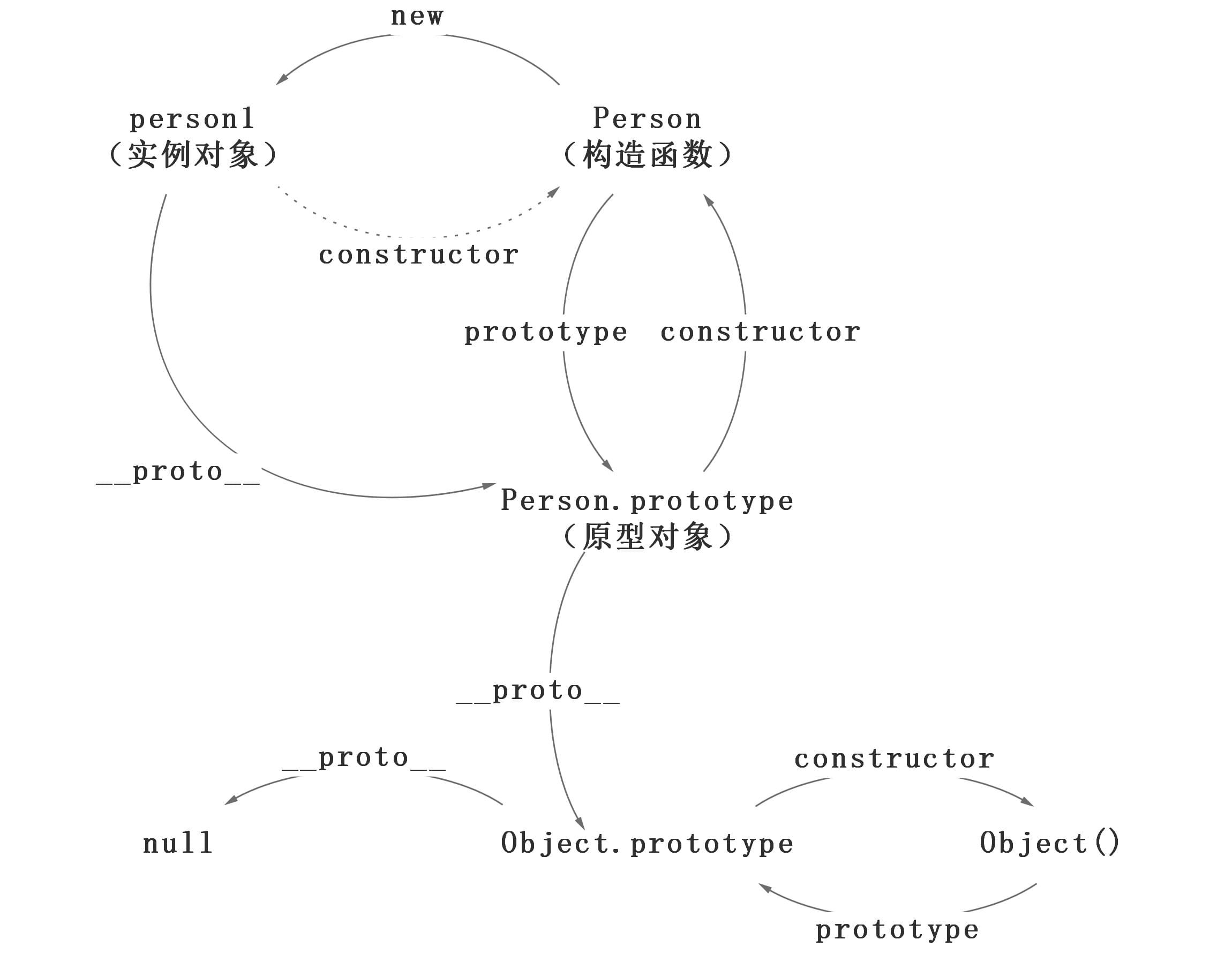
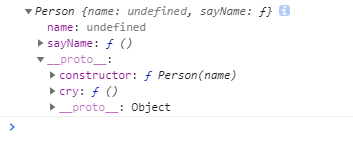
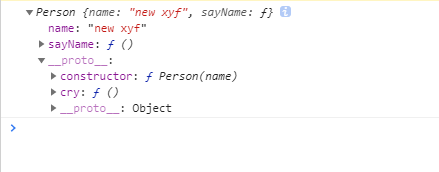
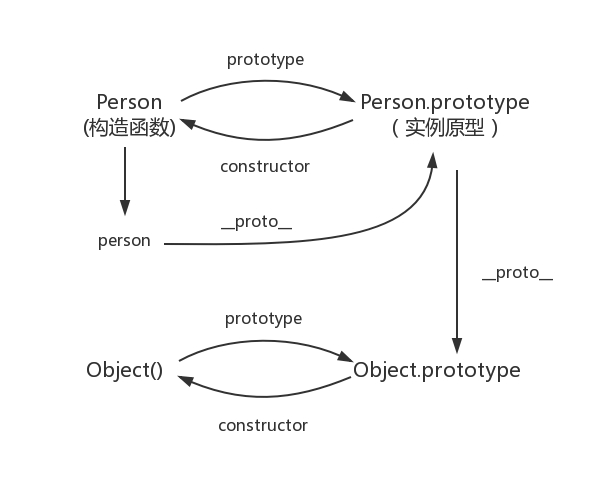
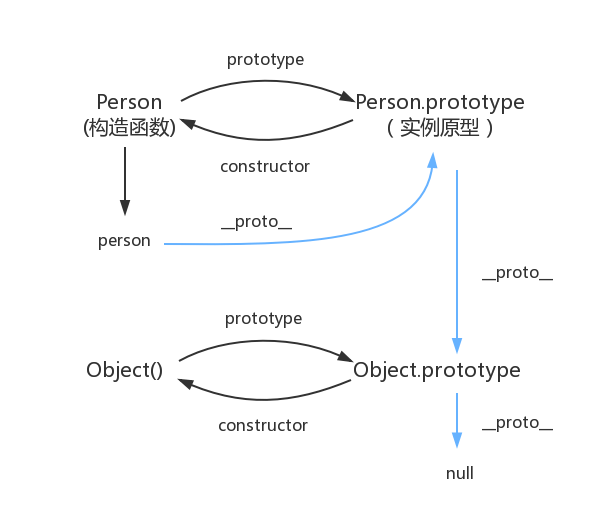
var person = newPerson(); person.name = 'name of this person'; console.log(person.name) // name of this person
delete person.name; console.log(person.name) // name
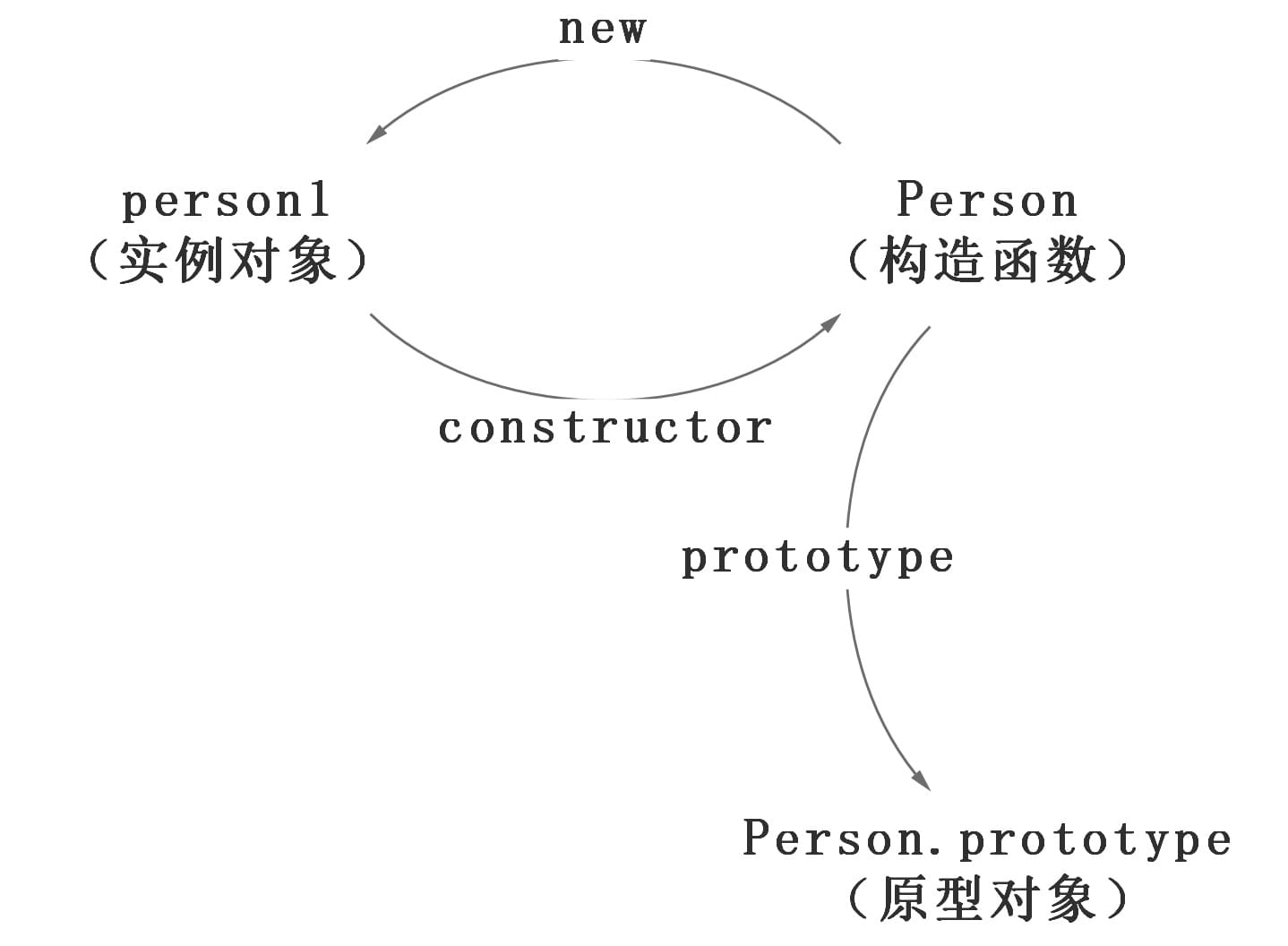
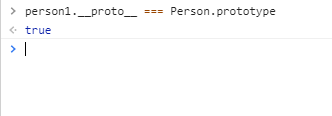
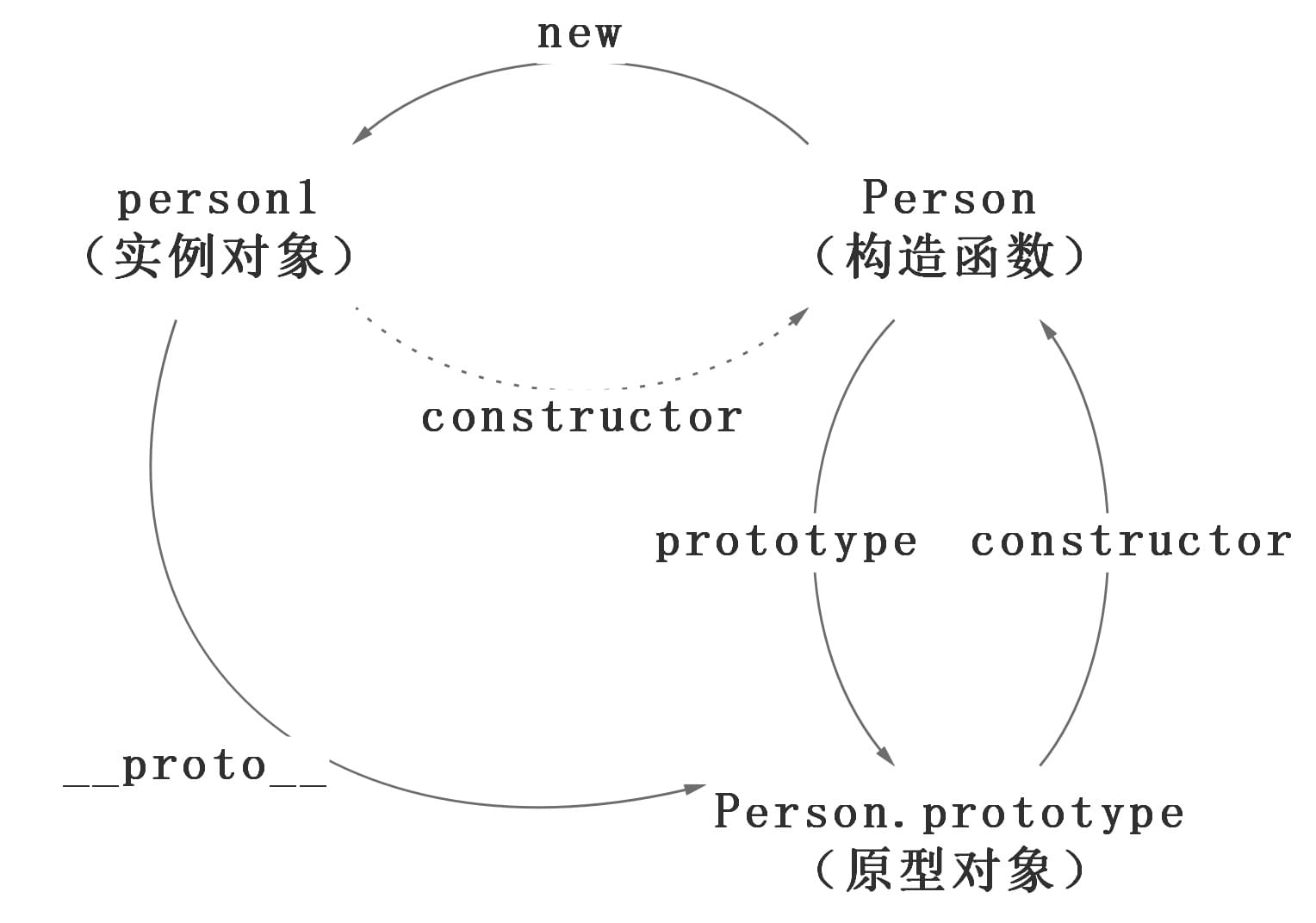
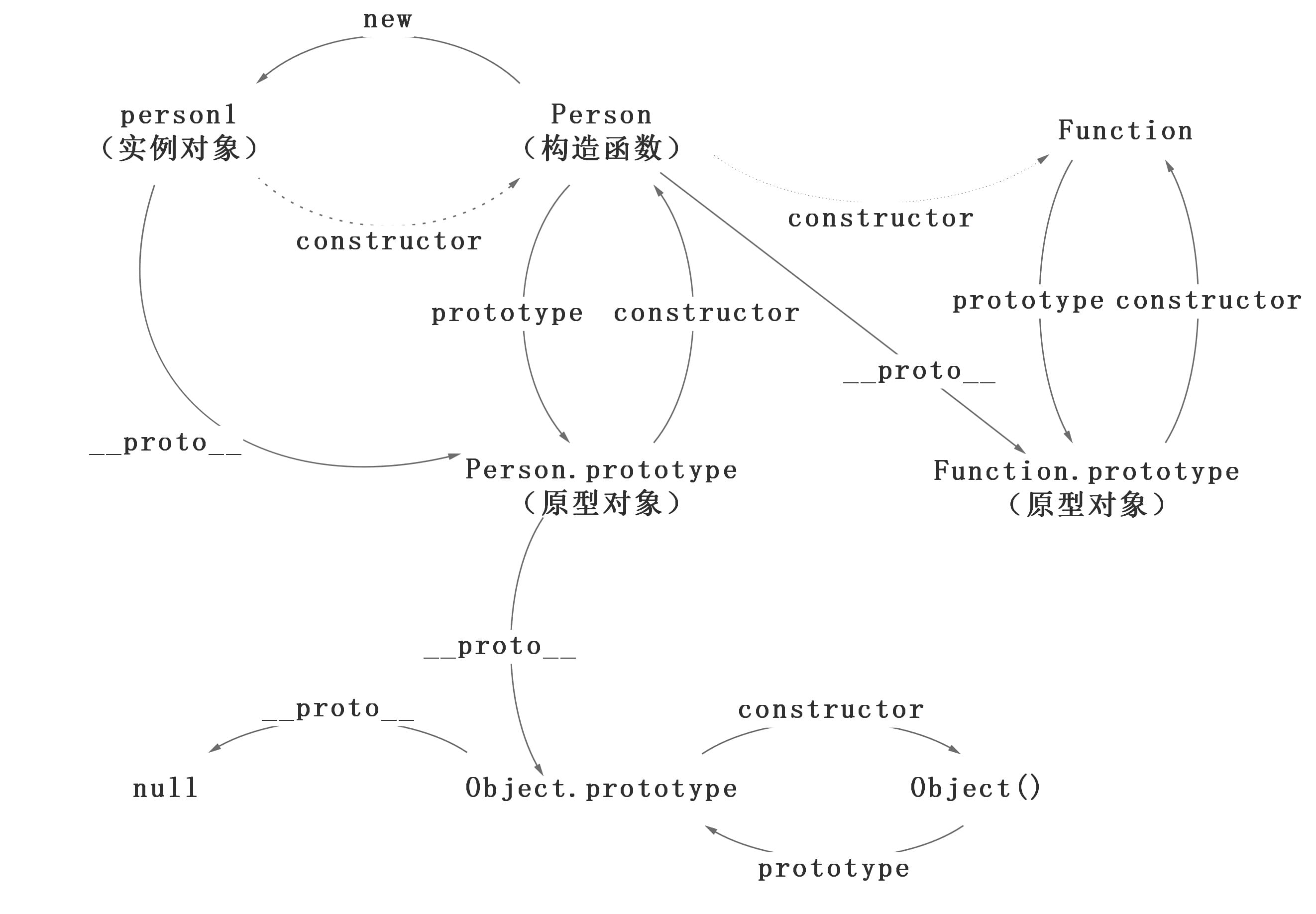
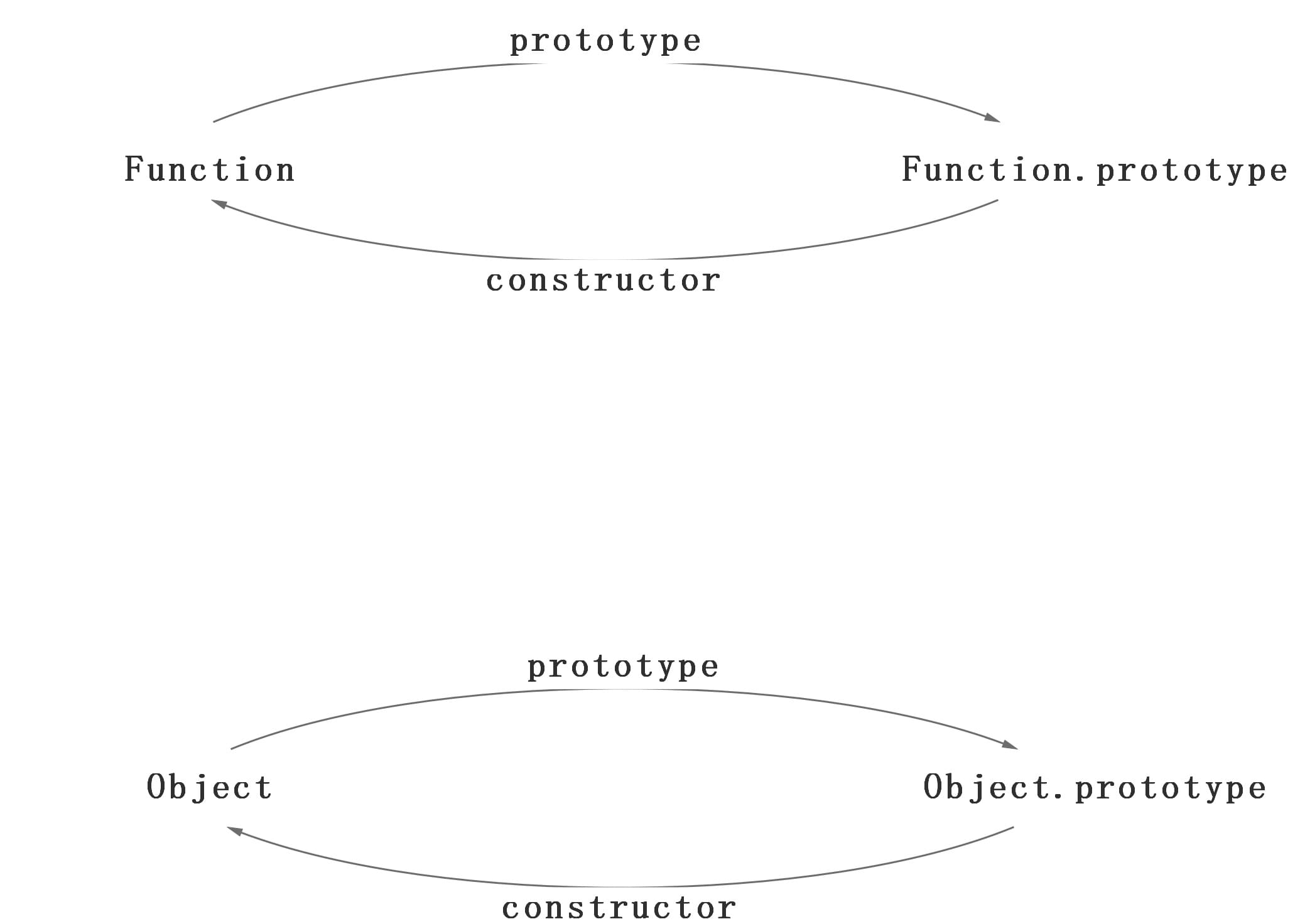
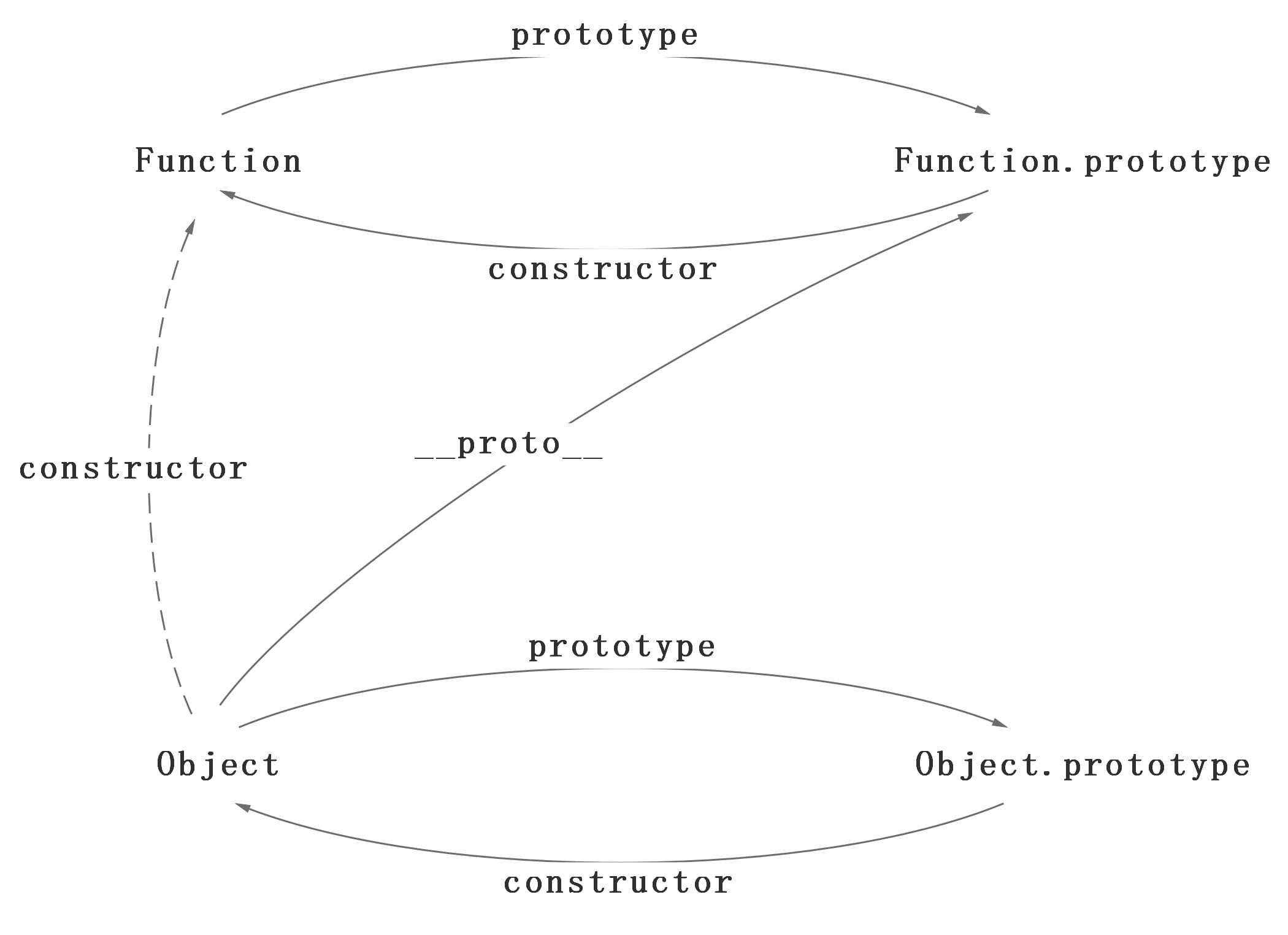
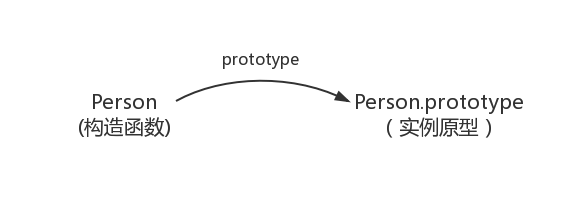
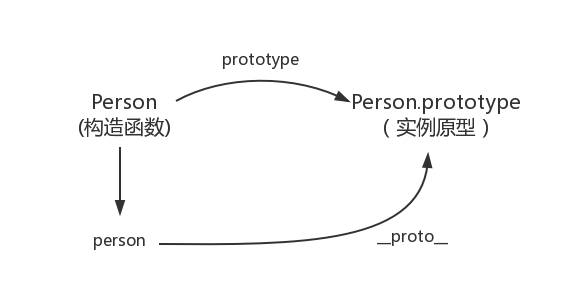
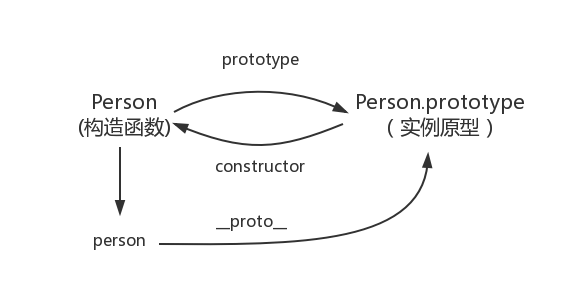
在这个例子中,我们设置了person的name属性,所以我们可以读取到为’name of this person’,当我们删除了person的name属性时,读取person.name,从person中找不到就会从person的原型也就是person.__proto__ == Person.prototype中查找,幸运的是我们找到了为’name’,但是万一还没有找到呢?原型的原型又是什么呢?
在前面,我们已经讲了原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是
1 2 3 4
var obj = newObject(); obj.name = 'name' console.log(obj.name) // name
刚开始,笔者在页面上用jQuery的$.post方法发送一个请求给服务器,然后服务器根据这个参数再生成相应的一个文件流返回给客户端。但是,在$.post方法的回调函数中,只能处理xml, json, script, or html类型,对返回的文件流却没办法弹出对话框让用户下载了。经过百度,看到了很多人采用隐藏form提交的方式,再用response来推就可以。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
functionexportRecord(ajaxData) { var form = $("<form>"); form.attr('style', 'display:none'); form.attr('target', ''); form.attr('method', ajaxData.method); //请求方式 form.attr('action', ajaxData.url);//请求地址 var input1 = $('<input>');//将你请求的数据模仿成一个input表单 input1.attr('type', 'hidden'); input1.attr('name', '');//该输入框的name input1.attr('value', '');//该输入框的值value $('body').append(form); form.append(input1); form.submit(); form.remove(); }
var person = {'name':'ace','age':20}, person1 = {'name':'john','age':21}; var doTemplate = doT.template($('#templ1').html()); $('body').html(doTemplate(person)+doTemplate(person1));
var dataEval = {"name":"ace","age":20,"interests":"basketball","email":"ace@ly.com","phone":"110"}; var evalText = doT.template($("#templ2").html()); $('body').html(evalText(dataEval));
let connection = mysql.createConnection({ // 其他配置 multipleStatements: true, });
然后我们就可以使用多语句查询了。
1 2 3 4 5 6 7 8 9 10 11
connection.query( { sql: `select * from book where username = ?; select * from book where username = ?;`, }, ['ace','xyf'], function(err, rows, fields) { if (err) throw err; console.log('The solution is: ', rows); } );
var mysql = require('mysql'); // 连接数据库的配置 var connection = mysql.createConnection({ // 主机名称,一般是本机 host: 'localhost', // 数据库的端口号,如果不设置,默认是3306 port: 3306 // 创建数据库时设置用户名 user: 'xyf', // 创建数据库时设置的密码 password: 'xyf', // 创建的数据库 database: 'xyf_db' }); // 与数据库建立连接 connection.connect(); // 查询数据库 connection.query('SELECT 1 + 1 AS solution', function(err, rows, fields) { if (err) throw err; console.log('The solution is: ', rows[0].solution); }); // 关闭连接 connection.end();
运行程序,如果显示“The solution is: 2”,那么整个连接查询是成功的;如果不成功,读者可以根据打印的错误信息提示来修改。 在查询完数据库后,需要通过end()函数将连接关闭。如果连接一直打开,首先会浪费不必要的系统资源;其次,数据库的连接数量有限制,如果达到上限时,会出现后续连接不上报错的情况。
var mysql = require('mysql'); var connection = mysql.createConnection(...); connection.query('SELECT 1 + 1 AS solution', function(err, rows, fields) { if (err) throw err; console.log('The solution is: ', rows[0].solution); }); connection.end();
# Description: # Tells the weather # # Configuration: # HUBOT_WEATHER_API_URL - Optional openweathermap.orgAPI endpoint to use # # Commands: # weather in <location> - Tells about the weather in given location # # Author: # Corner
module.exports = (robot) -> robot.catchAll (res) -> res.send"Sorry My Master,I do not know what you are saying"
四、插件
虽然我们写了很多的脚本,但是有的功能已经有现成的,可以直接使用。
自带插件
Hubot自带了几个插件,让我们来看一下。
hubot-pugme
这个插件有两个命令,一个是hubot pug me,另一个是hubot pug bomb [number]。 输入第一个命令看到出现一个链接,在浏览器中打开我们看到了一只可爱的哈巴狗,输入第二个链接,我们把[number]改成随意的一个数字6,我们看到出来6张照片,打开是6张哈巴狗的照片,没错,这个插件就是给你看狗狗的(难道是狗狗爱好者做的?)。 我顿时就忍不住吐槽了,居然还标榜自己是最重要的Hubot插件(Pugme is the most important hubot script),简直鸡肋啊。
hubot-google-images
这个插件有两个命令,一个是hubot image me,另一个是hubot animate me。 官网解释它是用来搜索图片地址的,那么就让我们用官网的例子来尝试一下吧jarvis image me bananas。 很遗憾的是Hubot提醒我这个谷歌的图片搜索引擎不能用了,要设置自定义的引擎。再看了一下官方的文档,这个谷歌图片搜索引擎还要注册,并且每天只能免费搜索一百次,超过了还要收费,有点坑啊。
hubot-maps
这个插件看样子是地图插件,看了一下官方说明,也有两个命令hubot map me和hubot direction me。抱着希望再次尝试了一下jarvis map me wuxi,幸运的是结果出来了,是一个地图的地址,再看了一下是谷歌地图的地址,那不用说了,绝壁要科学上网了。
var a=10; functionshow(){ console.log('a:'+a); //a:10 var b=2; console.log('inside b:'+b); //inside b:2 } show(); console.log('outside b:'+b); //b is no defined
var name = "The Window"; var object = { name : "My Object", getNameFunc : function(){ returnfunction(){ returnthis.name; }; } }; var temp=object.getNameFunc(); console.log(temp()); //The Window
var name = "The Window"; var object = { name : "My Object", getNameFunc : function(){ var that = this; returnfunction(){ return that.name; }; } }; var temp=object.getNameFunc(); console.log(temp()); //My Object
或者这样改造,使用bind方法,将temp函数的作用域绑定到object上。
1 2 3 4 5 6 7 8 9 10 11 12
var name = "The Window"; var object = { name : "My Object", getNameFunc : function(){ var that = this; returnfunction(){ return that.name; }; } }; var temp=object.getNameFunc().bind(object); console.log(temp()); //My Object
闭包不仅能够返回一个函数,还能够返回其他类型的数据,比如下面的代码返回了一个数组对象。
1 2 3 4 5 6 7 8 9 10 11 12 13
functioncreateFunctions(){ var result = newArray(); for (var i=0; i < 10; i++){ result[i] = function(){ return i; }; } return result; } var funcs = createFunctions(); for (var i=0; i < funcs.length; i++){ console.log(funcs[i]()); //10个10 }